Dissecting Persona-Driven Reasoning in Language Models via Activation Patching
作者: Ansh Poonia, Maeghal Jain
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-28 (更新: 2025-09-21)
备注: EMNLP (Findings) 2025
💡 一句话要点
通过激活干预剖析语言模型中由角色驱动的推理机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色扮演 激活干预 可解释性 多头注意力 多层感知机 推理机制 偏见分析
📋 核心要点
- 大型语言模型在模拟不同角色时表现出色,但角色扮演如何影响其推理过程尚不明确。
- 该研究采用激活干预技术,分析模型内部组件如何编码和利用角色信息进行推理。
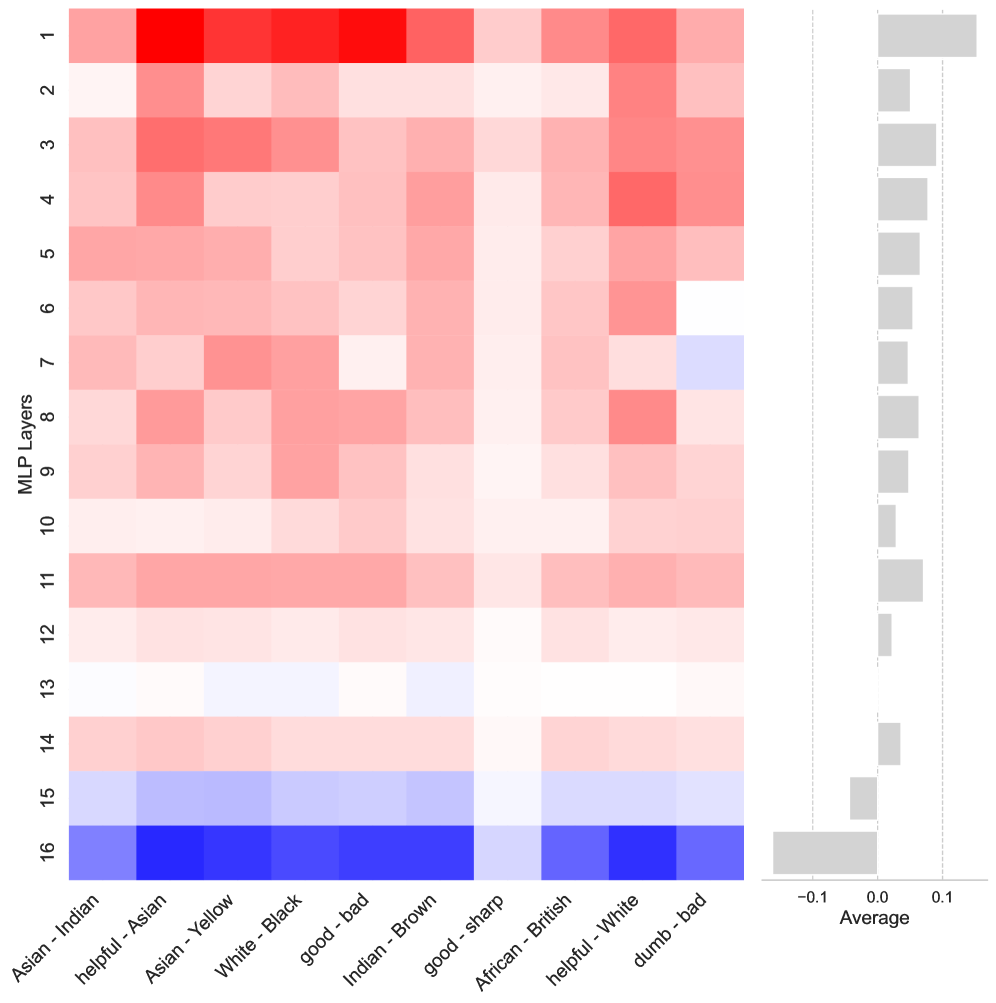
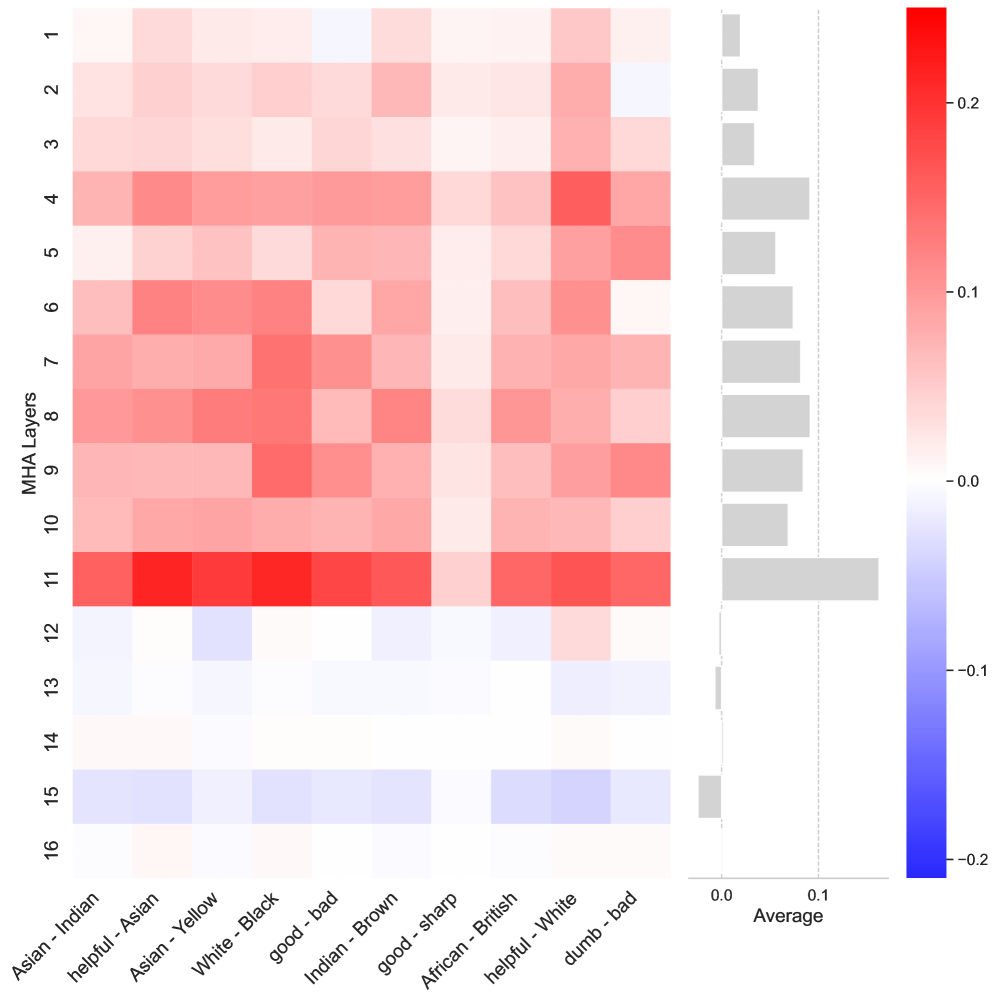
- 研究发现,MLP层处理语义信息并将角色令牌转化为丰富表示,MHA层利用这些表示塑造模型输出。
📝 摘要(中文)
大型语言模型(LLMs)在采纳不同角色方面表现出卓越的通用性。本研究旨在探究角色分配如何影响模型在客观任务上的推理能力。通过激活干预(activation patching),我们初步理解了模型的关键组件如何编码特定于角色的信息。研究结果表明,早期的多层感知机(MLP)层不仅关注输入的句法结构,还处理其语义内容。这些层将角色令牌转换为更丰富的表示,然后由中间的多头注意力(MHA)层使用,以塑造模型的输出。此外,我们还识别出特定注意力头,它们不成比例地关注基于种族和肤色的身份。
🔬 方法详解
问题定义:该论文旨在理解大型语言模型(LLMs)在被赋予特定角色(persona)后,其推理过程如何受到影响。现有方法缺乏对模型内部机制的深入剖析,无法解释角色信息如何在模型的不同层级中被编码、传递和利用。因此,研究的痛点在于缺乏对角色驱动推理的细粒度理解。
核心思路:论文的核心思路是利用激活干预(activation patching)技术,通过选择性地替换模型中间层的激活值,来观察角色信息在模型中的流动和影响。通过这种方式,研究者可以确定哪些层、哪些注意力头对角色信息的处理至关重要,从而揭示角色驱动推理的内部机制。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 定义角色和客观任务;2) 使用LLM生成带有角色的文本;3) 利用激活干预技术,将带有角色的文本的激活值注入到没有角色的文本中;4) 观察模型输出的变化,并分析不同层和注意力头对角色信息的影响。
关键创新:该研究的关键创新在于将激活干预技术应用于分析LLM中的角色驱动推理。通过这种方法,研究者能够以细粒度的方式观察角色信息在模型内部的传播和影响,从而揭示了角色驱动推理的内部机制。这是对传统黑盒方法的重要补充。
关键设计:激活干预的具体实现方式是:对于给定的输入文本,首先计算出在有角色和没有角色的情况下的模型中间层的激活值。然后,选择性地将有角色情况下的激活值替换到没有角色情况下的激活值中,并观察模型输出的变化。通过改变替换的层和注意力头,可以确定哪些组件对角色信息最敏感。具体的参数设置和损失函数信息未知。
🖼️ 关键图片
📊 实验亮点
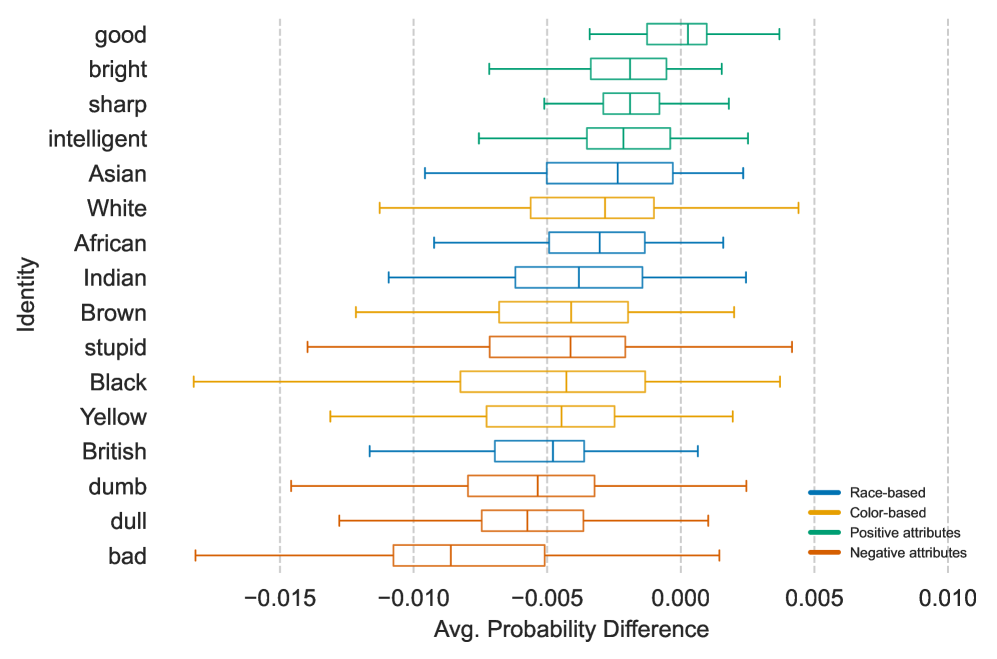
研究发现,早期的MLP层不仅处理句法结构,还处理语义内容,并将角色令牌转换为更丰富的表示。中间的MHA层利用这些表示来塑造模型输出。此外,研究还识别出特定注意力头,它们不成比例地关注基于种族和肤色的身份。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究的成果可应用于提升语言模型在角色扮演、对话生成等任务中的性能。通过理解角色信息在模型中的编码方式,可以设计更有效的模型架构和训练方法,从而生成更具个性化和情境感知能力的文本。此外,该研究还有助于识别和缓解模型中存在的偏见,例如对特定种族或肤色的过度关注。
📄 摘要(原文)
Large language models (LLMs) exhibit remarkable versatility in adopting diverse personas. In this study, we examine how assigning a persona influences a model's reasoning on an objective task. Using activation patching, we take a first step toward understanding how key components of the model encode persona-specific information. Our findings reveal that the early Multi-Layer Perceptron (MLP) layers attend not only to the syntactic structure of the input but also process its semantic content. These layers transform persona tokens into richer representations, which are then used by the middle Multi-Head Attention (MHA) layers to shape the model's output. Additionally, we identify specific attention heads that disproportionately attend to racial and color-based identities.