First Hallucination Tokens Are Different from Conditional Ones
作者: Jakob Snel, Seong Joon Oh
分类: cs.LG, cs.AI
发布日期: 2025-07-28 (更新: 2025-10-06)
备注: 4.5 pages, 3 figures, Dataset, Knowledge Paper, Hallucination, Trustworthiness
🔗 代码/项目: GITHUB
💡 一句话要点
揭示LLM幻觉Token分布特性:首个幻觉Token更易检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 Token级别分析 RAGTruth语料库 可信度 自然语言处理 LLM安全 错误检测
📋 核心要点
- 现有幻觉检测方法主要集中在响应或跨度层面,缺乏对token级别幻觉信号分布的细致研究。
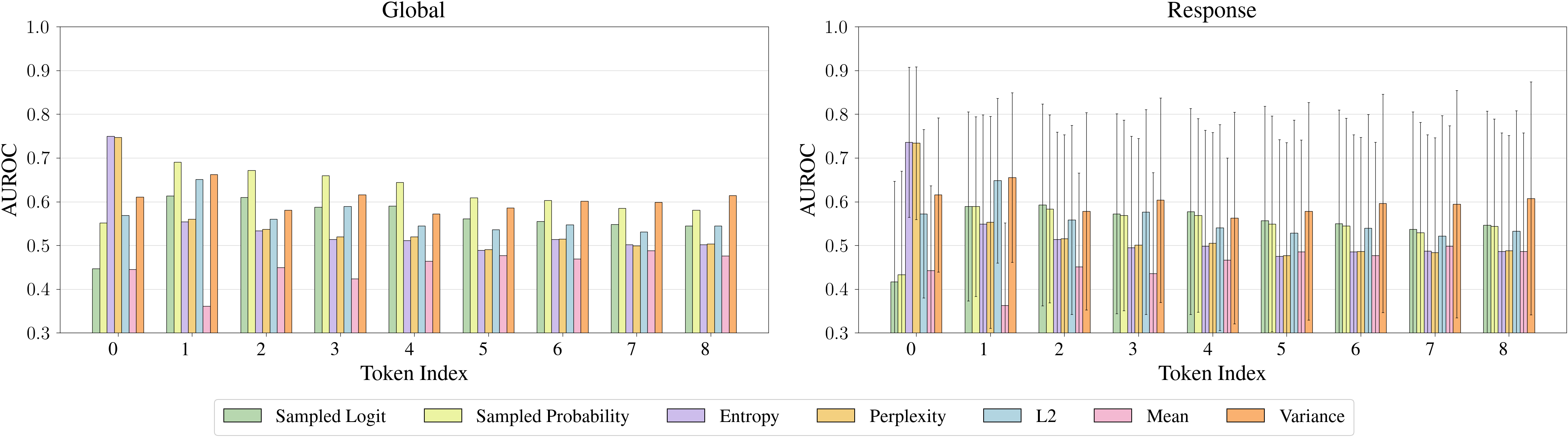
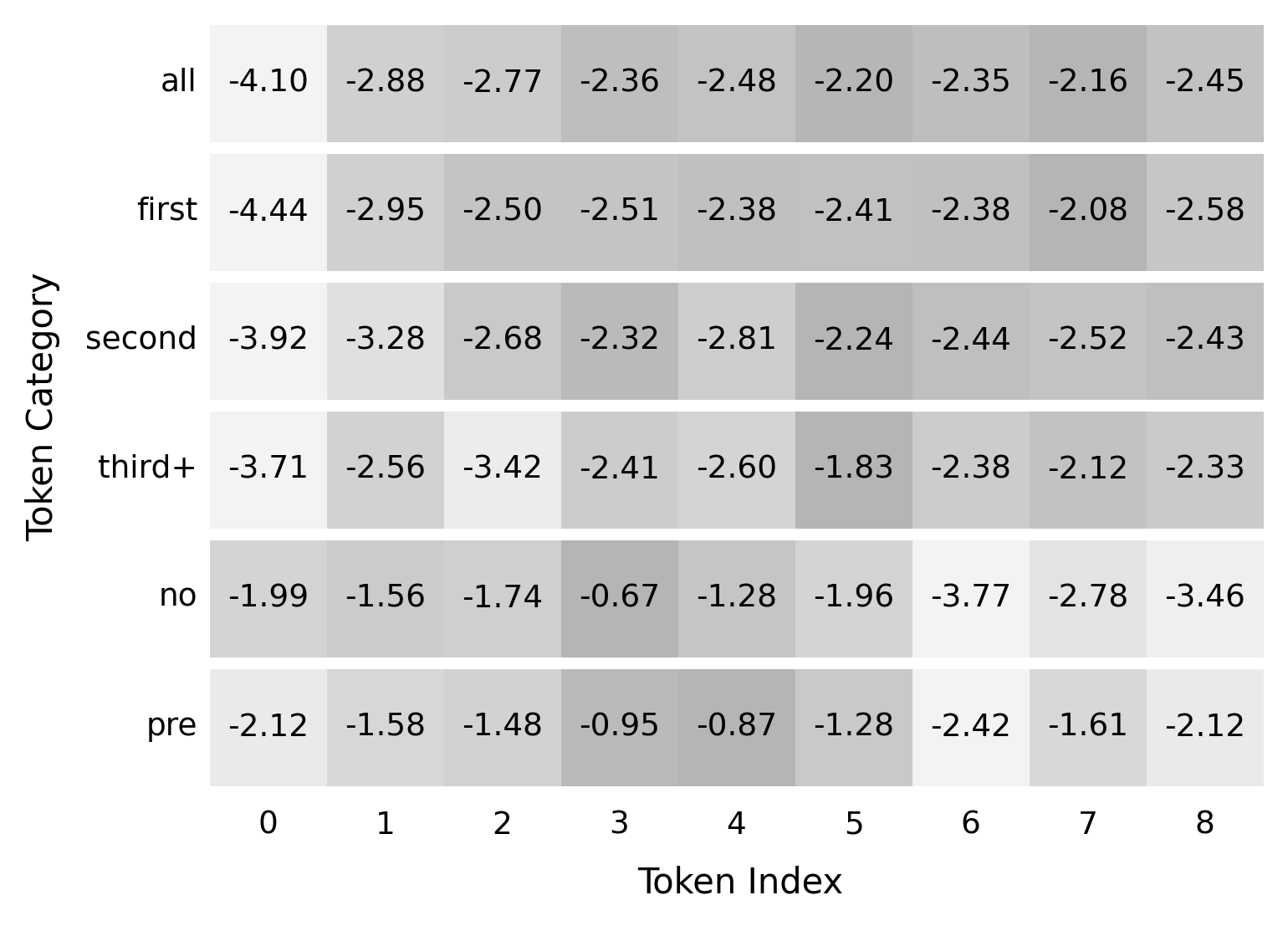
- 该研究发现,在幻觉token序列中,第一个token的幻觉信号更强,更容易被检测。
- 实验结果表明,这一特性在不同LLM模型中具有普遍性,为token级别幻觉检测提供了新思路。
📝 摘要(中文)
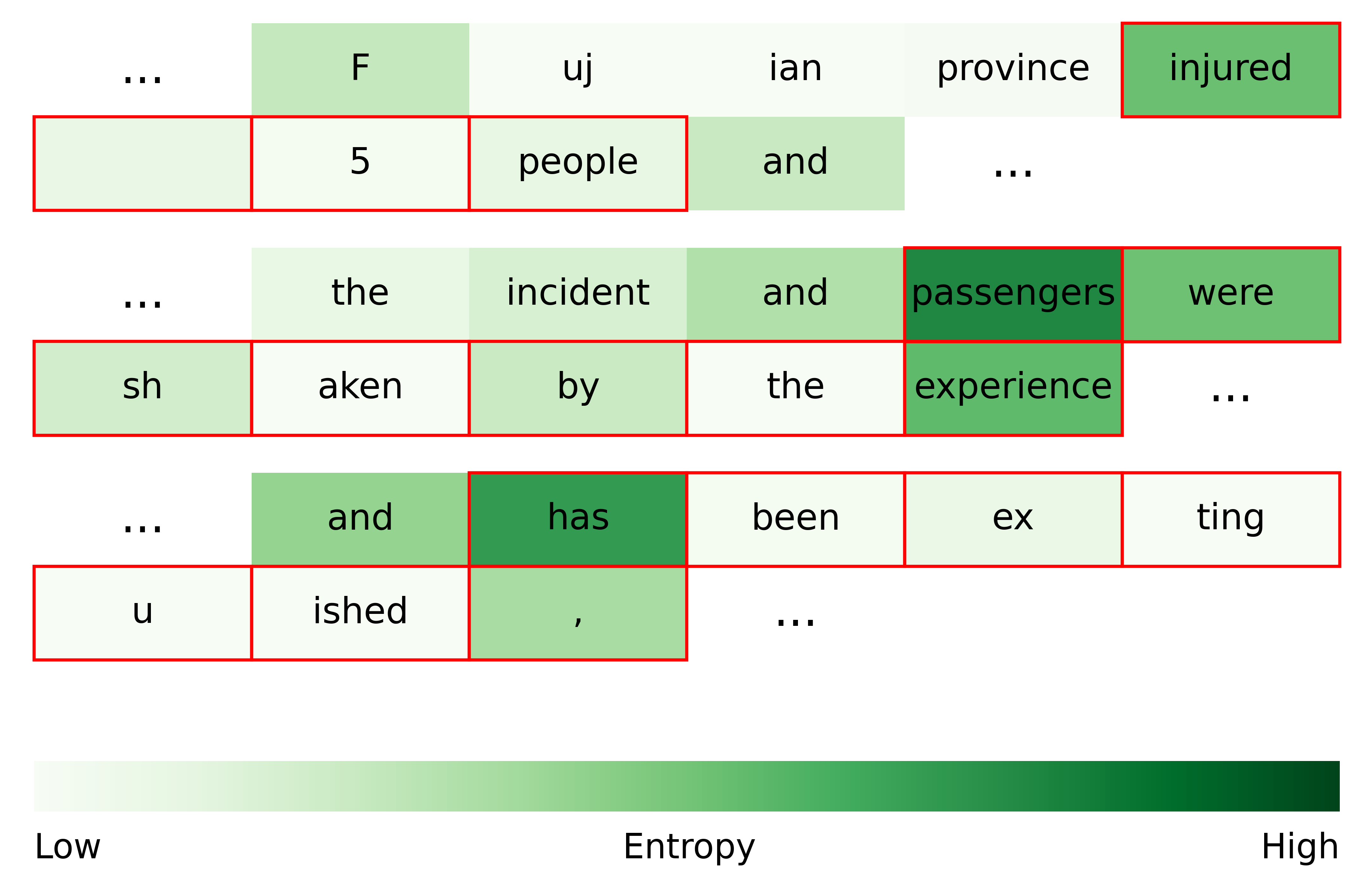
大型语言模型(LLM)的幻觉问题是确保模型可信度的关键挑战。现有方法主要在响应或跨度层面检测幻觉,而最近的研究开始探索token级别的检测,以实现更细粒度的干预。然而,幻觉token序列中幻觉信号的分布特性仍未被充分研究。本文利用RAGTruth语料库中的token级别标注,发现第一个幻觉token比后续的token更容易被检测。这种结构性特征在不同模型中均成立,表明第一个幻觉token在token级别幻觉检测中起着关键作用。代码已开源。
🔬 方法详解
问题定义:大型语言模型(LLM)的幻觉问题严重影响了其可靠性和应用。现有的幻觉检测方法,如在响应或跨度层面进行检测,粒度较粗,难以进行精细干预。因此,如何在token级别准确检测幻觉成为一个重要问题。
核心思路:该论文的核心思路是研究幻觉token序列中幻觉信号的分布特性,特别是关注第一个幻觉token与其他幻觉token的区别。通过分析RAGTruth语料库,发现第一个幻觉token具有更强的可检测性,从而为token级别的幻觉检测提供新的线索。这种思路基于一个假设:幻觉的产生可能存在一个“起始”阶段,该阶段的信号更明显。
技术框架:该研究主要依赖于对现有数据集(RAGTruth)的分析。具体流程包括:1) 从RAGTruth语料库中提取token级别的幻觉标注信息;2) 分析第一个幻觉token与其他幻觉token的特征差异;3) 在不同LLM模型上验证该差异的普遍性。没有提出新的模型架构或训练方法,而是侧重于对现有数据的分析和理解。
关键创新:该研究最重要的创新点在于发现了幻觉token序列中第一个token的特殊性,即其具有更强的可检测性。这与以往研究主要关注整个响应或跨度级别的幻觉检测不同,为token级别的幻觉检测提供了新的视角和方向。
关键设计:该研究的关键设计在于选择RAGTruth语料库作为分析对象,该语料库提供了token级别的幻觉标注,为研究提供了必要的数据基础。此外,通过在多个LLM模型上验证,确保了结论的普遍性。没有涉及具体的参数设置、损失函数或网络结构的设计,因为该研究主要侧重于数据分析和特征发现。
🖼️ 关键图片
📊 实验亮点
该研究通过分析RAGTruth语料库,发现第一个幻觉token比后续的token更容易被检测。这一结论在多个LLM模型中得到验证,表明其具有普遍性。虽然论文没有给出具体的性能数据,但其发现为token级别幻觉检测提供了一个重要的研究方向。
🎯 应用场景
该研究成果可应用于提升LLM的可靠性和安全性。通过优先检测和干预第一个幻觉token,可以更有效地抑制幻觉的产生,提高LLM生成内容的质量。此外,该发现还可以用于开发更精细的幻觉检测工具和算法,应用于问答系统、文本生成等领域。
📄 摘要(原文)
Large Language Models (LLMs) hallucinate, and detecting these cases is key to ensuring trust. While many approaches address hallucination detection at the response or span level, recent work explores token-level detection, enabling more fine-grained intervention. However, the distribution of hallucination signal across sequences of hallucinated tokens remains unexplored. We leverage token-level annotations from the RAGTruth corpus and find that the first hallucinated token is far more detectable than later ones. This structural property holds across models, suggesting that first hallucination tokens play a key role in token-level hallucination detection. Our code is available at https://github.com/jakobsnl/RAGTruth_Xtended.