Salsa as a Nonverbal Embodied Language -- The CoMPAS3D Dataset and Benchmarks
作者: Bermet Burkanova, Payam Jome Yazdian, Chuxuan Zhang, Trinity Evans, Paige Tuttösí, Angelica Lim
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2025-07-25
备注: https://rosielab.github.io/compas3d
💡 一句话要点
提出CoMPAS3D数据集与基准,用于评估社交互动和创造性人形运动生成中的Salsa舞蹈AI。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 社交互动 运动生成 Salsa舞蹈 动作捕捉
📋 核心要点
- 现有AI系统在基于文本或语音的交互方面表现出色,但缺乏对具身运动、时机和身体协调等非语言交流的建模能力。
- 论文提出了CoMPAS3D数据集,包含大量不同水平舞者的Salsa舞蹈数据,并提供细粒度的专家注释,用于评估交互式人形AI。
- 论文基于CoMPAS3D数据集,提出了领舞/跟舞生成和二重奏生成两个基准任务,并提供了一个多任务SalsaAgent模型作为基线。
📝 摘要(中文)
本文提出了CoMPAS3D数据集,这是一个最大且最多样化的即兴Salsa舞蹈动作捕捉数据集,旨在为交互式、富有表现力的人形AI提供一个具有挑战性的测试平台。该数据集包含18位舞者(包括初学者、中级和专业水平)表演的3小时领舞-跟舞Salsa舞蹈。首次提供了细粒度的Salsa专家注释,涵盖超过2800个动作片段,包括动作类型、组合、执行错误和风格元素。本文将伴侣舞蹈交流与自然语言进行类比,并在CoMPAS3D上评估了两个基准任务:具有熟练程度的领舞或跟舞生成(说话者或听者合成)和二重奏(对话)生成。为了实现与人类进行伴侣舞蹈的长期目标,本文发布了数据集、注释和代码,以及能够执行所有基准任务的多任务SalsaAgent模型,以及其他基线,以鼓励在社交互动具身AI和创造性、富有表现力的人形运动生成方面的研究。
🔬 方法详解
问题定义:现有的人工智能系统在文本和语音交互方面取得了显著进展,但在模拟人类之间复杂的非语言交流,特别是具身运动和身体协调方面仍然存在挑战。现有的数据集和模型难以捕捉到伴侣舞蹈中连续、双向反应和个体差异等关键特征。因此,如何构建能够理解和生成自然、流畅的伴侣舞蹈动作的人形AI是一个亟待解决的问题。
核心思路:本文的核心思路是将伴侣舞蹈类比于自然语言,将领舞者和跟舞者分别视为说话者和听者,舞蹈动作视为语言的表达。通过构建一个包含大量Salsa舞蹈数据的数据集,并提供细粒度的专家注释,可以训练模型学习舞蹈动作的模式和规则,从而实现领舞/跟舞生成和二重奏生成。
技术框架:本文提出的技术框架主要包括以下几个部分:1) CoMPAS3D数据集的构建,包括动作捕捉数据的采集、清洗和标注;2) Salsa专家注释的生成,包括动作类型、组合、执行错误和风格元素的标注;3) 基准任务的定义,包括领舞/跟舞生成和二重奏生成;4) 多任务SalsaAgent模型的构建,该模型能够执行所有基准任务。
关键创新:本文最重要的技术创新点在于构建了CoMPAS3D数据集,这是目前最大且最多样化的即兴Salsa舞蹈动作捕捉数据集。该数据集不仅包含大量的数据,而且提供了细粒度的专家注释,为研究人员提供了宝贵的资源。此外,本文还提出了将伴侣舞蹈类比于自然语言的思路,为研究人形AI的非语言交流提供了一个新的视角。
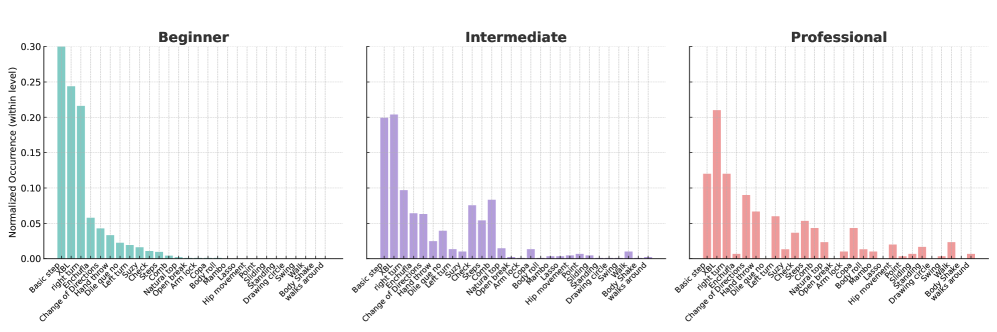
关键设计:CoMPAS3D数据集包含18位舞者表演的3小时Salsa舞蹈数据,涵盖初学者、中级和专业水平。数据集中的每个动作片段都经过Salsa专家的标注,包括动作类型、组合、执行错误和风格元素。多任务SalsaAgent模型采用Transformer架构,能够同时执行领舞/跟舞生成和二重奏生成任务。模型的训练采用多任务学习的方式,可以提高模型的泛化能力和鲁棒性。
🖼️ 关键图片


📊 实验亮点
论文构建了包含超过2800个动作片段的CoMPAS3D数据集,并提供了细粒度的Salsa专家注释。通过在CoMPAS3D数据集上进行实验,验证了多任务SalsaAgent模型在领舞/跟舞生成和二重奏生成任务上的有效性。虽然具体的性能数据和提升幅度未在摘要中明确给出,但该模型作为基线,为未来的研究提供了参考。
🎯 应用场景
该研究成果可应用于开发能够与人类进行安全、创造性舞蹈的人形机器人,例如,在娱乐、康复和教育领域。此外,该研究还可以促进对人类非语言交流的理解,并为开发更自然、更具表现力的人机交互系统提供新的思路。未来,该研究有望推动社交互动具身AI和创造性人形运动生成领域的发展。
📄 摘要(原文)
Imagine a humanoid that can safely and creatively dance with a human, adapting to its partner's proficiency, using haptic signaling as a primary form of communication. While today's AI systems excel at text or voice-based interaction with large language models, human communication extends far beyond text-it includes embodied movement, timing, and physical coordination. Modeling coupled interaction between two agents poses a formidable challenge: it is continuous, bidirectionally reactive, and shaped by individual variation. We present CoMPAS3D, the largest and most diverse motion capture dataset of improvised salsa dancing, designed as a challenging testbed for interactive, expressive humanoid AI. The dataset includes 3 hours of leader-follower salsa dances performed by 18 dancers spanning beginner, intermediate, and professional skill levels. For the first time, we provide fine-grained salsa expert annotations, covering over 2,800 move segments, including move types, combinations, execution errors and stylistic elements. We draw analogies between partner dance communication and natural language, evaluating CoMPAS3D on two benchmark tasks for synthetic humans that parallel key problems in spoken language and dialogue processing: leader or follower generation with proficiency levels (speaker or listener synthesis), and duet (conversation) generation. Towards a long-term goal of partner dance with humans, we release the dataset, annotations, and code, along with a multitask SalsaAgent model capable of performing all benchmark tasks, alongside additional baselines to encourage research in socially interactive embodied AI and creative, expressive humanoid motion generation.