Advancing Event Forecasting through Massive Training of Large Language Models: Challenges, Solutions, and Broader Impacts
作者: Sang-Woo Lee, Sohee Yang, Donghyun Kwak, Noah Y. Siegel
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-25
💡 一句话要点
通过大规模训练大型语言模型提升事件预测能力:挑战、解决方案与广泛影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事件预测 大型语言模型 超预测者 强化学习 数据获取 知识截断 噪声数据
📋 核心要点
- 现有事件预测方法在利用大型语言模型时面临噪声数据、知识时效性和奖励信号不足等挑战。
- 论文提出通过假想事件贝叶斯网络、利用反事实事件和辅助奖励信号等方法来缓解训练难题。
- 建议积极利用市场、公共和网络爬取等多种数据源,支持大规模训练和评估,提升预测性能。
📝 摘要(中文)
本文探讨了利用大型语言模型(LLM)进行事件预测的研究进展。早期研究因方法问题对LLM在事件预测中的应用产生质疑,但近期改进评估方法的研究表明,最先进的LLM正逐渐达到超预测者水平,并且强化学习也被报道可以改善未来预测。此外,推理模型和深度研究风格模型的成功表明,能够显著提高预测性能的技术已经出现。基于这些积极趋势,本文认为现在是进行大规模训练超预测者水平事件预测LLM研究的适当时机。文章讨论了两个关键研究方向:训练方法和数据获取。针对训练,提出了LLM事件预测训练的三大难题:噪声-稀疏性、知识截断和简单奖励结构。并提出了假想事件贝叶斯网络、利用记忆不佳和反事实事件以及辅助奖励信号等相关想法来缓解这些问题。针对数据,建议积极利用市场、公共和爬取数据集来实现大规模训练和评估。最后,阐述了这些技术进步如何使AI能够在更广泛的领域为社会提供预测情报。这篇立场文件提出了有希望的具体路径和考虑因素,以更接近超预测者水平的AI技术,旨在引起研究人员对这些方向的兴趣。
🔬 方法详解
问题定义:现有基于LLM的事件预测方法面临三大痛点:一是训练数据中的噪声和稀疏性问题,导致模型难以准确学习;二是LLM的知识存在截断,无法获取最新的信息;三是简单的奖励结构难以有效引导模型学习复杂的预测逻辑。这些问题限制了LLM在事件预测任务中的性能。
核心思路:论文的核心思路是通过改进训练方法和数据获取策略,克服上述痛点,从而提升LLM在事件预测任务中的性能。具体而言,通过引入假想事件贝叶斯网络来处理噪声和稀疏性问题,利用反事实事件来增强模型的推理能力,并设计辅助奖励信号来更有效地引导模型学习。同时,积极利用各种数据源,扩大训练规模。
技术框架:论文没有提出一个具体的模型架构,而更多的是一种研究思路和方法论。其核心在于如何有效地训练LLM进行事件预测。主要包含两个方面:一是训练方法,包括如何处理噪声、知识截断和奖励信号问题;二是数据获取,包括如何利用各种数据源进行大规模训练和评估。
关键创新:论文的关键创新在于提出了针对LLM事件预测训练的三大难题,并针对性地提出了解决方案。例如,利用假想事件贝叶斯网络来处理噪声和稀疏性问题,利用反事实事件来增强模型的推理能力,并设计辅助奖励信号来更有效地引导模型学习。这些方法为提升LLM在事件预测任务中的性能提供了新的思路。
关键设计:论文没有提供具体的参数设置或网络结构,而是侧重于方法论的指导。关键设计在于如何构建假想事件贝叶斯网络,如何生成和利用反事实事件,以及如何设计有效的辅助奖励信号。这些都需要根据具体的任务和数据进行调整和优化。
🖼️ 关键图片
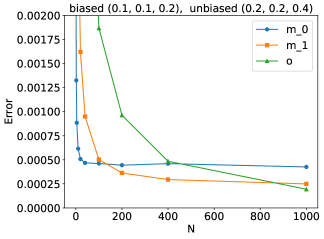
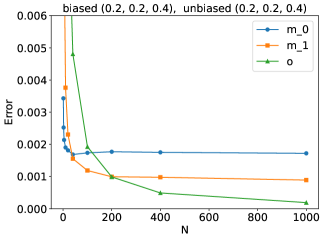
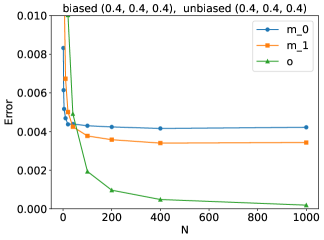
📊 实验亮点
论文是一篇立场性文章,主要提出了研究方向和思路,并没有提供具体的实验结果。文章指出,近期研究表明,最先进的LLM正逐渐达到超预测者水平,并且强化学习也被报道可以改善未来预测。未来的研究方向将集中在如何通过大规模训练和数据获取来进一步提升LLM的事件预测能力。
🎯 应用场景
该研究成果可应用于金融市场预测、政治事件预测、突发公共卫生事件预警等领域,为决策者提供更准确的预测情报,辅助制定更合理的政策和措施。通过提升AI的预测能力,有望在社会各领域发挥重要作用,例如风险管理、资源分配和危机应对。
📄 摘要(原文)
Many recent papers have studied the development of superforecaster-level event forecasting LLMs. While methodological problems with early studies cast doubt on the use of LLMs for event forecasting, recent studies with improved evaluation methods have shown that state-of-the-art LLMs are gradually reaching superforecaster-level performance, and reinforcement learning has also been reported to improve future forecasting. Additionally, the unprecedented success of recent reasoning models and Deep Research-style models suggests that technology capable of greatly improving forecasting performance has been developed. Therefore, based on these positive recent trends, we argue that the time is ripe for research on large-scale training of superforecaster-level event forecasting LLMs. We discuss two key research directions: training methods and data acquisition. For training, we first introduce three difficulties of LLM-based event forecasting training: noisiness-sparsity, knowledge cut-off, and simple reward structure problems. Then, we present related ideas to mitigate these problems: hypothetical event Bayesian networks, utilizing poorly-recalled and counterfactual events, and auxiliary reward signals. For data, we propose aggressive use of market, public, and crawling datasets to enable large-scale training and evaluation. Finally, we explain how these technical advances could enable AI to provide predictive intelligence to society in broader areas. This position paper presents promising specific paths and considerations for getting closer to superforecaster-level AI technology, aiming to call for researchers' interest in these directions.