Short-Form Video Recommendations with Multimodal Embeddings: Addressing Cold-Start and Bias Challenges
作者: Andrii Dzhoha, Katya Mirylenka, Egor Malykh, Marco-Andrea Buchmann, Francesca Catino
分类: cs.LG
发布日期: 2025-07-25 (更新: 2025-09-03)
💡 一句话要点
提出基于多模态嵌入的短视频推荐系统,解决冷启动和偏差挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 短视频推荐 多模态嵌入 冷启动问题 偏差挑战 视觉-语言模型
📋 核心要点
- 短视频推荐面临冷启动、位置偏差和时长偏差等挑战,传统方法难以有效解决。
- 论文提出利用微调的多模态视觉-语言模型构建视频检索系统,克服数据稀疏和偏差问题。
- 在线实验表明,该方法比传统监督学习方法更有效,提升了短视频推荐的性能。
📝 摘要(中文)
近年来,社交媒体用户花费大量时间在短视频平台上。因此,电商等其他领域的成熟平台也开始引入短视频内容,以吸引用户并增加他们在平台上的停留时间。这些体验的成功不仅归功于内容本身,还归功于独特的UI创新:平台主动为用户推荐内容,一次观看一个,而不是提供用户点击的选择列表。这给推荐系统带来了新的挑战,尤其是在启动新的视频体验时。除了有限的交互数据外,沉浸式feed体验由于UI引入了更强的位置偏差,以及在优化观看时长时,模型倾向于选择较短的视频,从而引入了时长偏差。这些问题,以及推荐系统中固有的反馈循环,使得构建有效的解决方案变得困难。本文重点介绍了引入新的短视频体验时面临的挑战,并展示了我们的经验,表明即使有足够的视频交互数据,利用微调的多模态视觉-语言模型构建视频检索系统也可能更有益,以克服这些挑战。与传统的监督学习方法相比,这种方法在我们的电商平台上进行的在线实验中表现出更高的有效性。
🔬 方法详解
问题定义:论文旨在解决电商平台中新推出的短视频推荐体验所面临的冷启动问题以及由UI设计和优化目标带来的位置偏差和时长偏差。传统监督学习方法在数据稀疏的情况下表现不佳,并且容易受到偏差的影响,导致推荐效果不理想。
核心思路:论文的核心思路是利用多模态信息(视觉和语言)来丰富视频的表示,从而缓解冷启动问题。通过预训练的视觉-语言模型,可以学习到视频内容更丰富的语义表示,从而更好地进行视频检索和推荐。同时,通过检索而非直接预测,可以减少模型对位置和时长的依赖。
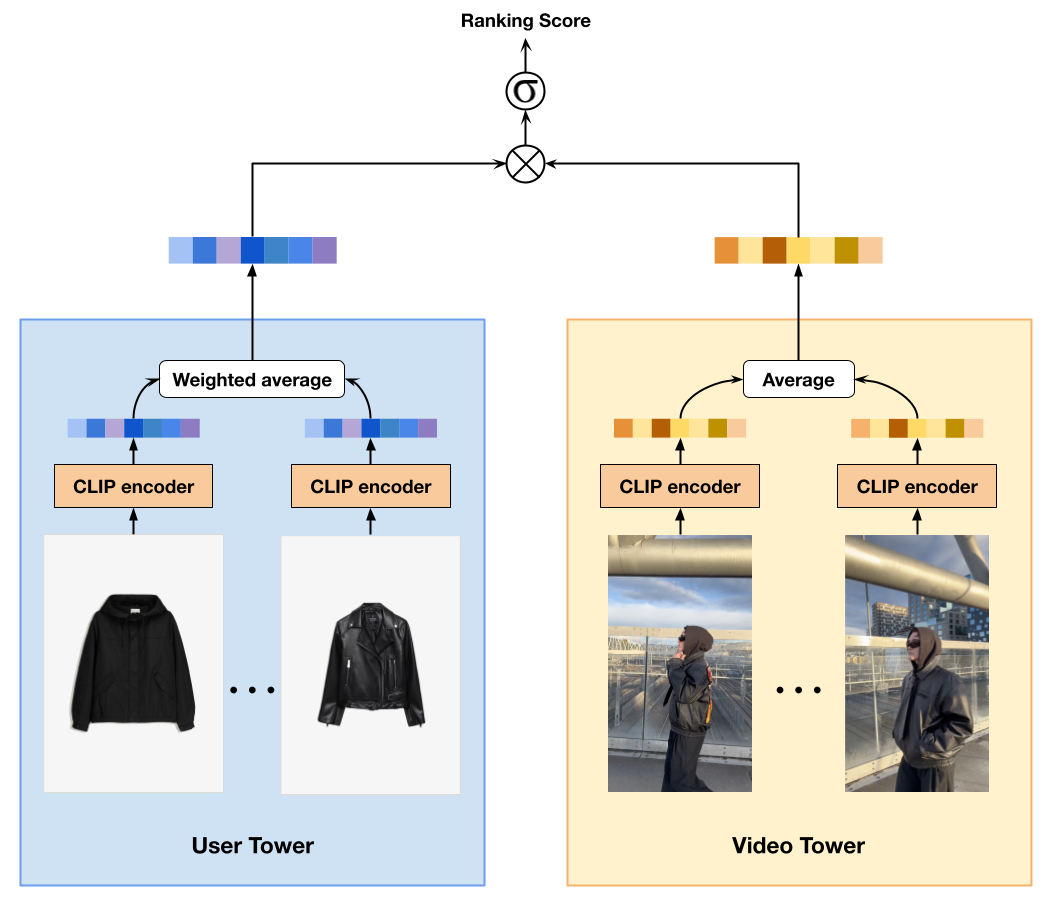
技术框架:整体框架是一个基于多模态嵌入的视频检索系统。首先,使用预训练的视觉-语言模型(例如CLIP)提取视频帧和标题的特征。然后,将这些特征进行融合,得到视频的统一表示。在推荐时,根据用户的历史行为和偏好,生成一个查询向量,然后在视频库中检索与该查询向量最相似的视频。检索到的视频将作为推荐结果呈现给用户。
关键创新:关键创新在于利用预训练的多模态模型来解决短视频推荐中的冷启动和偏差问题。与传统的基于用户行为的推荐方法不同,该方法更加关注视频的内容本身,从而可以在数据稀疏的情况下进行有效的推荐。此外,使用检索而非直接预测的方式,可以减少模型对位置和时长的依赖,从而降低偏差的影响。
关键设计:论文中使用了CLIP模型来提取视频帧和标题的特征。具体来说,对于视频帧,使用CLIP的视觉编码器提取特征;对于标题,使用CLIP的文本编码器提取特征。然后,将两种特征进行拼接或加权平均,得到视频的统一表示。在检索时,使用余弦相似度来衡量查询向量和视频向量之间的相似度。损失函数未知,但推测可能使用了对比学习相关的损失函数,以拉近相似视频的距离,推远不相似视频的距离。
🖼️ 关键图片
📊 实验亮点
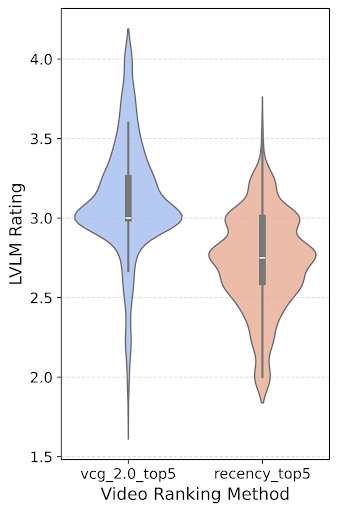
论文通过在线实验验证了所提出方法的有效性。实验结果表明,与传统的监督学习方法相比,基于多模态嵌入的视频检索系统在短视频推荐中表现出更高的有效性。具体的性能数据和提升幅度未知,但结论是该方法能够更好地克服冷启动和偏差挑战。
🎯 应用场景
该研究成果可应用于各种短视频推荐场景,尤其是在电商、新闻资讯等领域,可以有效解决新视频的冷启动问题,提升用户体验和平台活跃度。该方法也可以推广到其他多模态推荐场景,例如图文推荐、音频视频推荐等,具有广泛的应用前景。
📄 摘要(原文)
In recent years, social media users have spent significant amounts of time on short-form video platforms. As a result, established platforms in other domains, such as e-commerce, have begun introducing short-form video content to engage users and increase their time spent on the platform. The success of these experiences is due not only to the content itself but also to a unique UI innovation: instead of offering users a list of choices to click, platforms actively recommend content for users to watch one at a time. This creates new challenges for recommender systems, especially when launching a new video experience. Beyond the limited interaction data, immersive feed experiences introduce stronger position bias due to the UI and duration bias when optimizing for watch-time, as models tend to favor shorter videos. These issues, together with the feedback loop inherent in recommender systems, make it difficult to build effective solutions. In this paper, we highlight the challenges faced when introducing a new short-form video experience and present our experience showing that, even with sufficient video interaction data, it can be more beneficial to leverage a video retrieval system using a fine-tuned multimodal vision-language model to overcome these challenges. This approach demonstrated greater effectiveness compared to conventional supervised learning methods in online experiments conducted on our e-commerce platform.