Doubling Your Data in Minutes: Ultra-fast Tabular Data Generation via LLM-Induced Dependency Graphs
作者: Shuo Yang, Zheyu Zhang, Bardh Prenkaj, Gjergji Kasneci
分类: cs.LG, cs.AI
发布日期: 2025-07-25
💡 一句话要点
SPADA:利用LLM诱导的稀疏依赖图实现超快速表格数据生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据生成 数据增强 大型语言模型 稀疏依赖图 条件归一化流
📋 核心要点
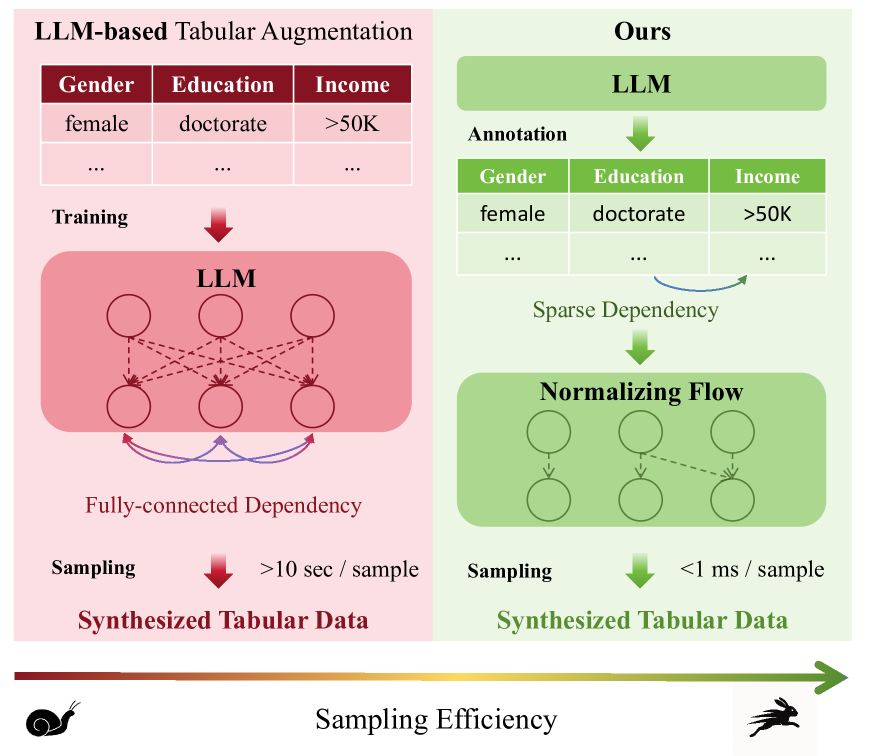
- 现有表格数据增强方法依赖LLM,但其密集依赖建模易引入偏差,且采样计算成本高昂。
- SPADA通过LLM诱导的稀疏依赖图,显式捕获特征间的稀疏关系,降低偏差和计算复杂度。
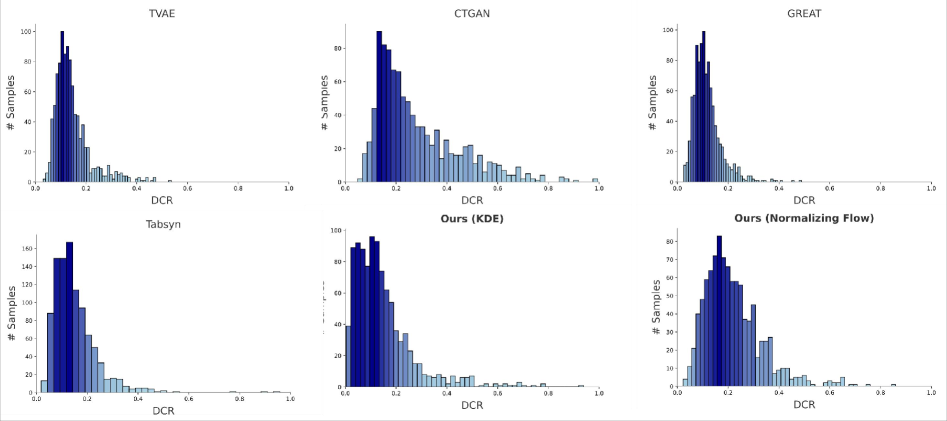
- 实验表明,SPADA在保证数据质量的同时,显著提升了生成速度,约束违反降低4%,加速9500倍。
📝 摘要(中文)
表格数据在各个领域至关重要,但由于隐私问题和收集成本,高质量数据集仍然稀缺。目前的方法采用大型语言模型(LLM)进行表格数据增强,但存在两个主要限制:(1)表格特征之间密集的依赖关系建模可能引入偏差,(2)采样过程计算开销高。为了解决这些问题,我们提出了SPADA(SPArse Dependency-driven Augmentation),这是一个轻量级的生成框架,通过LLM诱导的图显式地捕获稀疏依赖关系。我们将每个特征视为一个节点,并通过遍历图来合成值,仅将每个特征的生成条件限制在其父节点上。我们探索了两种合成策略:一种使用高斯核密度估计的非参数方法,以及一种学习条件密度估计的可逆映射的条件归一化流模型。在四个数据集上的实验表明,与基于扩散的方法相比,SPADA减少了4%的约束违反,并且比基于LLM的基线方法加速了近9500倍。
🔬 方法详解
问题定义:现有基于LLM的表格数据增强方法,由于对表格特征之间进行密集的依赖关系建模,容易引入偏差,导致生成的数据质量下降。同时,LLM的计算复杂度较高,使得数据生成过程耗时过长,难以满足实际应用的需求。
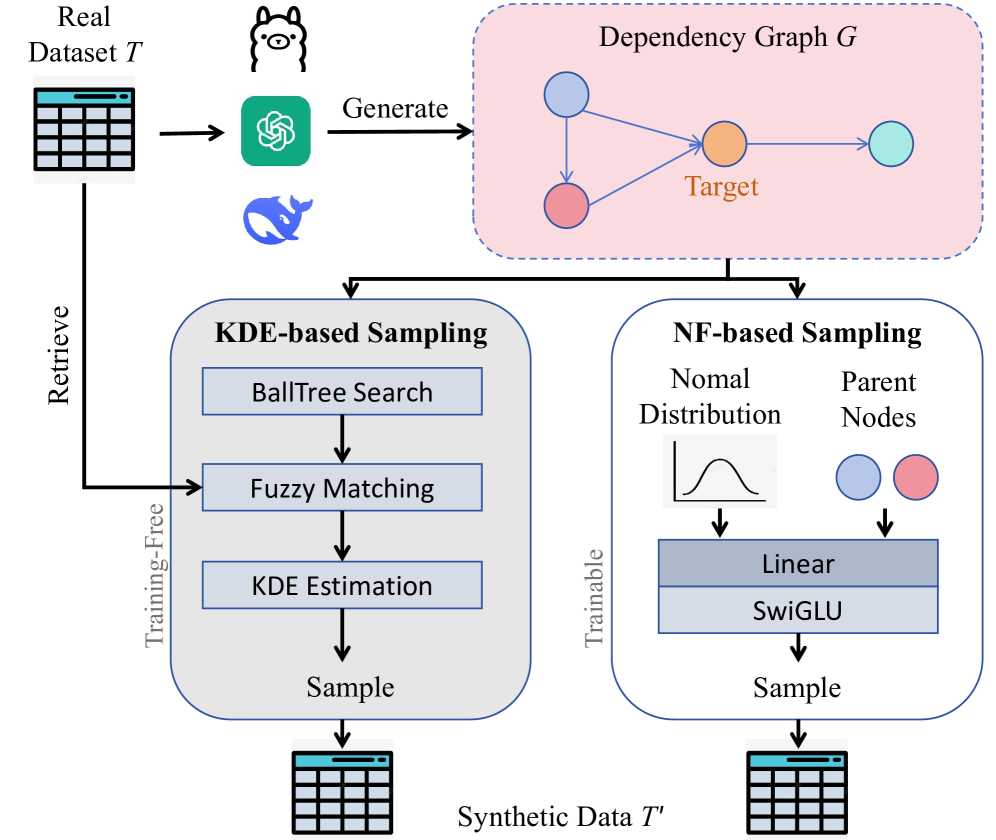
核心思路:SPADA的核心思路是利用LLM来发现表格特征之间的稀疏依赖关系,并构建一个稀疏依赖图。每个特征只依赖于其父节点,从而避免了密集依赖建模带来的偏差。通过稀疏化依赖关系,也显著降低了数据生成过程的计算复杂度。
技术框架:SPADA框架包含以下几个主要步骤:1) 利用LLM分析表格数据的特征,提取特征之间的依赖关系。2) 基于提取的依赖关系构建稀疏依赖图,其中每个节点代表一个特征,边代表特征之间的依赖关系。3) 根据稀疏依赖图,按照拓扑顺序生成每个特征的值。论文探索了两种生成策略:非参数方法(高斯核密度估计)和参数方法(条件归一化流)。
关键创新:SPADA的关键创新在于利用LLM诱导的稀疏依赖图来建模表格特征之间的依赖关系。与现有方法相比,SPADA能够更准确地捕获特征之间的关系,并避免了密集依赖建模带来的偏差。此外,稀疏依赖图也显著降低了数据生成过程的计算复杂度。
关键设计:在构建稀疏依赖图时,论文使用LLM来评估特征之间的依赖强度,并设置一个阈值来过滤掉弱依赖关系。对于非参数方法,论文使用高斯核密度估计来估计每个特征的条件概率分布。对于参数方法,论文使用条件归一化流来学习每个特征的条件概率分布,并使用最大似然估计来训练模型。具体来说,条件归一化流采用了一种可逆神经网络结构,使得可以高效地进行采样和密度估计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SPADA在四个数据集上均取得了显著的性能提升。与基于扩散的方法相比,SPADA减少了4%的约束违反。更重要的是,SPADA比基于LLM的基线方法加速了近9500倍,极大地提高了数据生成的效率。这使得SPADA能够应用于大规模表格数据的生成和增强。
🎯 应用场景
SPADA可应用于各种需要生成或增强表格数据的场景,例如:金融风控、医疗诊断、市场营销等。通过生成高质量的合成数据,可以解决数据稀缺问题,提高模型训练效果,并保护用户隐私。未来,SPADA可以进一步扩展到处理更复杂的表格数据,例如包含缺失值、异常值的数据。
📄 摘要(原文)
Tabular data is critical across diverse domains, yet high-quality datasets remain scarce due to privacy concerns and the cost of collection. Contemporary approaches adopt large language models (LLMs) for tabular augmentation, but exhibit two major limitations: (1) dense dependency modeling among tabular features that can introduce bias, and (2) high computational overhead in sampling. To address these issues, we propose SPADA for SPArse Dependency-driven Augmentation, a lightweight generative framework that explicitly captures sparse dependencies via an LLM-induced graph. We treat each feature as a node and synthesize values by traversing the graph, conditioning each feature solely on its parent nodes. We explore two synthesis strategies: a non-parametric method using Gaussian kernel density estimation, and a conditional normalizing flow model that learns invertible mappings for conditional density estimation. Experiments on four datasets show that SPADA reduces constraint violations by 4% compared to diffusion-based methods and accelerates generation by nearly 9,500 times over LLM-based baselines.