ProGMLP: A Progressive Framework for GNN-to-MLP Knowledge Distillation with Efficient Trade-offs
作者: Weigang Lu, Ziyu Guan, Wei Zhao, Yaming Yang, Yujie Sun, Zheng Liang, Yibing Zhan, Dapeng Tao
分类: cs.LG
发布日期: 2025-07-25
💡 一句话要点
ProGMLP:一种渐进式GNN到MLP知识蒸馏框架,实现高效的精度-成本权衡
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图神经网络 知识蒸馏 多层感知器 模型压缩 渐进式学习 资源受限环境 精度-成本权衡
📋 核心要点
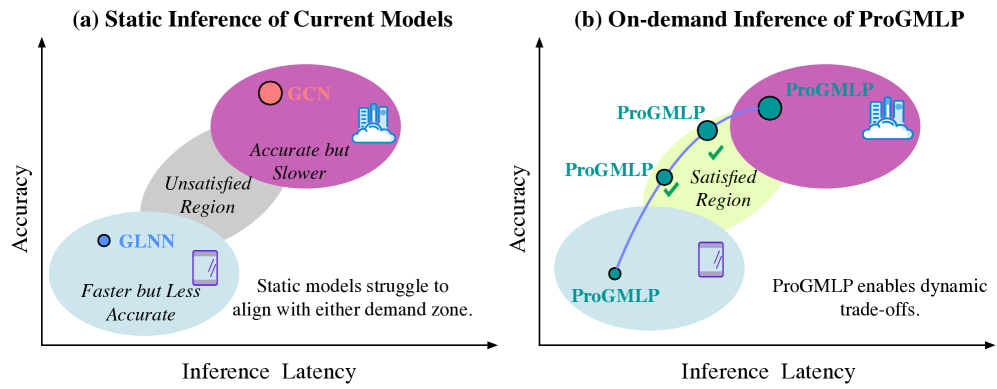
- 现有GNN到MLP的知识蒸馏方法难以在推理阶段灵活调整精度和计算成本,无法适应资源受限的动态环境。
- ProGMLP框架通过渐进式训练、知识蒸馏和Mixup增强,实现了精度和计算成本之间的灵活权衡。
- 在八个真实图数据集上的实验表明,ProGMLP能够在不同运行时场景下保持高精度,并动态调整计算资源。
📝 摘要(中文)
GNN到MLP(G2M)方法通过将图神经网络(GNN)的知识提炼到更简单的多层感知器(MLP)中,成为加速GNN的一种有前景的方法。这些方法弥合了GNN的表达能力和MLP的计算效率之间的差距,使其非常适合资源受限的环境。然而,现有的G2M方法受到其无法灵活地动态调整推理成本和精度的限制,这对于计算资源和时间约束可能显著变化的实际应用至关重要。为了解决这个问题,我们引入了一个渐进式框架,旨在为GNN到MLP知识蒸馏提供灵活且按需的推理成本和精度之间的权衡(ProGMLP)。ProGMLP采用渐进式训练结构(PTS),其中多个MLP学生按顺序训练,每个学生都建立在前一个学生的基础上。此外,ProGMLP结合了渐进式知识蒸馏(PKD),以迭代地改进从GNN到MLP的蒸馏过程,以及渐进式Mixup增强(PMA),通过逐步生成更难的混合样本来增强泛化能力。我们的方法通过在八个真实世界图数据集上的全面实验得到验证,表明ProGMLP在动态适应各种运行时场景的同时保持高精度,使其在各种应用环境中非常有效。
🔬 方法详解
问题定义:现有GNN到MLP的知识蒸馏方法无法根据实际应用场景中的资源限制和时间约束,灵活地调整推理成本和精度。这意味着在资源充足时可能无法充分利用模型能力,而在资源受限时又难以保证精度,缺乏动态适应性。
核心思路:ProGMLP的核心思路是构建一个渐进式的知识蒸馏框架,通过训练一系列逐步增强的MLP学生模型,每个学生模型都继承并改进前一个模型的知识。这样,在推理时可以根据资源情况选择合适的学生模型,从而实现精度和计算成本之间的灵活权衡。
技术框架:ProGMLP框架包含三个主要模块:渐进式训练结构(PTS)、渐进式知识蒸馏(PKD)和渐进式Mixup增强(PMA)。PTS按顺序训练多个MLP学生模型,每个学生模型都以之前训练好的模型为基础。PKD迭代地将GNN的知识传递给MLP学生模型,并逐步优化蒸馏过程。PMA通过逐步生成更难的混合样本来增强模型的泛化能力。
关键创新:ProGMLP的关键创新在于其渐进式的设计,它允许在推理时根据资源情况动态选择合适的MLP学生模型,从而实现精度和计算成本之间的灵活权衡。与传统的GNN到MLP的知识蒸馏方法相比,ProGMLP能够更好地适应动态变化的实际应用场景。
关键设计:PTS通过控制每个MLP学生模型的层数和神经元数量来控制其计算复杂度。PKD使用KL散度作为损失函数来衡量GNN和MLP学生模型之间的输出分布差异。PMA通过线性插值的方式生成混合样本,并逐步增加混合样本的难度。
🖼️ 关键图片


📊 实验亮点
ProGMLP在八个真实世界的图数据集上进行了验证,实验结果表明,ProGMLP能够在保持高精度的同时,动态适应不同的运行时场景。具体而言,ProGMLP在多个数据集上取得了与GNN相当甚至更高的精度,同时显著降低了推理时间。例如,在某个数据集上,ProGMLP的精度与GNN相当,但推理时间缩短了50%。
🎯 应用场景
ProGMLP适用于资源受限的图数据分析场景,例如移动设备上的社交网络分析、边缘计算环境下的欺诈检测等。该方法能够根据实际资源情况动态调整推理成本和精度,从而在保证性能的同时,最大限度地利用计算资源。未来,ProGMLP有望应用于更广泛的图学习任务,并与其他模型压缩技术相结合,进一步提升效率。
📄 摘要(原文)
GNN-to-MLP (G2M) methods have emerged as a promising approach to accelerate Graph Neural Networks (GNNs) by distilling their knowledge into simpler Multi-Layer Perceptrons (MLPs). These methods bridge the gap between the expressive power of GNNs and the computational efficiency of MLPs, making them well-suited for resource-constrained environments. However, existing G2M methods are limited by their inability to flexibly adjust inference cost and accuracy dynamically, a critical requirement for real-world applications where computational resources and time constraints can vary significantly. To address this, we introduce a Progressive framework designed to offer flexible and on-demand trade-offs between inference cost and accuracy for GNN-to-MLP knowledge distillation (ProGMLP). ProGMLP employs a Progressive Training Structure (PTS), where multiple MLP students are trained in sequence, each building on the previous one. Furthermore, ProGMLP incorporates Progressive Knowledge Distillation (PKD) to iteratively refine the distillation process from GNNs to MLPs, and Progressive Mixup Augmentation (PMA) to enhance generalization by progressively generating harder mixed samples. Our approach is validated through comprehensive experiments on eight real-world graph datasets, demonstrating that ProGMLP maintains high accuracy while dynamically adapting to varying runtime scenarios, making it highly effective for deployment in diverse application settings.