The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
作者: Jiale Chen, Yalda Shabanzadeh, Elvir Crnčević, Torsten Hoefler, Dan Alistarh
分类: cs.LG
发布日期: 2025-07-24 (更新: 2025-10-01)
💡 一句话要点
揭示GPTQ量化本质:将其等价于Babai最近平面算法,并提出改进方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 GPTQ Babai算法 格理论 最近向量问题
📋 核心要点
- 现有LLM量化方法,如GPTQ,缺乏明确的几何解释和理论保证,其内部运作难以理解。
- 论文将GPTQ等价于Babai最近平面算法,为GPTQ提供了几何解释和误差上界,并基于此设计了改进的量化方法。
- 实验表明,提出的避免裁剪的量化方法优于原始GPTQ,并提供了高效的GPU推理内核。
📝 摘要(中文)
将大型语言模型(LLM)的权重从16位量化到更低的位宽,是部署大规模Transformer到更经济的加速器上的事实标准方法。GPTQ作为一种在LLM规模上进行一次性后训练量化的标准方法,其内部运作被描述为一系列临时的代数更新,掩盖了几何意义或最坏情况保证。本文证明,当对线性层从后向前(从最后一个维度到第一个维度)执行时,GPTQ在数学上等同于Babai的最近平面算法,用于由该层输入的Hessian矩阵定义的格上的经典最近向量问题(CVP)。这种等价性基于复杂的数学论证,并具有两个分析结果:首先,GPTQ误差传播步骤获得直观的几何解释;其次,在没有权重被裁剪的假设下,GPTQ继承了Babai算法的误差上限。利用这个界限,我们设计了避免裁剪的后训练量化方法,并优于原始GPTQ。此外,我们为生成的表示提供了高效的GPU推理内核。总而言之,这些结果为GPTQ奠定了坚实的理论基础,并为将数十年来在格算法方面的进展引入到未来数十亿参数模型的量化算法设计中打开了大门。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)量化过程中,GPTQ方法缺乏明确的几何解释和理论保证的问题。现有方法将GPTQ视为一系列临时的代数更新,难以理解其内在机制,也缺乏对量化误差的有效控制。
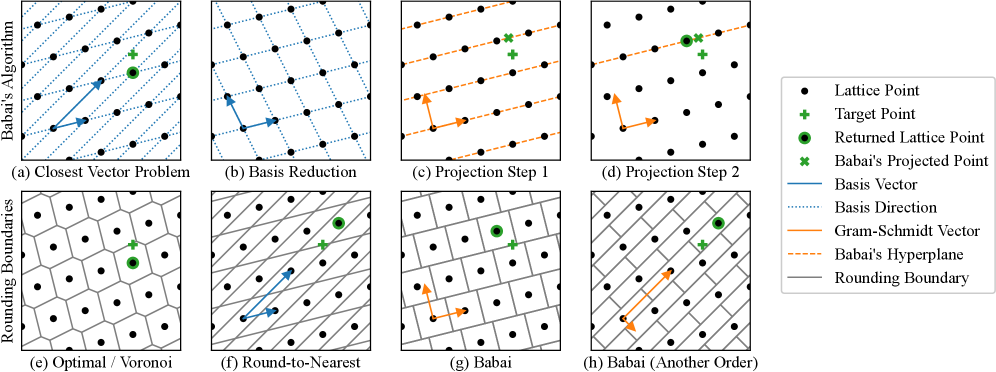
核心思路:论文的核心思路是将GPTQ算法与格理论中的Babai最近平面算法联系起来。通过证明GPTQ在特定执行顺序下等价于Babai算法,为GPTQ赋予了几何意义,并利用Babai算法的误差上界来分析和改进GPTQ。
技术框架:论文的技术框架主要包括以下几个步骤:1) 数学证明GPTQ与Babai算法的等价性;2) 基于等价性,分析GPTQ的误差传播过程,并获得误差上界;3) 设计避免权重裁剪的量化方法,以利用误差上界;4) 实现高效的GPU推理内核。
关键创新:论文最重要的技术创新点在于建立了GPTQ与Babai最近平面算法之间的数学等价关系。这种等价性不仅为GPTQ提供了理论基础,也为改进GPTQ提供了新的思路。此外,基于误差上界设计的避免裁剪的量化方法也是一个重要的创新。
关键设计:论文的关键设计包括:1) 从后向前执行GPTQ,以保证其与Babai算法的等价性;2) 设计避免权重裁剪的量化策略,例如通过调整量化范围或使用不同的量化函数;3) 优化GPU推理内核,以提高量化模型的推理速度。
🖼️ 关键图片


📊 实验亮点
论文提出的避免裁剪的量化方法在实验中优于原始GPTQ,具体性能提升数据未知。此外,论文还提供了高效的GPU推理内核,进一步提升了量化模型的实用性。该研究为LLM量化领域提供了新的理论视角和实践方法。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,例如边缘计算设备、移动设备和资源受限的服务器。通过改进量化方法,可以在保证模型性能的同时,显著降低模型大小和计算复杂度,从而实现更高效的模型部署和推理。
📄 摘要(原文)
Quantizing the weights of large language models (LLMs) from 16-bit to lower bitwidth is the de facto approach to deploy massive transformers onto more affordable accelerators. While GPTQ emerged as one of the standard methods for one-shot post-training quantization at LLM scale, its inner workings are described as a sequence of ad-hoc algebraic updates that obscure geometric meaning or worst-case guarantees. In this work, we show that, when executed back-to-front (from the last to first dimension) for a linear layer, GPTQ is mathematically identical to Babai's nearest plane algorithm for the classical closest vector problem (CVP) on a lattice defined by the Hessian matrix of the layer's inputs. This equivalence is based on a sophisticated mathematical argument, and has two analytical consequences: first, the GPTQ error propagation step gains an intuitive geometric interpretation; second, GPTQ inherits the error upper bound of Babai's algorithm under the assumption that no weights are clipped. Leveraging this bound, we design post-training quantization methods that avoid clipping, and outperform the original GPTQ. In addition, we provide efficient GPU inference kernels for the resulting representation. Taken together, these results place GPTQ on a firm theoretical footing and open the door to importing decades of progress in lattice algorithms towards the design of future quantization algorithms for billion-parameter models.