Scaling Linear Attention with Sparse State Expansion
作者: Yuqi Pan, Yongqi An, Zheng Li, Yuhong Chou, Ruijie Zhu, Xiaohui Wang, Mingxuan Wang, Jinqiao Wang, Guoqi Li
分类: cs.LG, cs.CL
发布日期: 2025-07-22 (更新: 2025-10-01)
💡 一句话要点
提出基于稀疏状态扩展的线性注意力机制,有效处理长上下文建模问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 长上下文建模 稀疏状态更新 状态扩展 Transformer 数学推理 信息检索
📋 核心要点
- Transformer在长序列处理中面临计算和内存瓶颈,线性注意力虽然降低了复杂度,但损失了性能。
- 论文提出稀疏状态扩展(SSE),通过稀疏更新和状态分区,在降低计算量的同时提升上下文建模能力。
- 实验表明,SSE在语言建模、检索和数学推理任务上表现出色,尤其是在数学推理上取得了显著的性能提升。
📝 摘要(中文)
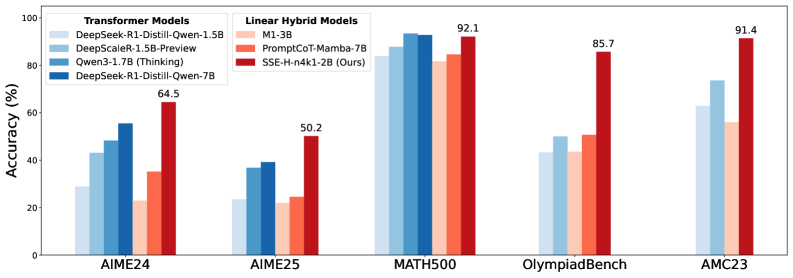
Transformer架构虽然应用广泛,但在长上下文场景中面临计算量二次增长和内存线性增长的挑战。线性注意力变体通过将上下文压缩到固定大小的状态来缓解这些效率限制,但通常会降低上下文检索和推理等任务的性能。为了解决这个限制并实现更有效的上下文压缩,我们提出了两个关键创新。首先,我们将状态更新概念化为信息分类,从而为线性注意力引入了行稀疏更新公式。这可以通过基于softmax的top-$k$硬分类实现稀疏状态更新,从而扩展感受野并减少类间干扰。其次,我们在稀疏框架内提出了稀疏状态扩展(SSE),它将上下文状态扩展到多个分区,有效地将参数大小与状态容量解耦,同时保持稀疏分类范式。在高效并行化实现的支持下,我们的设计实现了有效的分类和高度区分性的状态表示。我们在语言建模、上下文检索和数学推理基准测试中,对纯线性架构和混合架构(SSE-H)中的SSE进行了广泛验证。SSE表现出强大的检索性能,并随着状态大小的增加而表现良好。此外,经过强化学习(RL)训练后,我们的2B SSE-H模型在小型推理模型中实现了最先进的数学推理性能,在AIME24上获得64.5分,在AIME25上获得50.2分,显著优于类似大小的开源Transformer。这些结果表明,SSE是一种有前途且高效的长上下文建模架构。
🔬 方法详解
问题定义:Transformer在处理长序列时,计算复杂度随序列长度呈二次方增长,内存占用呈线性增长,这限制了其在长上下文场景中的应用。线性注意力机制通过将上下文压缩成固定大小的状态向量来降低计算复杂度,但这种压缩往往会导致信息损失,从而影响模型在上下文检索和推理等任务中的性能。
核心思路:论文的核心思路是将状态更新视为信息分类问题,并采用稀疏更新的方式,只更新状态向量中最相关的部分。同时,通过状态扩展,将状态向量分成多个分区,从而在不显著增加参数量的情况下,提升状态容量和表达能力。这样既能降低计算复杂度,又能保留更多的上下文信息。
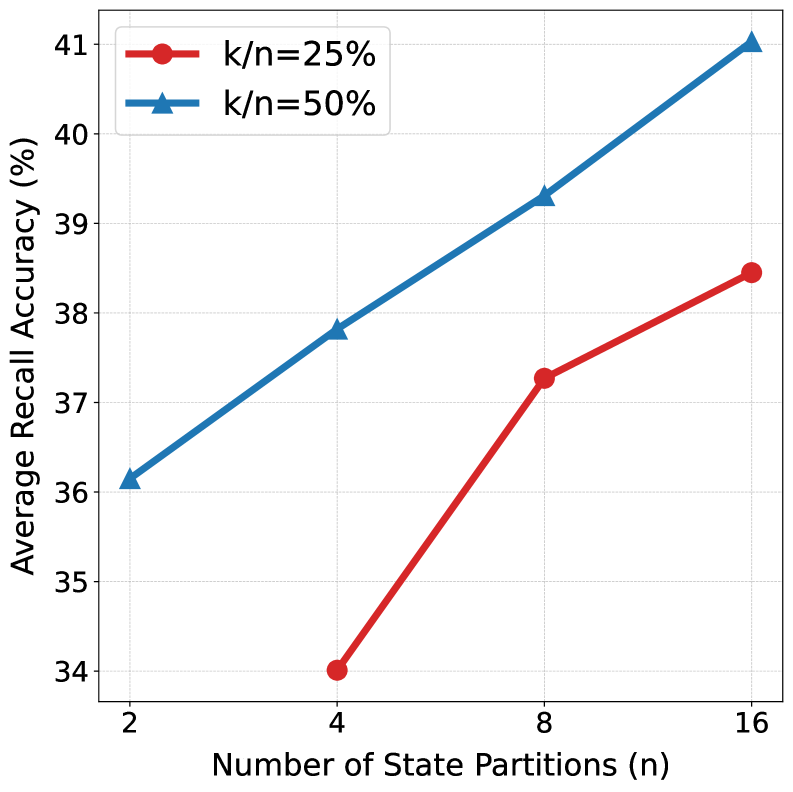
技术框架:SSE(Sparse State Expansion)框架主要包含两个核心模块:稀疏状态更新和状态扩展。稀疏状态更新模块利用softmax函数对输入信息进行分类,并选择top-k个最相关的状态向量进行更新。状态扩展模块将状态向量分成多个分区,每个分区独立进行更新,从而增加状态容量。整个框架可以嵌入到现有的线性注意力机制中,形成混合架构(SSE-H)。
关键创新:论文的关键创新在于提出了稀疏状态更新和状态扩展两种机制。稀疏状态更新通过只更新最相关的状态向量,减少了计算量和类间干扰,从而提升了模型的性能。状态扩展通过将状态向量分成多个分区,增加了状态容量,从而提升了模型对长上下文信息的建模能力。与传统的线性注意力机制相比,SSE能够在降低计算复杂度的同时,保持甚至提升模型的性能。
关键设计:在稀疏状态更新中,使用softmax函数对输入信息进行分类,并选择top-k个最相关的状态向量进行更新。k值的选择需要根据具体的任务和数据集进行调整。在状态扩展中,状态向量被分成多个分区,每个分区的大小和数量需要根据具体的任务和数据集进行调整。损失函数方面,可以使用交叉熵损失函数或hinge loss等。在混合架构(SSE-H)中,需要平衡线性注意力和SSE的权重,以达到最佳的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SSE在语言建模、上下文检索和数学推理任务上表现出色。在数学推理任务中,2B SSE-H模型在AIME24上获得64.5分,在AIME25上获得50.2分,显著优于类似大小的开源Transformer模型。这表明SSE在长上下文建模方面具有显著的优势。
🎯 应用场景
该研究成果可应用于需要处理长上下文信息的各种场景,例如长文本摘要、机器翻译、对话系统、知识图谱推理等。通过降低计算复杂度和提升上下文建模能力,SSE能够使模型更好地理解和利用长上下文信息,从而提升模型在这些任务上的性能。此外,该研究成果还可以应用于资源受限的设备上,例如移动设备和嵌入式系统。
📄 摘要(原文)
The Transformer architecture, despite its widespread success, struggles with long-context scenarios due to quadratic computation and linear memory growth. While various linear attention variants mitigate these efficiency constraints by compressing context into fixed-size states, they often degrade performance in tasks such as in-context retrieval and reasoning. To address this limitation and achieve more effective context compression, we propose two key innovations. First, we introduce a row-sparse update formulation for linear attention by conceptualizing state updating as information classification. This enables sparse state updates via softmax-based top-$k$ hard classification, thereby extending receptive fields and reducing inter-class interference. Second, we present Sparse State Expansion (SSE) within the sparse framework, which expands the contextual state into multiple partitions, effectively decoupling parameter size from state capacity while maintaining the sparse classification paradigm. Supported by efficient parallelized implementations, our design achieves effective classification and highly discriminative state representations. We extensively validate SSE in both pure linear and hybrid (SSE-H) architectures across language modeling, in-context retrieval, and mathematical reasoning benchmarks. SSE demonstrates strong retrieval performance and scales favorably with state size. Moreover, after reinforcement learning (RL) training, our 2B SSE-H model achieves state-of-the-art mathematical reasoning performance among small reasoning models, scoring 64.5 on AIME24 and 50.2 on AIME25, significantly outperforming similarly sized open-source Transformers. These results highlight SSE as a promising and efficient architecture for long-context modeling.