Diffusion Beats Autoregressive in Data-Constrained Settings
作者: Mihir Prabhudesai, Mengning Wu, Amir Zadeh, Katerina Fragkiadaki, Deepak Pathak
分类: cs.LG, cs.AI, cs.CV, cs.RO
发布日期: 2025-07-21 (更新: 2025-10-26)
备注: Project Webpage: https://diffusion-scaling.github.io
💡 一句话要点
在数据受限场景下,扩散模型超越自回归模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 自回归模型 数据受限 语言建模 掩码语言模型
📋 核心要点
- 自回归模型在大型语言模型中占据主导地位,但在数据受限场景下性能受限。
- 论文提出使用掩码扩散模型,通过随机掩码目标进行训练,实现隐式数据增强。
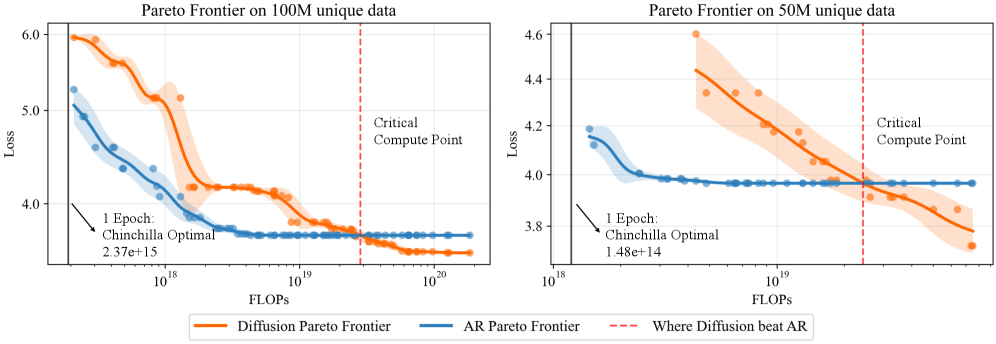
- 实验表明,在数据受限但计算资源充足的情况下,扩散模型显著优于自回归模型。
📝 摘要(中文)
自回归(AR)模型长期以来主导着大型语言模型领域,推动了各种任务的进展。最近,基于扩散的语言模型作为一种有希望的替代方案出现,但它们相对于AR模型的优势仍未被充分探索。本文系统地研究了在数据受限场景下的掩码扩散模型,其中训练涉及对有限数据的重复传递,并发现当计算资源充足但数据稀缺时,它们显著优于AR模型。扩散模型更好地利用了重复数据,实现了更低的验证损失和卓越的下游性能。我们发现了扩散模型的新缩放定律,并推导出了一个闭式表达式,用于计算扩散模型开始优于AR模型的临界计算阈值。最后,我们解释了为什么扩散模型在这种情况下表现出色:它们的随机掩码目标隐式地训练了丰富的token排序分布,充当了一种隐式数据增强,而AR模型固定的从左到右分解方式缺乏这种能力。我们的结果表明,当数据而非计算成为瓶颈时,扩散模型为标准AR范式提供了一个引人注目的替代方案。
🔬 方法详解
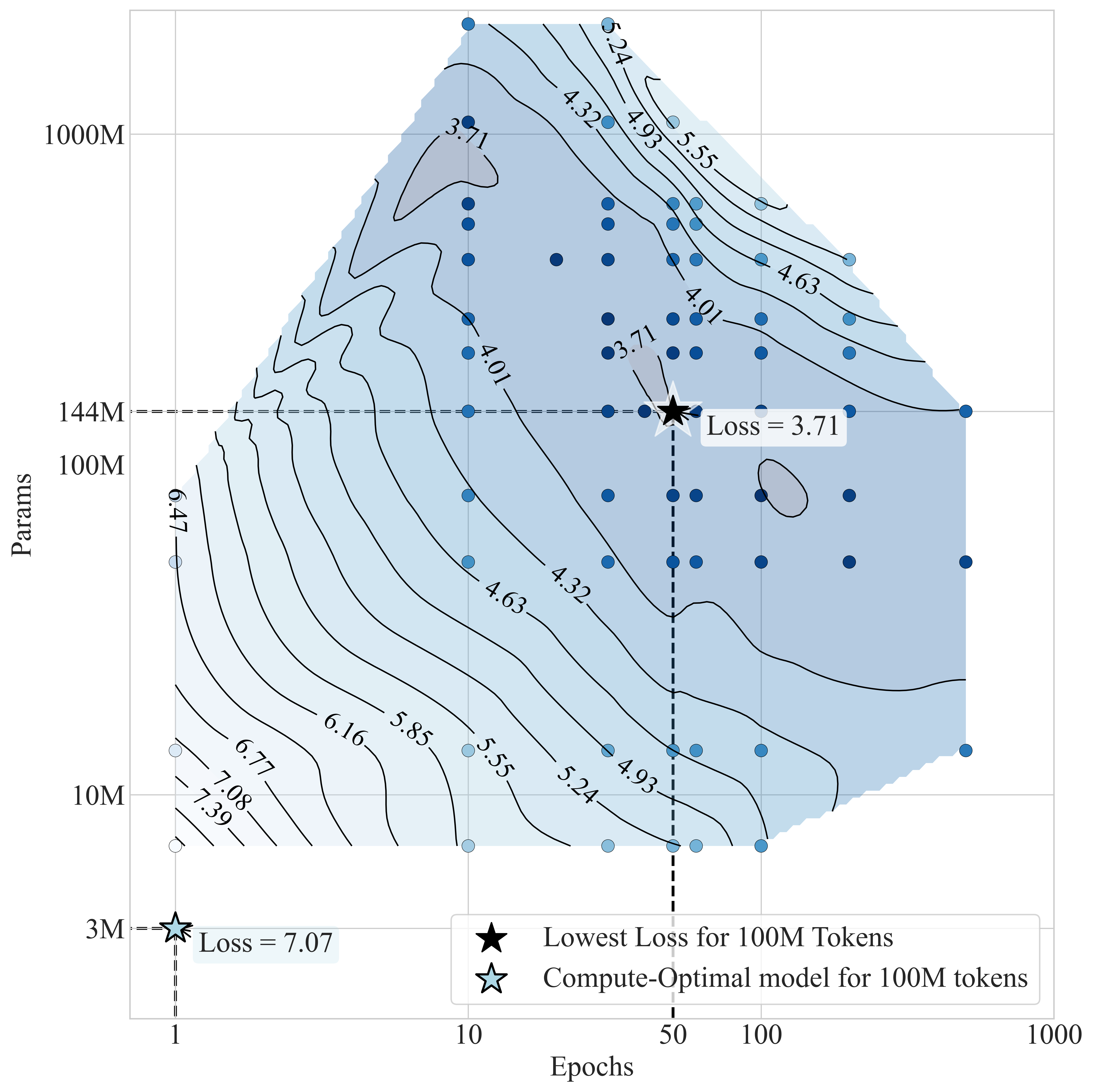
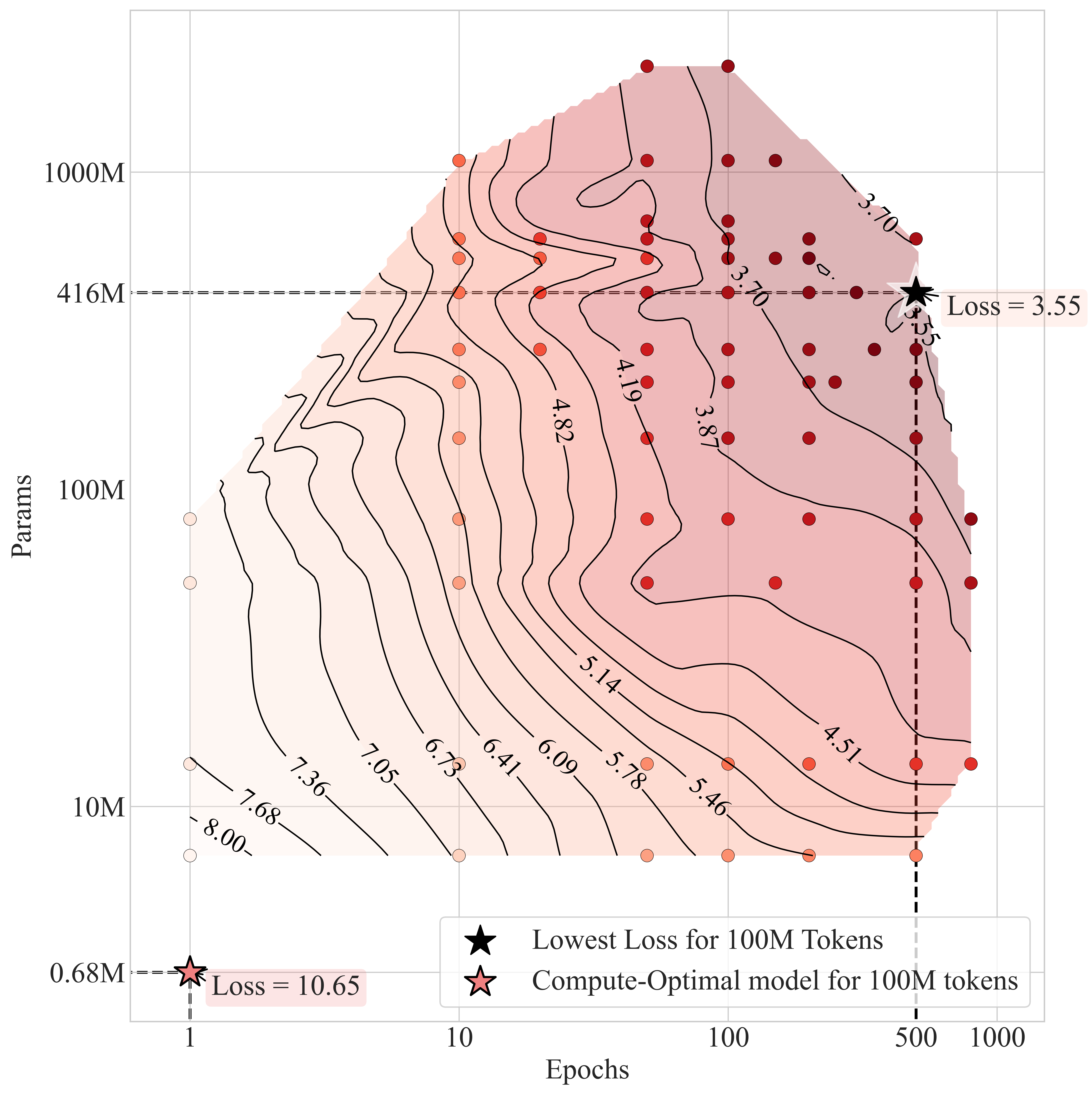
问题定义:论文旨在解决在数据量有限的情况下,如何训练出高性能的语言模型的问题。传统的自回归模型在数据量不足时容易过拟合,泛化能力较差。现有方法缺乏有效利用有限数据的机制,导致模型性能受限。
核心思路:论文的核心思路是利用扩散模型进行语言建模,通过随机掩码token并预测被掩码的token,从而学习token之间的依赖关系。这种随机掩码的方式可以看作是一种隐式的数据增强,使得模型能够学习到更多不同的token排序,从而提高模型的泛化能力。
技术框架:论文采用掩码扩散模型,其整体框架如下:1)输入文本序列;2)随机掩码部分token;3)使用扩散模型预测被掩码的token;4)计算损失函数并更新模型参数。该框架的核心是扩散模型,它通过迭代的方式逐步恢复被掩码的token,从而学习到token之间的依赖关系。
关键创新:论文最重要的技术创新点在于将扩散模型应用于语言建模,并证明了其在数据受限场景下的优越性。与传统的自回归模型相比,扩散模型通过随机掩码的方式进行训练,能够学习到更多不同的token排序,从而提高模型的泛化能力。这种随机掩码的方式可以看作是一种隐式的数据增强,是扩散模型优于自回归模型的关键原因。
关键设计:论文的关键设计包括:1)随机掩码策略:采用随机掩码的方式,保证模型能够学习到各种不同的token排序;2)扩散模型的网络结构:采用Transformer结构作为扩散模型的基本单元,以捕捉token之间的长距离依赖关系;3)损失函数:采用交叉熵损失函数,衡量模型预测被掩码token的准确性;4)训练策略:采用多次迭代训练的方式,充分利用有限的数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在数据受限场景下,扩散模型显著优于自回归模型。具体来说,扩散模型在验证集上的损失更低,下游任务的性能更高。论文还发现了扩散模型的新缩放定律,并推导出了扩散模型开始优于自回归模型的临界计算阈值。
🎯 应用场景
该研究成果可应用于各种数据受限的自然语言处理任务,例如低资源语言翻译、特定领域文本生成等。通过使用扩散模型,可以在数据量不足的情况下训练出高性能的语言模型,从而降低对大规模数据集的依赖,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Autoregressive (AR) models have long dominated the landscape of large language models, driving progress across a wide range of tasks. Recently, diffusion-based language models have emerged as a promising alternative, though their advantages over AR models remain underexplored. In this paper, we systematically study masked diffusion models in data-constrained settings where training involves repeated passes over limited data and find that they significantly outperform AR models when compute is abundant but data is scarce. Diffusion models make better use of repeated data, achieving lower validation loss and superior downstream performance. We find new scaling laws for diffusion models and derive a closed-form expression for the critical compute threshold at which diffusion begins to outperform AR. Finally, we explain why diffusion models excel in this regime: their randomized masking objective implicitly trains over a rich distribution of token orderings, acting as an implicit data augmentation that AR's fixed left-to-right factorization lacks. Our results suggest that when data, not compute, is the bottleneck, diffusion models offer a compelling alternative to the standard AR paradigm. Our code is available at: https://diffusion-scaling.github.io.