Just Ask for Music (JAM): Multimodal and Personalized Natural Language Music Recommendation
作者: Alessandro B. Melchiorre, Elena V. Epure, Shahed Masoudian, Gustavo Escobedo, Anna Hausberger, Manuel Moussallam, Markus Schedl
分类: cs.IR, cs.LG
发布日期: 2025-07-21
💡 一句话要点
提出JAM框架,用于多模态和个性化的自然语言音乐推荐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言音乐推荐 多模态融合 个性化推荐 向量转换 知识图谱嵌入
📋 核心要点
- 现有自然语言音乐推荐方法面临成本高、延迟大等问题,检索式方法虽缓解了这些问题,但忽略了用户长期偏好。
- JAM框架将用户查询和音乐项目映射到共享潜在空间,利用向量转换关系进行推荐,并融合多模态特征。
- JAMSessions数据集包含用户长期偏好和对话式查询,实验表明JAM能提供准确推荐,并易于集成。
📝 摘要(中文)
本文提出了一种轻量级且直观的自然语言音乐推荐框架JAM(Just Ask for Music)。JAM将用户-查询-项目交互建模为共享潜在空间中的向量转换,灵感来源于知识图谱嵌入方法TransE。为了捕捉音乐和用户意图的复杂性,JAM通过交叉注意力和稀疏混合专家模型聚合多模态项目特征。此外,本文还引入了一个新的数据集JAMSessions,包含超过10万个用户-查询-项目三元组,具有匿名化的用户/项目嵌入,独特地结合了对话式查询和用户长期偏好。实验结果表明,JAM能够提供准确的推荐,生成适用于实际用例的直观表示,并且可以轻松地与现有的音乐推荐系统集成。
🔬 方法详解
问题定义:现有自然语言音乐推荐系统面临着扩展性问题,大型语言模型(LLM)成本高、延迟大。检索式方法虽然降低了成本,但通常依赖于单模态的项目表示,忽略了用户的长期偏好,并且需要完全重新训练模型,这给实际部署带来了挑战。因此,需要一种轻量级、能够捕捉用户长期偏好和多模态信息的自然语言音乐推荐方法。
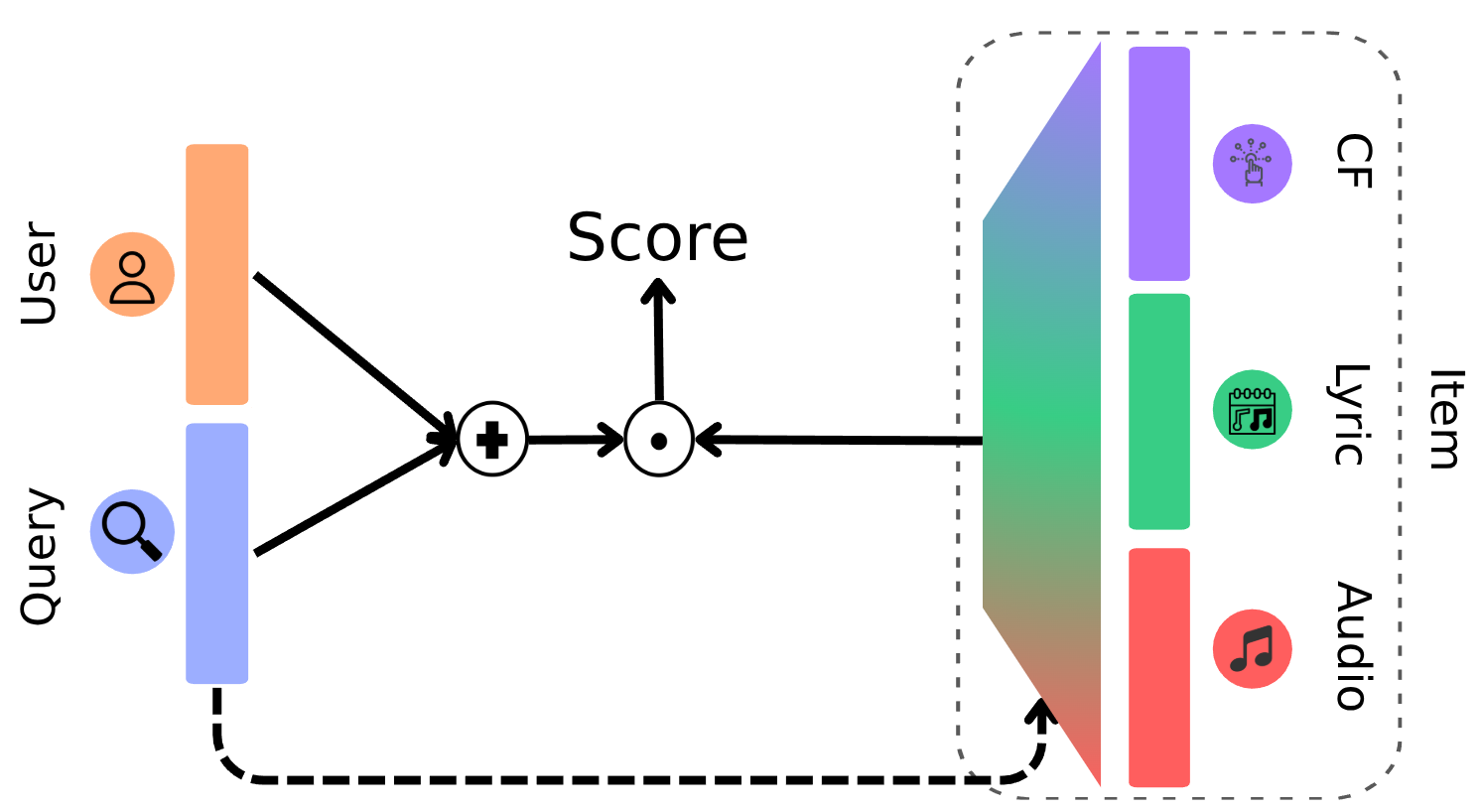
核心思路:JAM的核心思路是将用户查询和音乐项目嵌入到共享的潜在空间中,并利用向量转换关系来建模用户对音乐的偏好。具体来说,用户查询可以被视为从用户向量到目标音乐项目向量的转换。通过学习这种转换关系,JAM可以预测用户在给定查询下可能喜欢的音乐项目。这种方法借鉴了知识图谱嵌入的思想,例如TransE。
技术框架:JAM框架主要包含以下几个模块:1) 用户和项目嵌入模块:将用户和音乐项目映射到潜在空间中。用户嵌入可以基于用户的历史行为数据,项目嵌入可以基于音乐的多模态特征。2) 查询嵌入模块:将用户的自然语言查询嵌入到潜在空间中。3) 向量转换模块:学习用户查询和目标音乐项目之间的向量转换关系。4) 多模态特征融合模块:利用交叉注意力和稀疏混合专家模型融合音乐的多模态特征,例如音频、歌词和元数据。
关键创新:JAM的关键创新在于:1) 将用户-查询-项目交互建模为向量转换,借鉴了知识图谱嵌入的思想。2) 利用交叉注意力和稀疏混合专家模型融合多模态特征,更好地捕捉音乐的复杂性。3) 提出了JAMSessions数据集,该数据集包含用户长期偏好和对话式查询,为自然语言音乐推荐研究提供了新的资源。
关键设计:JAM的关键设计包括:1) 使用TransE损失函数来学习向量转换关系。2) 使用交叉注意力机制来融合不同模态的特征。3) 使用稀疏混合专家模型来提高模型的表达能力。4) JAMSessions数据集包含超过10万个用户-查询-项目三元组,并提供了匿名化的用户/项目嵌入。
🖼️ 关键图片

📊 实验亮点
实验结果表明,JAM在音乐推荐任务上取得了良好的性能。与现有方法相比,JAM能够提供更准确的推荐,并且可以生成适用于实际用例的直观表示。此外,JAM还可以轻松地与现有的音乐推荐系统集成,具有很强的实用性。
🎯 应用场景
JAM框架可应用于各种音乐推荐场景,例如智能音箱、音乐流媒体平台和车载音乐系统。它可以根据用户的自然语言查询和长期偏好,提供个性化的音乐推荐。该研究有助于提升用户体验,并为音乐产业带来新的商业机会。
📄 摘要(原文)
Natural language interfaces offer a compelling approach for music recommendation, enabling users to express complex preferences conversationally. While Large Language Models (LLMs) show promise in this direction, their scalability in recommender systems is limited by high costs and latency. Retrieval-based approaches using smaller language models mitigate these issues but often rely on single-modal item representations, overlook long-term user preferences, and require full model retraining, posing challenges for real-world deployment. In this paper, we present JAM (Just Ask for Music), a lightweight and intuitive framework for natural language music recommendation. JAM models user-query-item interactions as vector translations in a shared latent space, inspired by knowledge graph embedding methods like TransE. To capture the complexity of music and user intent, JAM aggregates multimodal item features via cross-attention and sparse mixture-of-experts. We also introduce JAMSessions, a new dataset of over 100k user-query-item triples with anonymized user/item embeddings, uniquely combining conversational queries and user long-term preferences. Our results show that JAM provides accurate recommendations, produces intuitive representations suitable for practical use cases, and can be easily integrated with existing music recommendation stacks.