MultiKernelBench: A Multi-Platform Benchmark for Kernel Generation
作者: Zhongzhen Wen, Yinghui Zhang, Zhong Li, Zhongxin Liu, Linna Xie, Tian Zhang
分类: cs.DC, cs.LG, cs.PF, cs.SE
发布日期: 2025-07-20 (更新: 2025-07-26)
🔗 代码/项目: GITHUB
💡 一句话要点
MultiKernelBench:首个面向多平台的大模型内核生成综合基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内核生成 大型语言模型 基准测试 深度学习 异构计算平台
📋 核心要点
- 现有深度学习内核生成基准测试硬件支持有限,内核分类粗糙,任务覆盖不均衡。
- MultiKernelBench通过构建多平台、细粒度、任务均衡的基准测试来解决上述问题。
- 实验表明,现有LLM在不同硬件平台上的泛化能力差异显著,类别感知提示策略有效。
📝 摘要(中文)
本文提出了MultiKernelBench,这是一个全面的、多平台的基准测试,用于评估基于大型语言模型(LLMs)的深度学习(DL)内核生成。现有基准测试在硬件支持、内核分类粒度和任务覆盖方面存在局限性。MultiKernelBench涵盖了14个明确定义的内核类别中的285个任务,并支持Nvidia GPU、华为NPU和Google TPU三大硬件平台。为了便于扩展,设计了一个模块化的后端抽象层,将平台特定逻辑与核心基准测试基础设施分离,从而简化了新硬件平台的集成。此外,提出了一种简单有效的类别感知单样本提示方法,通过提供同类别示例来提高生成质量。通过对七个最先进的LLM的系统评估,揭示了任务难度差异、对训练较少的平台泛化能力差以及有针对性的提示策略的有效性。MultiKernelBench已在https://github.com/wzzll123/MultiKernelBench上公开。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型自动生成深度学习内核时,缺乏一个全面、多平台的评估基准的问题。现有基准测试存在硬件支持不足(通常只支持Nvidia GPU),内核分类过于宽泛,以及任务覆盖不均衡等痛点,难以全面评估LLM在不同硬件平台和不同类型内核生成任务上的能力。
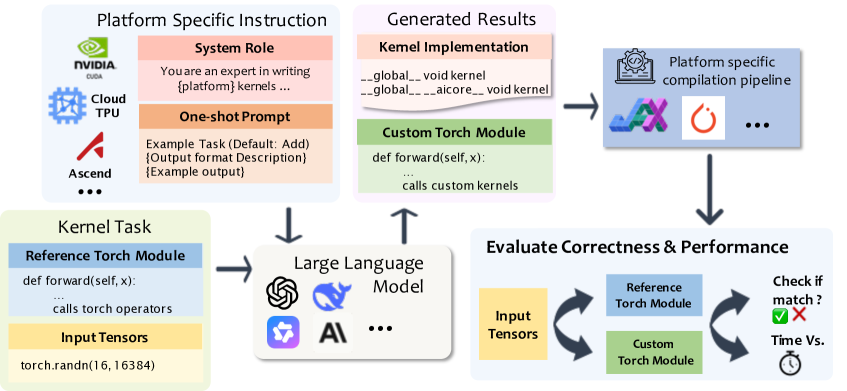
核心思路:论文的核心思路是构建一个包含多种硬件平台、多种内核类型和多种任务的综合性基准测试集,并设计一个模块化的后端抽象层,以便于扩展到新的硬件平台。此外,论文还提出了一种类别感知的单样本提示方法,通过提供同类别示例来提高LLM生成内核的质量。
技术框架:MultiKernelBench的技术框架主要包括以下几个部分:1)一个包含285个任务的基准测试集,涵盖14个内核类别,并支持Nvidia GPU、华为NPU和Google TPU三大硬件平台;2)一个模块化的后端抽象层,用于解耦平台特定逻辑和核心基准测试基础设施;3)一个类别感知的单样本提示方法,用于提高LLM生成内核的质量;4)一套评估指标,用于评估LLM生成内核的性能和正确性。
关键创新:MultiKernelBench的关键创新在于:1)它是首个面向多平台的大模型内核生成综合基准测试;2)它提出了一个模块化的后端抽象层,便于扩展到新的硬件平台;3)它提出了一种类别感知的单样本提示方法,提高了LLM生成内核的质量。
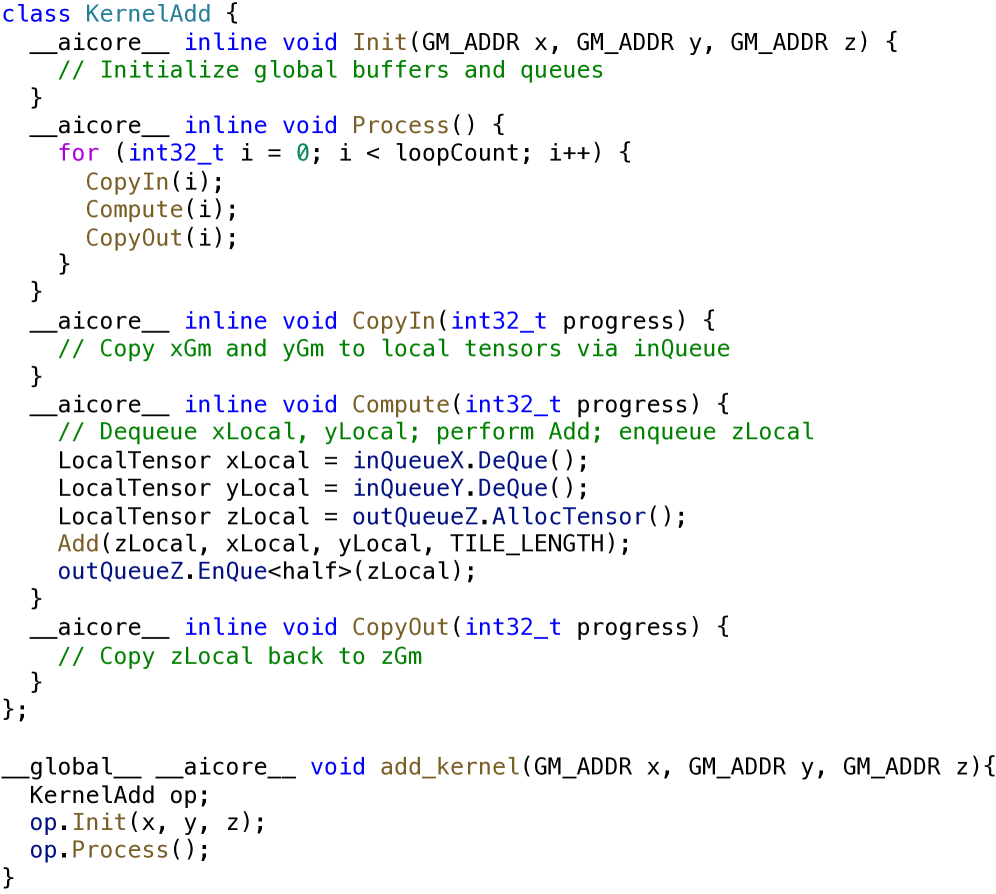
关键设计:类别感知的单样本提示方法是关键设计之一。该方法根据当前任务的内核类别,从基准测试集中选择一个同类别的示例,并将该示例作为提示信息输入给LLM。这种方法可以帮助LLM更好地理解当前任务的要求,从而生成更高质量的内核代码。具体的示例选择策略和提示信息格式未知。
🖼️ 关键图片

📊 实验亮点
通过对七个最先进的LLM的系统评估,MultiKernelBench揭示了任务难度差异、LLM对训练较少的平台泛化能力较差,以及类别感知提示策略的有效性。具体性能数据和提升幅度未知,但结果表明,针对特定平台和任务的提示策略可以显著提高LLM生成内核的质量。
🎯 应用场景
MultiKernelBench可用于评估和比较不同LLM在深度学习内核生成方面的能力,帮助研究人员选择合适的LLM来自动生成高性能的内核代码。此外,该基准测试还可以促进LLM在异构硬件平台上的应用,降低手动编写内核代码的成本,并加速深度学习应用的开发和部署。
📄 摘要(原文)
The automatic generation of deep learning (DL) kernels using large language models (LLMs) has emerged as a promising approach to reduce the manual effort and hardware-specific expertise required for writing high-performance operator implementations. However, existing benchmarks for evaluating LLMs in this domain suffer from limited hardware support, coarse-grained kernel categorization, and imbalanced task coverage. To address these limitations, we introduce MultiKernelBench, the first comprehensive, multi-platform benchmark for LLM-based DL kernel generation. MultiKernelBench spans 285 tasks across 14 well-defined kernel categories and supports three major hardware platforms: Nvidia GPUs, Huawei NPUs, and Google TPUs. To enable future extensibility, we design a modular backend abstraction layer that decouples platform-specific logic from the core benchmarking infrastructure, allowing easy integration of new hardware platforms. We further propose a simple yet effective category-aware one-shot prompting method that improves generation quality by providing in-category exemplars. Through systematic evaluations of seven state-of-the-art LLMs, we reveal significant variation in task difficulty, poor generalization to platforms with less training exposure, and the effectiveness of targeted prompting strategies. MultiKernelBench is publicly available at https://github.com/wzzll123/MultiKernelBench.