LibLMFuzz: LLM-Augmented Fuzz Target Generation for Black-box Libraries
作者: Ian Hardgrove, John D. Hastings
分类: cs.CR, cs.LG, cs.SE
发布日期: 2025-07-20
备注: 6 pages, 2 figures, 1 table, 2 listings
💡 一句话要点
LibLMFuzz:利用LLM增强的模糊测试目标生成,用于黑盒库漏洞挖掘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模糊测试 大型语言模型 黑盒测试 漏洞挖掘 自动化测试 二进制分析 API覆盖率
📋 核心要点
- 现有模糊测试方法在处理闭源二进制库时,面临初始设置和维护成本高昂的挑战。
- LibLMFuzz利用LLM自主分析二进制文件,规划模糊测试策略,并自动生成驱动程序。
- 实验表明,LibLMFuzz在四个Linux库上实现了100%的API覆盖率,且大部分驱动程序首次执行正确。
📝 摘要(中文)
确定程序是否存在漏洞是网络安全和计算机科学中的一个基本问题。模糊测试作为一种流行的漏洞发现方法,相比其他策略具有若干优势,但也存在初始设置和持续维护的投入成本。当只有二进制库可用时,例如闭源和专有软件,模糊测试的选择变得更加复杂。为此,我们引入LibLMFuzz,该框架通过将代理式大型语言模型(LLM)与轻量级工具链(反汇编器/编译器/模糊器)相结合,自主分析剥离的二进制文件,规划模糊测试策略,生成驱动程序,并迭代地自我修复构建或运行时错误,从而降低了模糊测试闭源库的成本。在四个广泛使用的Linux库上进行测试,LibLMFuzz为所有558个可模糊测试的API函数生成了语法正确的驱动程序,在没有人为干预的情况下实现了100%的API覆盖率。在1601个合成驱动程序中,75.52%在首次执行时名义上是正确的。结果表明,LLM增强的中间件在降低模糊测试黑盒组件的成本方面具有前景,并为未来的研究工作奠定了基础。分支覆盖率方面存在未来的研究机会。
🔬 方法详解
问题定义:论文旨在解决对闭源二进制库进行高效模糊测试的问题。现有模糊测试方法需要大量人工干预来分析API接口、编写测试驱动程序,并且难以处理复杂的依赖关系和构建错误。这些痛点导致模糊测试的成本高昂,阻碍了其在闭源软件中的广泛应用。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大代码生成和理解能力,自动化模糊测试驱动程序的生成过程。LLM能够分析反汇编后的二进制代码,理解API的功能和参数,并生成相应的测试用例和驱动程序。这种方法可以显著减少人工干预,降低模糊测试的成本。
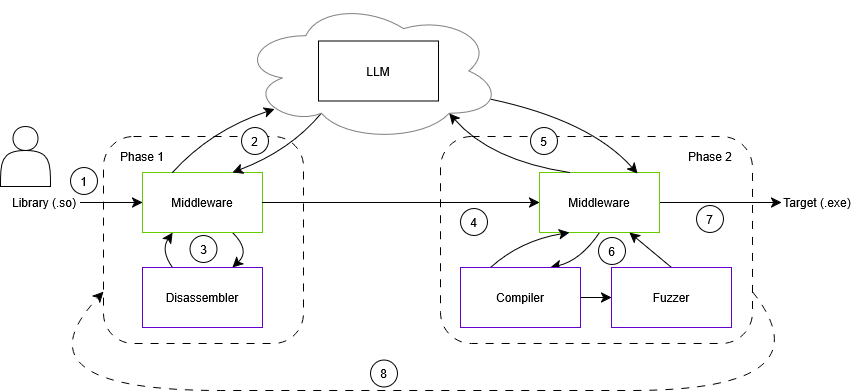
技术框架:LibLMFuzz框架包含以下主要模块:1) 反汇编器:将二进制库反汇编成汇编代码。2) LLM代理:分析汇编代码,识别API接口,并规划模糊测试策略。3) 驱动程序生成器:根据LLM的规划,生成C/C++驱动程序,用于调用API接口并提供测试输入。4) 编译器:将生成的驱动程序编译成可执行文件。5) 模糊器:使用生成的驱动程序对二进制库进行模糊测试,发现潜在的漏洞。6) 自我修复机制:在构建或运行时出现错误时,LLM会分析错误信息,并尝试修改驱动程序以解决问题。
关键创新:LibLMFuzz的关键创新在于将LLM集成到模糊测试流程中,实现了自动化驱动程序生成和自我修复。与传统的模糊测试方法相比,LibLMFuzz无需人工编写驱动程序,大大降低了模糊测试的成本。此外,LLM的自我修复能力可以自动解决构建和运行时错误,提高了模糊测试的效率。
关键设计:LLM代理的设计是关键。它需要能够理解反汇编代码,识别API接口,并生成有效的测试用例。论文中没有详细说明LLM的具体prompt工程和训练细节,这部分信息未知。框架使用标准的模糊测试工具(未知具体是哪个),并针对LLM生成的代码进行优化,以提高模糊测试的效率。自我修复机制通过分析编译器和运行时的错误信息,指导LLM修改驱动程序。
🖼️ 关键图片

📊 实验亮点
LibLMFuzz在四个广泛使用的Linux库上进行了测试,为所有558个可模糊测试的API函数生成了语法正确的驱动程序,实现了100%的API覆盖率,且无需人工干预。在1601个合成驱动程序中,75.52%在首次执行时名义上是正确的。这些结果表明,LLM在自动化模糊测试驱动程序生成方面具有显著的潜力。
🎯 应用场景
LibLMFuzz可应用于闭源软件、专有库和遗留系统的漏洞挖掘。该研究成果降低了黑盒组件模糊测试的门槛,使得安全研究人员和软件开发者能够更有效地发现和修复潜在的安全漏洞。未来,该技术有望推广到更广泛的软件安全领域,例如移动应用安全和物联网设备安全。
📄 摘要(原文)
A fundamental problem in cybersecurity and computer science is determining whether a program is free of bugs and vulnerabilities. Fuzzing, a popular approach to discovering vulnerabilities in programs, has several advantages over alternative strategies, although it has investment costs in the form of initial setup and continuous maintenance. The choice of fuzzing is further complicated when only a binary library is available, such as the case of closed-source and proprietary software. In response, we introduce LibLMFuzz, a framework that reduces costs associated with fuzzing closed-source libraries by pairing an agentic Large Language Model (LLM) with a lightweight tool-chain (disassembler/compiler/fuzzer) to autonomously analyze stripped binaries, plan fuzz strategies, generate drivers, and iteratively self-repair build or runtime errors. Tested on four widely-used Linux libraries, LibLMFuzz produced syntactically correct drivers for all 558 fuzz-able API functions, achieving 100% API coverage with no human intervention. Across the 1601 synthesized drivers, 75.52% were nominally correct on first execution. The results show that LLM-augmented middleware holds promise in reducing the costs of fuzzing black box components and provides a foundation for future research efforts. Future opportunities exist for research in branch coverage.