Omni-Thinker: Scaling Multi-Task RL in LLMs with Hybrid Reward and Task Scheduling
作者: Derek Li, Jiaming Zhou, Leo Maxime Brunswic, Abbas Ghaddar, Qianyi Sun, Liheng Ma, Yu Luo, Dong Li, Mark Coates, Jianye Hao, Yingxue Zhang
分类: cs.LG, cs.AI
发布日期: 2025-07-20 (更新: 2025-09-26)
💡 一句话要点
Omni-Thinker:通过混合奖励与任务调度扩展LLM中的多任务强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多任务学习 强化学习 大语言模型 后向迁移 混合奖励 任务调度 持续学习
📋 核心要点
- 现有LLM在处理结构化推理和开放式生成任务时面临挑战,通用人工智能的实现需要模型具备更强的多任务处理能力。
- Omni-Thinker框架通过混合奖励机制和后向迁移引导的任务调度,提升LLM在多任务强化学习中的性能和泛化能力。
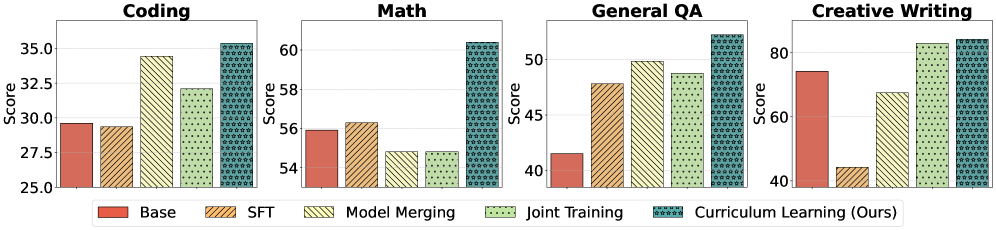
- 实验结果表明,Omni-Thinker在多个领域优于联合训练和模型合并等基线方法,验证了其有效性和优越性。
📝 摘要(中文)
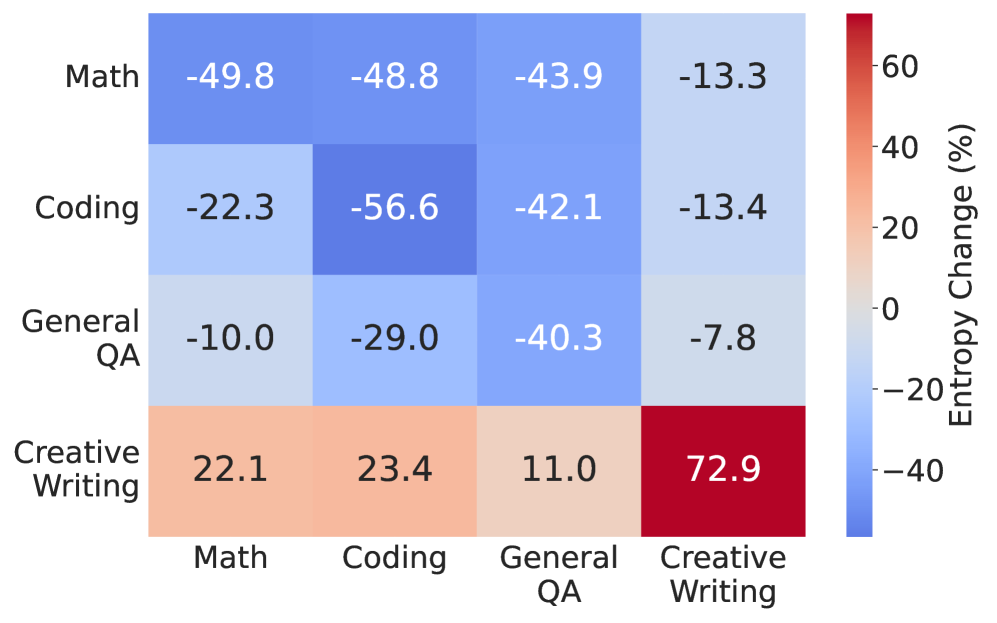
本文提出了Omni-Thinker,一个统一的强化学习(RL)框架,通过结合混合奖励和后向迁移引导的调度来扩展LLM以处理各种任务。混合奖励将基于规则的可验证信号与来自LLM-as-a-Judge的基于偏好的评估相结合,从而能够在确定性和主观领域进行学习。我们的调度器根据准确率后向迁移(BWT)对任务进行排序,减少遗忘并提高多任务性能。在四个领域进行的实验表明,相对于联合训练,性能提升了6.2%,相对于模型合并,性能提升了12.4%。此外,我们证明了对准确率迁移的简单假设可以准确预测课程结果,而熵动力学解释了由于生成任务引起的偏差。这些发现强调了BWT感知调度和混合监督对于扩展基于RL的后训练以实现通用LLM的重要性。
🔬 方法详解
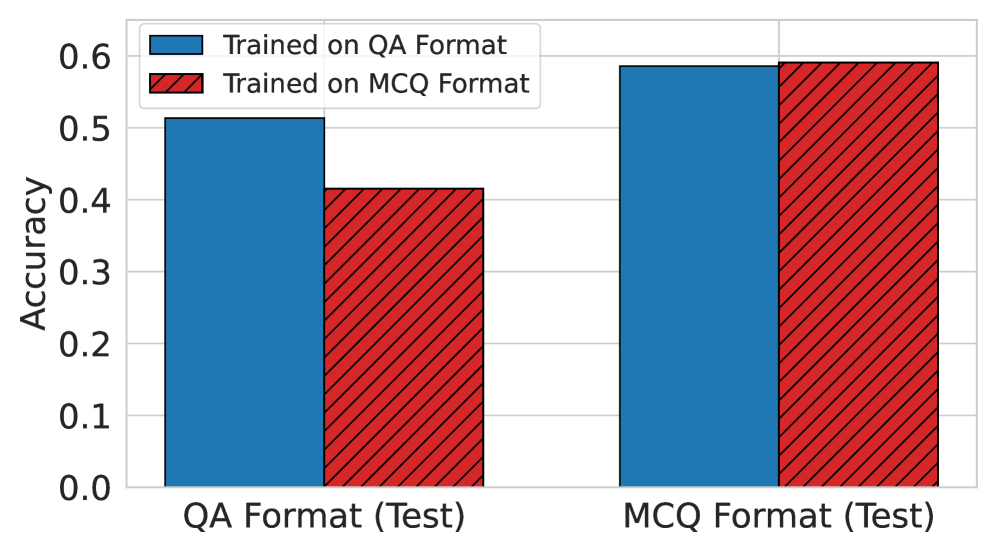
问题定义:现有的大语言模型在多任务学习中面临着灾难性遗忘的问题,即在学习新任务时会忘记之前学习的任务。此外,对于一些主观性较强的任务,难以设计有效的奖励函数来指导模型的学习。
核心思路:Omni-Thinker的核心思路是结合混合奖励和后向迁移引导的任务调度。混合奖励结合了规则奖励和基于LLM偏好的奖励,从而能够处理确定性和主观性任务。后向迁移引导的任务调度则通过优先训练对之前任务影响较小的任务,来减少灾难性遗忘。
技术框架:Omni-Thinker框架主要包含三个模块:1) 混合奖励模块,用于生成针对不同任务的混合奖励信号;2) 任务调度模块,根据准确率后向迁移(BWT)对任务进行排序;3) 基于强化学习的LLM训练模块,使用混合奖励和任务调度策略来训练LLM。
关键创新:Omni-Thinker的关键创新在于提出了混合奖励机制和后向迁移引导的任务调度策略。混合奖励机制能够有效处理确定性和主观性任务,而后向迁移引导的任务调度策略能够有效减少灾难性遗忘。
关键设计:混合奖励的设计需要仔细考虑规则奖励和基于LLM偏好奖励的权重。任务调度策略需要准确估计任务之间的后向迁移关系。强化学习训练过程需要选择合适的算法和超参数,例如PPO等。具体损失函数的设计取决于所使用的强化学习算法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Omni-Thinker在四个领域均取得了显著的性能提升。相对于联合训练,性能提升了6.2%,相对于模型合并,性能提升了12.4%。此外,论文还验证了对准确率迁移的简单假设可以准确预测课程结果,进一步证明了Omni-Thinker的有效性。
🎯 应用场景
Omni-Thinker具有广泛的应用前景,可用于训练能够处理各种任务的通用人工智能模型。例如,可以应用于智能客服、自动驾驶、游戏AI等领域。通过持续学习和适应新任务,Omni-Thinker有望推动人工智能技术的发展,并为人类带来更多便利。
📄 摘要(原文)
The pursuit of general-purpose artificial intelligence depends on large language models (LLMs) that can handle both structured reasoning and open-ended generation. We present Omni-Thinker, a unified reinforcement learning (RL) framework that scales LLMs across diverse tasks by combining hybrid rewards with backward-transfer-guided scheduling. Hybrid rewards integrate rule-based verifiable signals with preference-based evaluations from an LLM-as-a-Judge, enabling learning in both deterministic and subjective domains. Our scheduler orders tasks according to accuracy backward transfer (BWT), reducing forgetting and improving multi-task performance. Experiments across four domains show gains of 6.2% over joint training and 12.4% over model merging. Moreover, we demonstrate that simple assumptions on accuracy transfer yield accurate predictions of curriculum outcomes, with entropy dynamics explaining deviations due to generative tasks. These findings underscore the importance of BWT-aware scheduling and hybrid supervision for scaling RL-based post-training toward general-purpose LLMs.