GRID: Scalable Task-Agnostic Prompt-Based Continual Learning for Language Models
作者: Anushka Tiwari, Sayantan Pal, Rohini K. Srihari, Kaiyi Ji
分类: cs.LG, cs.AI
发布日期: 2025-07-19 (更新: 2025-10-01)
💡 一句话要点
GRID:面向语言模型的可扩展、任务无关的Prompt持续学习框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 Prompt学习 语言模型 任务无关 后向迁移
📋 核心要点
- 现有Prompt持续学习方法在任务无关推理时,早期任务性能显著下降,限制了模型的实用性。
- GRID框架通过解码机制增强后向迁移,并利用梯度引导的Prompt选择策略压缩Prompt,提升模型性能和可扩展性。
- 实验表明,GRID在长序列任务中提高了平均准确率和后向迁移能力,同时显著降低了Prompt内存占用。
📝 摘要(中文)
基于Prompt的持续学习(CL)为跨任务序列调整大型语言模型(LLM)提供了一种参数高效的方法。然而,大多数现有方法依赖于任务感知的推理,并维护一组不断增长的任务特定Prompt,这带来了两个主要挑战:(1)在任务无关的推理下,早期任务的性能严重下降;(2)由于任务序列增长,Prompt内存累积导致的可扩展性有限。在本文中,我们提出了GRID,一个旨在解决这些挑战的统一框架。GRID结合了一种解码机制,通过利用代表性输入、自动任务识别和约束解码来增强后向迁移。此外,它采用梯度引导的Prompt选择策略,将信息量较少的Prompt压缩成单个聚合表示,从而确保可扩展且内存高效的持续学习。在长序列和负迁移基准上的大量实验表明,GRID提高了平均准确率和后向迁移,实现了有竞争力的前向迁移,并大幅降低了Prompt内存使用量。
🔬 方法详解
问题定义:现有的基于Prompt的持续学习方法在任务无关的推理场景下,会面临灾难性遗忘问题,导致模型在早期任务上的性能急剧下降。此外,随着任务数量的增加,需要存储的Prompt数量也会线性增长,造成严重的内存负担,限制了模型在实际应用中的可扩展性。
核心思路:GRID的核心思路是通过引入一种新的解码机制来增强后向迁移能力,从而缓解灾难性遗忘问题。同时,利用梯度引导的Prompt选择策略,将冗余或信息量较少的Prompt进行压缩,减少Prompt的存储空间,提高模型的可扩展性。这样既能保证模型在所有任务上的性能,又能降低内存占用。
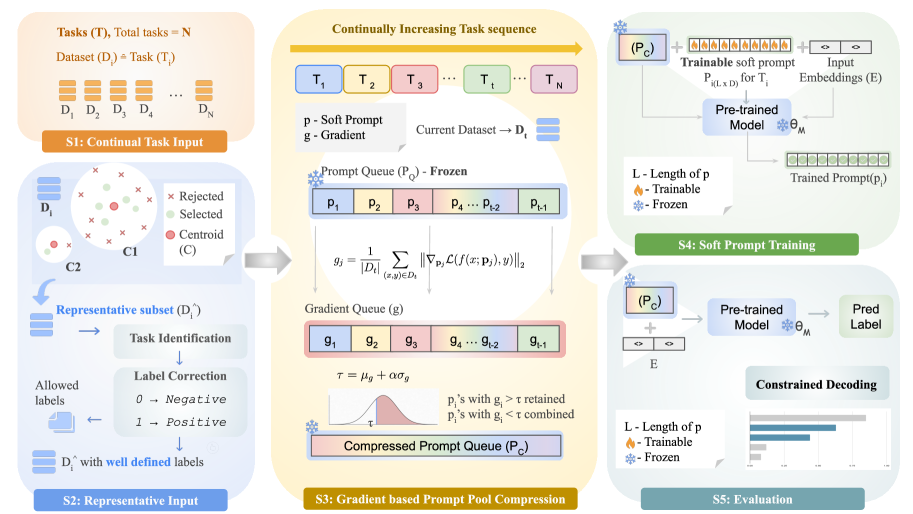
技术框架:GRID框架主要包含三个核心模块:(1)解码机制,利用代表性输入、自动任务识别和约束解码来增强后向迁移;(2)梯度引导的Prompt选择策略,用于压缩Prompt,减少内存占用;(3)一个统一的Prompt池,用于存储和管理Prompt。在训练过程中,模型首先利用解码机制学习新任务,然后利用梯度引导的Prompt选择策略压缩Prompt,最后更新Prompt池。在推理过程中,模型根据输入自动识别任务,并选择相应的Prompt进行推理。
关键创新:GRID的关键创新在于其任务无关的Prompt压缩和后向迁移增强机制。传统的Prompt持续学习方法通常需要为每个任务维护一个独立的Prompt,而GRID通过梯度引导的Prompt选择策略,可以将多个Prompt压缩成一个,从而大大减少了内存占用。此外,GRID的解码机制可以有效地缓解灾难性遗忘问题,提高模型在早期任务上的性能。
关键设计:GRID的解码机制利用代表性输入来指导模型的学习,通过自动任务识别模块来确定当前输入属于哪个任务,并利用约束解码来限制模型的输出,从而增强后向迁移能力。梯度引导的Prompt选择策略则根据Prompt的梯度信息来评估其重要性,并将重要性较低的Prompt进行压缩。具体的压缩方法未知,论文中可能没有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GRID在长序列和负迁移基准测试中,显著提高了平均准确率和后向迁移能力,同时实现了具有竞争力的前向迁移性能。更重要的是,GRID大幅降低了Prompt内存使用量,使其在实际应用中更具优势。具体提升幅度未知,需要查阅论文原文。
🎯 应用场景
GRID框架可应用于各种需要持续学习的自然语言处理任务,例如对话系统、机器翻译、文本分类等。特别是在资源受限的设备上,GRID的内存高效特性使其具有重要的应用价值。未来,该研究可以进一步扩展到多模态持续学习领域,例如图像描述、视频理解等。
📄 摘要(原文)
Prompt-based continual learning (CL) provides a parameter-efficient approach for adapting large language models (LLMs) across task sequences. However, most existing methods rely on task-aware inference and maintain a growing set of task-specific prompts, which introduces two major challenges: (1) severe performance degradation on earlier tasks under task-agnostic inference, and (2) limited scalability due to prompt memory accumulation as task sequences grow. In this paper, we present GRID, a unified framework designed to address these challenges. GRID incorporates a decoding mechanism that enhances backward transfer by leveraging representative inputs, automatic task identification, and constrained decoding. Furthermore, it employs a gradient-guided prompt selection strategy to compress less informative prompts into a single aggregated representation, ensuring scalable and memory-efficient continual learning. Extensive experiments on long-sequence and negative transfer benchmarks show that GRID improves average accuracy and backward transfer, achieves competitive forward transfer, and substantially reduces prompt memory usage.