Exploring the Dynamic Scheduling Space of Real-Time Generative AI Applications on Emerging Heterogeneous Systems
作者: Rachid Karami, Rajeev Patwari, Hyoukjun Kwon, Ashish Sirasao
分类: cs.LG
发布日期: 2025-07-19
💡 一句话要点
针对异构系统上实时生成式AI应用,探索动态调度策略以优化性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实时生成式AI 异构计算 动态调度 片上系统 大型语言模型
📋 核心要点
- 现有方法难以兼顾实时生成式AI应用对低延迟和高并发的需求,尤其是在异构计算平台上。
- 论文核心在于探索不同的调度策略,以优化异构SoC上实时生成式AI工作负载的性能。
- 实验表明,合理的调度策略能显著降低截止时间违反率,并提升LLM的token生成速度。
📝 摘要(中文)
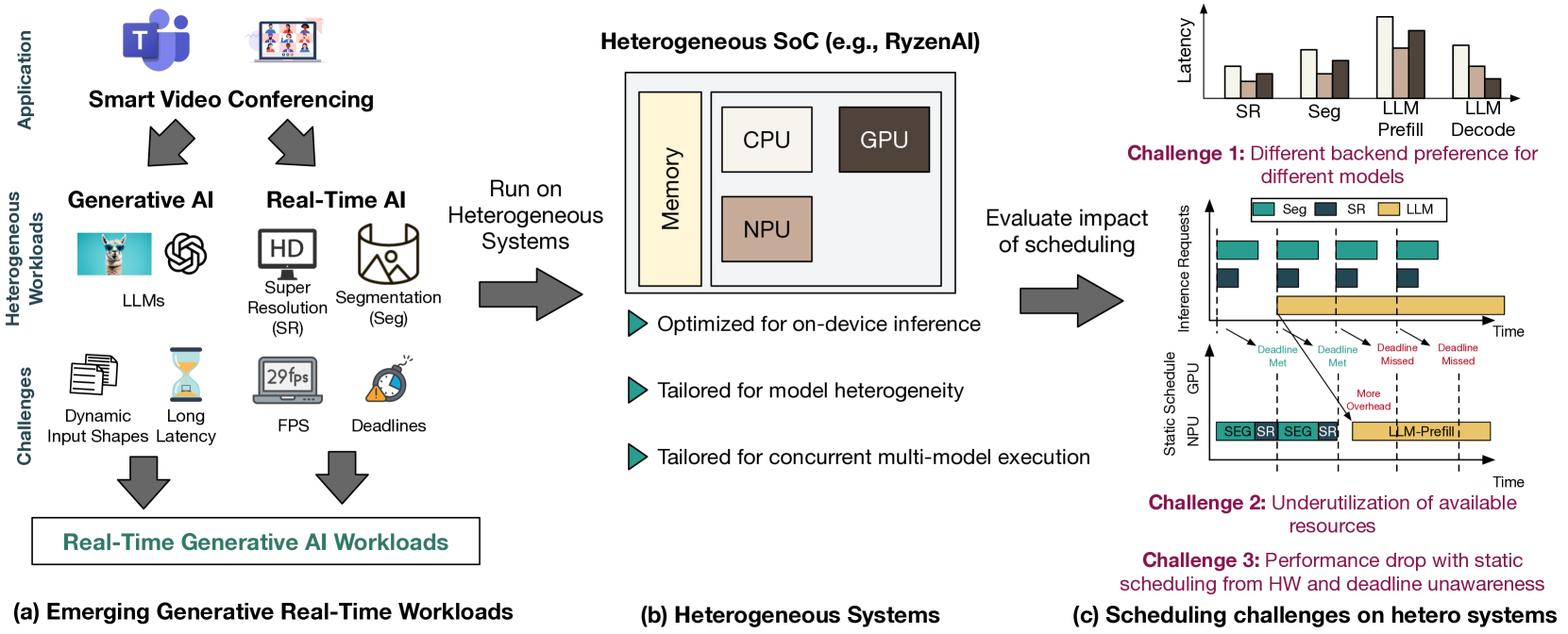
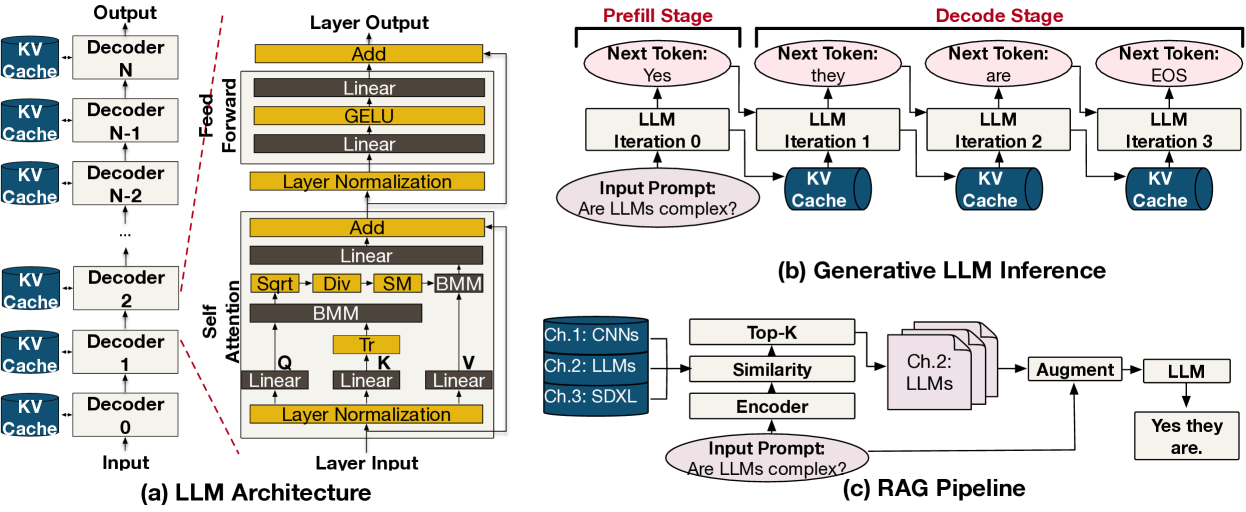
将生成式AI模型,特别是大型语言模型(LLMs),集成到实时多模型AI应用(如视频会议和游戏)中,催生了一种新的工作负载:实时生成式AI(RTGen)。这些工作负载结合了生成模型的计算密集性和动态执行模式,以及实时推理的严格延迟和并发约束。为了满足RTGen工作负载的多样化需求,现代边缘平台越来越多地采用集成CPU、GPU和NPU的异构片上系统(SoC)架构。尽管异构SoC具有潜力,但RTGen工作负载在此类平台上的调度空间复杂性和性能影响仍未得到充分探索。本文在AMD最新的异构SoC Ryzen AI上对RTGen工作负载进行了全面表征。我们构建了受行业用例启发的真实多模型场景,并分析了所有可用后端上的模型性能。利用这些数据,我们评估了五种调度策略及其对实时指标(例如,截止时间违反率)和LLM性能(例如,首个token生成时间和每秒token数)的影响。结果表明,调度决策会显著影响工作负载性能(例如,平均导致截止时间违反率相差41.7%),并强调需要感知工作负载动态和硬件异构性的调度策略。我们的发现强调了工作负载感知的动态异构调度在实现高性能、设备端RTGen应用中的重要性。
🔬 方法详解
问题定义:论文旨在解决在异构SoC上运行实时生成式AI(RTGen)应用时,如何有效地调度计算资源以满足严格的延迟和并发约束的问题。现有方法在处理此类工作负载时,未能充分利用异构硬件的优势,并且缺乏对工作负载动态性的感知,导致性能瓶颈和截止时间违反。
核心思路:论文的核心思路是通过探索不同的调度策略,充分利用异构SoC(CPU、GPU、NPU)的计算能力,并根据RTGen工作负载的动态特性进行自适应调整。目标是找到一种调度策略,能够在满足实时性要求的同时,最大化LLM的性能指标(如token生成速度)。
技术框架:论文的技术框架主要包括以下几个步骤:1) 构建基于行业用例的真实多模型RTGen场景;2) 在AMD Ryzen AI异构SoC上,针对不同的计算后端(CPU、GPU、NPU)进行模型性能分析;3) 评估五种不同的调度策略,包括静态和动态策略;4) 评估调度策略对实时指标(截止时间违反率)和LLM性能指标(首个token生成时间、每秒token数)的影响。
关键创新:论文的关键创新在于对RTGen工作负载在异构SoC上的调度空间进行了全面的探索和评估。通过实验分析,揭示了不同调度策略对实时性和LLM性能的显著影响,强调了工作负载感知和动态异构调度的重要性。与现有方法相比,该研究更关注实际应用场景,并提供了具体的调度策略选择建议。
关键设计:论文的关键设计包括:1) 构建了基于视频会议和游戏等实际用例的多模型RTGen场景;2) 选择了AMD Ryzen AI作为目标异构平台,并分析了不同后端上的模型性能;3) 评估了五种调度策略,包括FIFO、Round Robin、EDF等,并针对RTGen工作负载的特点进行了调整;4) 使用截止时间违反率、首个token生成时间和每秒token数等指标,对调度策略的性能进行了量化评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,不同的调度策略对RTGen工作负载的性能有显著影响,平均导致截止时间违反率相差41.7%。某些动态调度策略能够显著降低截止时间违反率,并提升LLM的token生成速度。该研究强调了工作负载感知和动态异构调度在实现高性能、设备端RTGen应用中的重要性。
🎯 应用场景
该研究成果可应用于各种需要实时生成式AI能力的场景,如智能视频会议、云游戏、智能助手、机器人等。通过优化调度策略,可以提升用户体验,降低延迟,并提高系统的资源利用率。未来的研究方向包括开发更智能的自适应调度算法,以及探索更高效的异构计算架构。
📄 摘要(原文)
The integration of generative AI models, particularly large language models (LLMs), into real-time multi-model AI applications such as video conferencing and gaming is giving rise to a new class of workloads: real-time generative AI (RTGen). These workloads combine the compute intensity and dynamic execution patterns of generative models with the stringent latency and concurrency constraints of real-time inference. To meet the diverse demands of RTGen workloads, modern edge platforms increasingly adopt heterogeneous system-on-chip (SoC) architectures that integrate CPUs, GPUs, and NPUs. Despite the potential of heterogeneous SoC, the scheduling space complexity and performance implications of RTGen workloads on such platforms remain underexplored. In this work, we perform a comprehensive characterization of RTGen workloads on AMD's latest heterogeneous SoC, Ryzen AI. We construct realistic multi-model scenarios inspired by industry use cases and profile model performance across all available backends. Using this data, we evaluate five scheduling policies and their impact on both real-time metrics (e.g., deadline violation rate) and LLM performance (e.g., time-to-first-token and tokens-per-second). Our results show that scheduling decisions significantly affect workload performance (e.g., leading to a 41.7% difference in deadline violation rates on average), and highlight the need for scheduling strategies that are aware of workload dynamics and hardware heterogeneity. Our findings underscore the importance of workload-aware, dynamic heterogeneous scheduling in enabling high-performance, on-device RTGen applications.