PolyServe: Efficient Multi-SLO Serving at Scale
作者: Kan Zhu, Haiyang Shi, Le Xu, Jiaxin Shan, Arvind Krishnamurthy, Baris Kasikci, Liguang Xie
分类: cs.DC, cs.LG
发布日期: 2025-07-17
💡 一句话要点
PolyServe:一种高效的大规模多服务质量等级(SLO)服务系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模服务 服务质量等级(SLO) 语言模型 调度策略 资源分配 尾部延迟 自动缩放
📋 核心要点
- 现有LLM服务系统无法有效区分和处理具有不同延迟敏感度要求的请求,导致资源利用率低下和用户体验不佳。
- PolyServe通过将请求按SLO分组,并动态调度到服务器集群的不同子集,实现了细粒度的资源分配和负载均衡。
- 实验表明,PolyServe相比现有策略,goodput提升了1.23倍,达到了最佳goodput的92.5%,显著提升了系统性能。
📝 摘要(中文)
大型语言模型(LLM)的进步导致了大量基于LLM的应用涌现。这些应用对token生成的延迟有不同的要求。简单地将工作负载分类为延迟敏感型(LS)或尽力而为型(BE)忽略了延迟敏感型类别中的细微差别,导致次优的用户体验和调度机会。然而,高效地服务具有多个SLO要求的请求带来了巨大的挑战。首先,一个批次中的所有请求同时生成新的token,这可能使它们与其不同的SLO要求不一致。此外,虽然现有系统侧重于自动缩放以处理各种整体请求速率,但SLO的多样性需要在这些SLO层之间进行细粒度的自动缩放。最后,与LS/BE场景(BE请求可以随时中止以确保LS请求的SLO实现)不同,具有不同延迟敏感SLO的请求不能容忍长时间的延迟,并且必须控制尾部延迟。为了应对这些挑战,我们提出了一种新颖的大规模多SLO调度策略PolyServe,该策略在保持高SLO实现的同时最大化吞吐量。PolyServe首先根据每个token的延迟要求将请求分组到多个桶中,然后将每个桶调度到服务器群的一部分。PolyServe将请求路由到负载最高但仍可实现SLO的服务器,以创建有助于自动缩放的负载梯度。为了提高利用率,当松散SLO请求自己的服务器饱和时,PolyServe允许它们共享更严格SLO的实例。PolyServe使用分析数据来指导调度决策,并通过请求等待时间感知的调度、动态分块和连续分块预填充预测来管理尾部延迟。与现有策略相比,PolyServe实现了1.23倍的goodput增益,达到了高达92.5%的最佳goodput。
🔬 方法详解
问题定义:论文旨在解决大规模LLM服务中,不同请求具有不同服务质量等级(SLO)需求时,如何高效调度和资源分配的问题。现有方法通常将请求粗略地分为延迟敏感型和尽力而为型,无法满足细粒度的SLO需求,导致资源利用率低,尾部延迟高等问题。
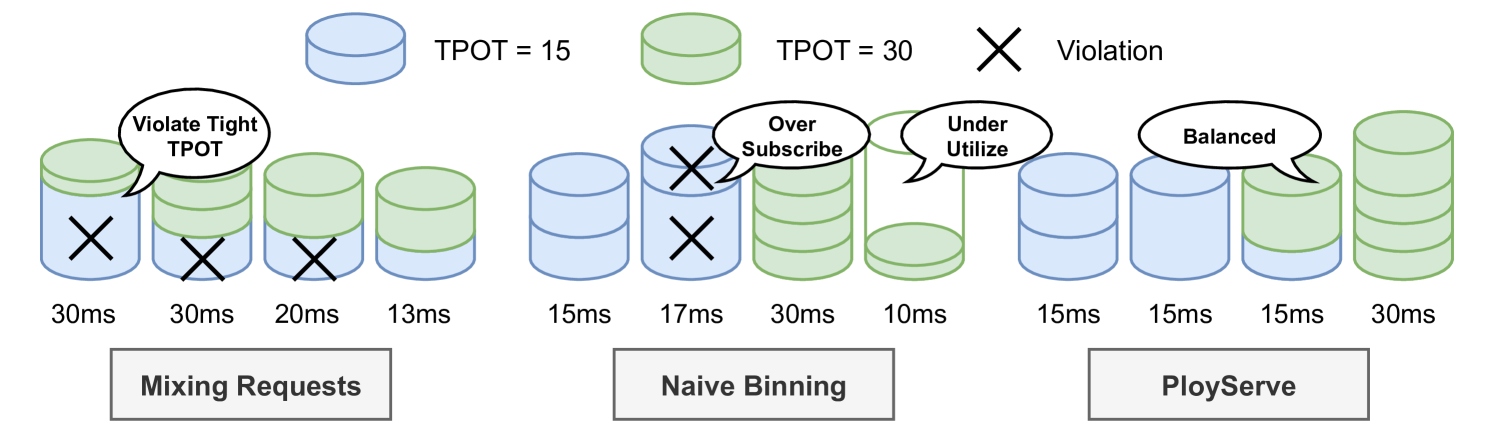
核心思路:PolyServe的核心思路是根据请求的SLO要求,将其划分到不同的“桶”中,然后将每个桶调度到服务器集群的子集上。通过这种方式,系统可以针对不同SLO的请求进行精细化的资源分配和调度,从而提高整体的吞吐量和资源利用率,同时保证各个SLO的达成。
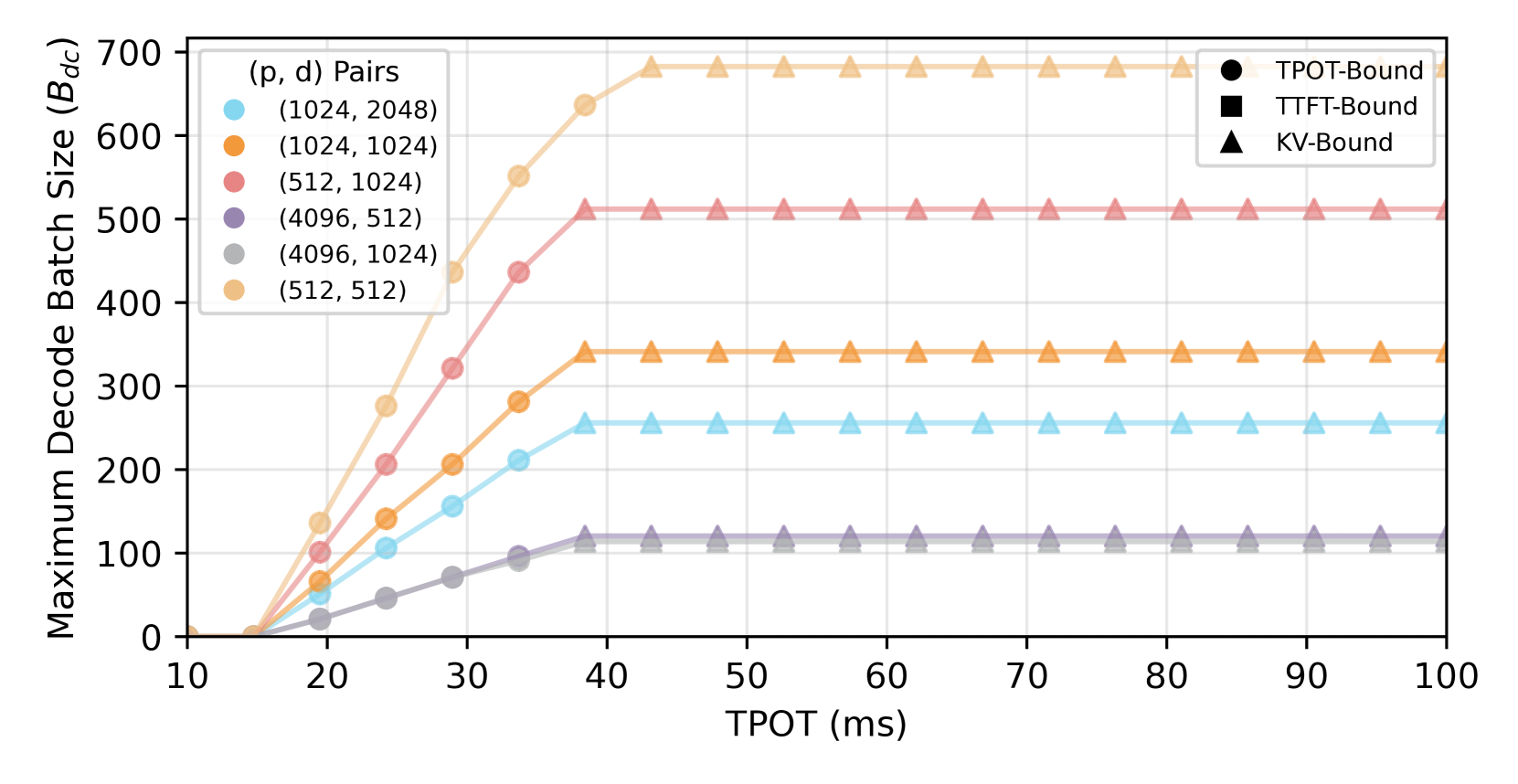
技术框架:PolyServe的整体框架包括以下几个主要模块:1) 请求分类:根据请求的per-token延迟要求,将其分配到不同的SLO桶中。2) 调度器:负责将每个SLO桶的请求调度到相应的服务器子集上。调度器会优先选择负载较高但仍能满足SLO的服务器,以形成负载梯度,方便自动扩缩容。3) 资源管理器:监控服务器的负载和SLO达成情况,并根据需要进行自动扩缩容。4) 尾部延迟控制器:通过请求等待时间感知的调度、动态分块和连续分块预填充预测等技术,控制尾部延迟。
关键创新:PolyServe的关键创新在于其细粒度的多SLO调度策略。与传统的粗粒度调度方法相比,PolyServe能够更好地适应不同SLO请求的需求,从而提高资源利用率和系统吞吐量。此外,PolyServe还通过负载梯度、动态分块和连续分块预填充预测等技术,进一步优化了系统的性能。
关键设计:PolyServe的关键设计包括:1) SLO桶的划分标准:根据per-token延迟要求进行划分,可以根据实际应用场景进行调整。2) 调度器的负载均衡策略:优先选择负载较高但仍能满足SLO的服务器,以形成负载梯度。3) 尾部延迟控制器的参数设置:需要根据实际系统负载和请求特征进行调整,以达到最佳的尾部延迟控制效果。
🖼️ 关键图片

📊 实验亮点
PolyServe在实验中表现出色,与现有策略相比,实现了1.23倍的goodput增益,并且达到了高达92.5%的最佳goodput。这些结果表明,PolyServe能够有效地提高大规模LLM服务系统的性能和资源利用率,同时保证不同SLO的达成。
🎯 应用场景
PolyServe适用于需要支持多种服务质量等级(SLO)的大规模语言模型服务场景。例如,在线客服、内容生成、代码生成等应用,它们对延迟的要求各不相同。通过PolyServe,可以根据不同应用的延迟需求进行精细化的资源分配和调度,从而提高整体的服务质量和用户体验。该研究对于构建高效、可扩展的LLM服务系统具有重要的实际价值和未来影响。
📄 摘要(原文)
Advances in Large Language Models (LLMs) have led to a surge of LLM-powered applications. These applications have diverse token-generation latency requirements. As a result, simply classifying workloads as latency-sensitive (LS) or best-effort (BE) overlooks the nuances within the latency-sensitive category and results in suboptimal user experiences and scheduling opportunities. However, efficiently serving requests with multiple SLO requirements poses significant challenges. First, all requests within a batch generate new tokens simultaneously, which can misalign them with their distinct SLO requirements. Moreover, while existing systems focus on auto-scaling for handling various overall request rates, the diversity of SLOs necessitates fine-grained auto-scaling among these SLO tiers. Finally, unlike LS/BE scenarios, where BE requests can be aborted at any time to ensure the SLO attainment of LS requests, those with different latency-sensitive SLOs cannot tolerate prolonged delays, and tail latency must be controlled. To tackle these challenges, we propose PolyServe, a novel multi-SLO scheduling policy at scale that maintains high SLO attainment while maximizing throughput. PolyServe first groups requests into multiple bins based on their per-token latency requirement, then schedules each bin to a subset of the server fleet. PolyServe routes requests to the highest-load but still SLO-attainable server to create a load gradient that facilitates auto-scaling. To increase utilization, PolyServe permits looser-SLO requests to share tighter-SLO instances when their own servers are saturated. PolyServe uses profiling data to guide scheduling decisions and manage tail latency through request-wait-time-aware scheduling, dynamic chunking, and continuous chunked prefill prediction. PolyServe achieves 1.23x goodput gain compared to existing policies, achieving up to 92.5% of optimal goodput.