Learning to summarize user information for personalized reinforcement learning from human feedback
作者: Hyunji Nam, Yanming Wan, Mickel Liu, Jianxun Lian, Peter Ahnn, Natasha Jaques
分类: cs.LG, cs.AI
发布日期: 2025-07-17 (更新: 2025-09-26)
备注: 10 pages for main text, 9 pages for appendix
💡 一句话要点
提出PLUS框架,通过用户偏好摘要实现个性化强化学习,提升LLM用户对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化强化学习 用户偏好建模 文本摘要 奖励模型 大型语言模型
📋 核心要点
- 现有RLHF方法忽略了用户偏好的差异性,使用单一奖励模型,无法实现LLM的个性化对齐。
- PLUS框架通过学习生成用户偏好摘要,并以此调节奖励模型,实现个性化的反馈预测和模型训练。
- 实验表明,PLUS在奖励模型准确性、新用户泛化和零样本个性化方面均优于现有方法。
📝 摘要(中文)
随着大型语言模型(LLM)AI助手在日常使用中的扩展,个性化响应以适应不同用户的偏好和目标变得越来越重要。虽然基于人类反馈的强化学习(RLHF)在改进LLM以使其更具帮助性和流畅性方面是有效的,但它没有考虑到用户之间的差异,因为它使用单一奖励模型对整个用户群体进行建模,这意味着它假设每个人的偏好都是相同的。我们提出了一种新颖的框架,即使用摘要进行偏好学习(PLUS),它使用强化学习(RL)来学习生成每个用户的偏好、特征和过去对话的基于文本的摘要。这些摘要调节奖励模型,使其能够对每个用户重视的响应类型做出个性化预测。用户摘要模型和奖励模型同时训练,从而创建一个在线协同适应循环。我们表明,与标准的Bradley-Terry模型相比,PLUS生成的摘要捕捉了用户偏好的各个方面,使奖励模型的准确性提高了11-77%。PLUS的关键优势在于:(1)对新用户和对话主题具有强大的性能,比最佳个性化RLHF技术提高了25%;(2)使用最先进的专有模型(如GPT-4)进行零样本个性化(例如,PLUS摘要条件响应的胜率为72%,而默认GPT-4o的胜率为28%);(3)从超出偏好标签的灵活用户上下文中学习;(4)可解释的用户表示,从而在多元化的LLM对齐中实现更大的透明度和用户控制。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法在训练大型语言模型(LLM)时,通常采用单一的奖励模型来代表所有用户的偏好。这种方法忽略了用户之间的个性化差异,导致LLM无法针对不同用户的需求和偏好进行优化,从而限制了LLM在实际应用中的效果。现有方法难以捕捉用户偏好的细微差别,并且缺乏对用户偏好的可解释性。
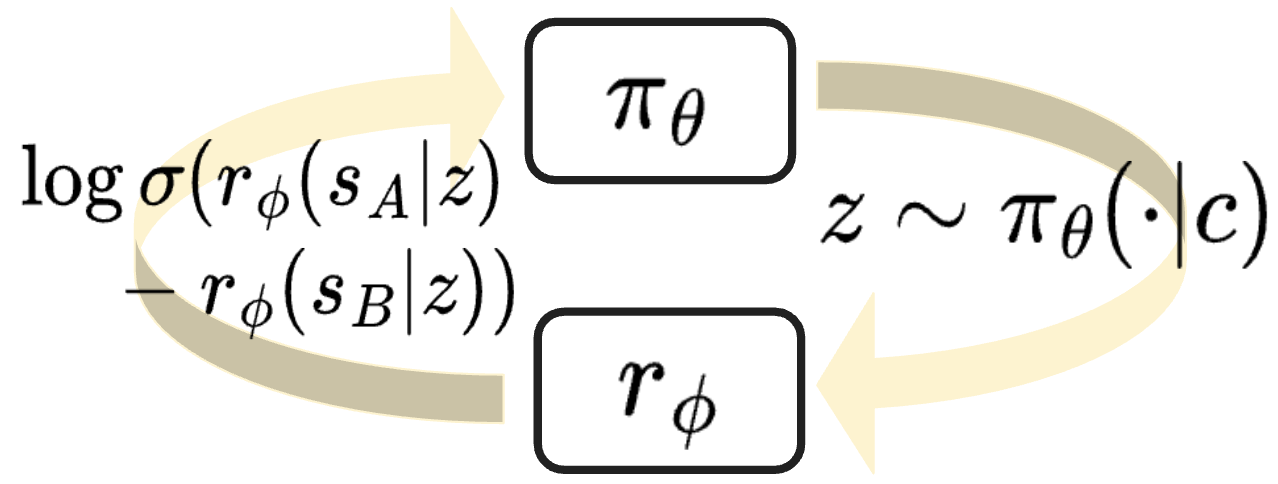
核心思路:PLUS框架的核心思路是为每个用户生成一个文本摘要,该摘要概括了用户的偏好、特征以及历史对话信息。这个摘要被用作奖励模型的输入,从而使奖励模型能够根据用户的个性化信息进行预测。通过同时训练用户摘要模型和奖励模型,PLUS框架实现了一个在线协同适应循环,使得模型能够不断学习和优化用户偏好。
技术框架:PLUS框架包含两个主要模块:用户摘要模型和奖励模型。用户摘要模型负责根据用户的历史对话和相关信息生成文本摘要,该摘要是对用户偏好的一个总结。奖励模型则接收用户摘要和LLM生成的响应作为输入,并预测该响应对用户的吸引力。这两个模型在训练过程中相互作用,用户摘要模型不断优化摘要的质量,而奖励模型则利用摘要来提高预测的准确性。整个框架采用强化学习进行训练,目标是最大化LLM生成的响应对用户的满意度。
关键创新:PLUS框架的关键创新在于引入了用户偏好摘要的概念,并将该摘要用于调节奖励模型。这种方法能够有效地捕捉用户之间的个性化差异,从而实现LLM的个性化对齐。与传统的RLHF方法相比,PLUS框架能够更好地适应新用户和新的对话主题,并且具有更强的可解释性。此外,PLUS框架还支持从灵活的用户上下文中学习,而不仅仅局限于偏好标签。
关键设计:用户摘要模型可以使用各种文本生成模型,例如Transformer模型。奖励模型可以使用Bradley-Terry模型或其他排序模型。损失函数通常包括奖励预测的损失和用户摘要生成的损失。在训练过程中,可以使用强化学习算法,例如Proximal Policy Optimization (PPO),来优化用户摘要模型和奖励模型。关键参数包括摘要的长度、奖励模型的结构以及强化学习算法的超参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PLUS框架在奖励模型准确性方面取得了显著提升,相比标准Bradley-Terry模型提高了11-77%。在新用户和对话主题的泛化能力方面,PLUS框架比最佳个性化RLHF技术提高了25%。此外,PLUS框架在零样本个性化方面也表现出色,使用GPT-4o模型时,PLUS摘要条件响应的胜率为72%,而默认GPT-4o的胜率仅为28%。
🎯 应用场景
PLUS框架具有广泛的应用前景,可以应用于各种需要个性化AI助手的场景,例如智能客服、个性化推荐系统、教育辅导等。通过学习和理解用户的偏好,PLUS框架可以使AI助手更好地满足用户的需求,提高用户满意度,并最终提升AI助手的实用价值。该研究为实现更智能、更个性化的AI系统奠定了基础。
📄 摘要(原文)
As everyday use cases of large language model (LLM) AI assistants have expanded, it is becoming increasingly important to personalize responses to align to different users' preferences and goals. While reinforcement learning from human feedback (RLHF) is effective at improving LLMs to be generally more helpful and fluent, it does not account for variability across users, as it models the entire user population with a single reward model, meaning it assumes that everyone's preferences are the same. We present a novel framework, Preference Learning Using Summarization (PLUS), that uses reinforcement learning (RL) to learn to produce text-based summaries of each user's preferences, characteristics, and past conversations. These summaries condition the reward model, enabling it to make personalized predictions about the types of responses valued by each user. Both the user-summarization model and reward model are trained simultaneously, creating an online co-adaptation loop. We show that in contrast to the standard Bradley-Terry model, summaries produced by PLUS capture diverse aspects of user preferences, achieving a 11-77% improvement in reward model accuracy. Key strengths of PLUS are: (1) robust performance with new users and conversation topics, achieving a 25% improvement over the best personalized RLHF technique; (2) zero-shot personalization with state-of-the-art proprietary models like GPT-4 (e.g., PLUS-summary-conditioned responses achieved a 72% win rate compared to 28% for default GPT-4o); (3) learning from flexible user contexts beyond preference labels, and (4) interpretable representation of users, enabling greater transparency and user control in pluralistic LLM alignment.