Apple Intelligence Foundation Language Models: Tech Report 2025
作者: Ethan Li, Anders Boesen Lindbo Larsen, Chen Zhang, Xiyou Zhou, Jun Qin, Dian Ang Yap, Narendran Raghavan, Xuankai Chang, Margit Bowler, Eray Yildiz, John Peebles, Hannah Gillis Coleman, Matteo Ronchi, Peter Gray, Keen You, Anthony Spalvieri-Kruse, Ruoming Pang, Reed Li, Yuli Yang, Emad Soroush, Zhiyun Lu, Crystal Xiao, Rong Situ, Jordan Huffaker, David Griffiths, Zaid Ahmed, Peng Zhang, Daniel Parilla, Asaf Liberman, Jennifer Mallalieu, Parsa Mazaheri, Qibin Chen, Manjot Bilkhu, Aonan Zhang, Eric Wang, Dave Nelson, Michael FitzMaurice, Thomas Voice, Jeremy Liu, Josh Shaffer, Shiwen Zhao, Prasanth Yadla, Farzin Rasteh, Pengsheng Guo, Arsalan Farooq, Jeremy Snow, Stephen Murphy, Tao Lei, Minsik Cho, George Horrell, Sam Dodge, Lindsay Hislop, Sumeet Singh, Alex Dombrowski, Aiswarya Raghavan, Sasha Sirovica, Mandana Saebi, Faye Lao, Max Lam, TJ Lu, Zhaoyang Xu, Karanjeet Singh, Marc Kirchner, David Mizrahi, Rajat Arora, Haotian Zhang, Henry Mason, Lawrence Zhou, Yi Hua, Ankur Jain, Felix Bai, Joseph Astrauskas, Floris Weers, Josh Gardner, Mira Chiang, Yi Zhang, Pulkit Agrawal, Tony Sun, Quentin Keunebroek, Matthew Hopkins, Bugu Wu, Tao Jia, Chen Chen, Xingyu Zhou, Nanzhu Wang, Peng Liu, Ruixuan Hou, Rene Rauch, Yuan Gao, Afshin Dehghan, Jonathan Janke, Zirui Wang, Cha Chen, Xiaoyi Ren, Feng Nan, Josh Elman, Dong Yin, Yusuf Goren, Jeff Lai, Yiran Fei, Syd Evans, Muyang Yu, Guoli Yin, Yi Qin, Erin Feldman, Isha Garg, Aparna Rajamani, Karla Vega, Walker Cheng, TJ Collins, Hans Han, Raul Rea Menacho, Simon Yeung, Sophy Lee, Phani Mutyala, Ying-Chang Cheng, Zhe Gan, Sprite Chu, Justin Lazarow, Alessandro Pappalardo, Federico Scozzafava, Jing Lu, Erik Daxberger, Laurent Duchesne, Jen Liu, David Güera, Stefano Ligas, Mary Beth Kery, Brent Ramerth, Ciro Sannino, Marcin Eichner, Haoshuo Huang, Rui Qian, Moritz Schwarzer-Becker, David Riazati, Mingfei Gao, Bailin Wang, Jack Cackler, Yang Lu, Ransen Niu, John Dennison, Guillaume Klein, Jeffrey Bigham, Deepak Gopinath, Navid Shiee, Darren Botten, Guillaume Tartavel, Alex Guillen Garcia, Sam Xu, Victoria MönchJuan Haladjian, Zi-Yi Dou, Matthias Paulik, Adolfo Lopez Mendez, Zhen Li, Hong-You Chen, Chao Jia, Dhaval Doshi, Zhengdong Zhang, Raunak Manjani, Aaron Franklin, Zhile Ren, David Chen, Artsiom Peshko, Nandhitha Raghuram, Hans Hao, Jiulong Shan, Kavya Nerella, Ramsey Tantawi, Vivek Kumar, Saiwen Wang, Brycen Wershing, Bhuwan Dhingra, Dhruti Shah, Ob Adaranijo, Xin Zheng, Tait Madsen, Hadas Kotek, Chang Liu, Yin Xia, Hanli Li, Suma Jayaram, Yanchao Sun, Ahmed Fakhry, Vasileios Saveris, Dustin Withers, Yanghao Li, Alp Aygar, Andres Romero Mier Y Teran, Kaiwei Huang, Mark Lee, Xiujun Li, Yuhong Li, Tyler Johnson, Jay Tang, Joseph Yitan Cheng, Futang Peng, Andrew Walkingshaw, Lucas Guibert, Abhishek Sharma, Cheng Shen, Piotr Maj, Yasutaka Tanaka, You-Cyuan Jhang, Vivian Ma, Tommi Vehvilainen, Kelvin Zou, Jeff Nichols, Matthew Lei, David Qiu, Yihao Qian, Gokul Santhanam, Wentao Wu, Yena Han, Dominik Moritz, Haijing Fu, Mingze Xu, Vivek Rathod, Jian Liu, Louis D'hauwe, Qin Ba, Haitian Sun, Haoran Yan, Philipp Dufter, Anh Nguyen, Yihao Feng, Emma Wang, Keyu He, Rahul Nair, Sanskruti Shah, Jiarui Lu, Patrick Sonnenberg, Jeremy Warner, Yuanzhi Li, Bowen Pan, Ziyi Zhong, Joe Zhou, Sam Davarnia, Olli Saarikivi, Irina Belousova, Rachel Burger, Shang-Chen Wu, Di Feng, Bas Straathof, James Chou, Yuanyang Zhang, Marco Zuliani, Eduardo Jimenez, Abhishek Sundararajan, Xianzhi Du, Chang Lan, Nilesh Shahdadpuri, Peter Grasch, Sergiu Sima, Josh Newnham, Varsha Paidi, Jianyu Wang, Kaelen Haag, Alex Braunstein, Daniele Molinari, Richard Wei, Brenda Yang, Nicholas Lusskin, Joanna Arreaza-Taylor, Meng Cao, Nicholas Seidl, Simon Wang, Jiaming Hu, Yiping Ma, Mengyu Li, Kieran Liu, Hang Su, Sachin Ravi, Chong Wang, Xin Wang, Kevin Smith, Haoxuan You, Binazir Karimzadeh, Rui Li, Jinhao Lei, Wei Fang, Alec Doane, Sam Wiseman, Ismael Fernandez, Jane Li, Andrew Hansen, Javier Movellan, Christopher Neubauer, Hanzhi Zhou, Chris Chaney, Nazir Kamaldin, Valentin Wolf, Fernando Bermúdez-Medina, Joris Pelemans, Peter Fu, Howard Xing, Xiang Kong, Wayne Shan, Gabriel Jacoby-Cooper, Dongcai Shen, Tom Gunter, Guillaume Seguin, Fangping Shi, Shiyu Li, Yang Xu, Areeba Kamal, Dan Masi, Saptarshi Guha, Qi Zhu, Jenna Thibodeau, Changyuan Zhang, Rebecca Callahan, Charles Maalouf, Wilson Tsao, Boyue Li, Qingqing Cao, Naomy Sabo, Cheng Leong, Yi Wang, Anupama Mann Anupama, Colorado Reed, Kenneth Jung, Zhifeng Chen, Mohana Prasad Sathya Moorthy, Yifei He, Erik Hornberger, Devi Krishna, Senyu Tong, Michael, Lee, David Haldimann, Yang Zhao, Bowen Zhang, Chang Gao, Chris Bartels, Sushma Rao, Nathalie Tran, Simon Lehnerer, Co Giang, Patrick Dong, Junting Pan, Biyao Wang, Dongxu Li, Mehrdad Farajtabar, Dongseong Hwang, Grace Duanmu, Eshan Verma, Sujeeth Reddy, Qi Shan, Hongbin Gao, Nan Du, Pragnya Sridhar, Forrest Huang, Yingbo Wang, Nikhil Bhendawade, Diane Zhu, Sai Aitharaju, Fred Hohman, Lauren Gardiner, Chung-Cheng Chiu, Yinfei Yang, Alper Kokmen, Frank Chu, Ke Ye, Kaan Elgin, Oron Levy, John Park, Donald Zhang, Eldon Schoop, Nina Wenzel, Michael Booker, Hyunjik Kim, Chinguun Erdenebileg, Nan Dun, Eric Liang Yang, Priyal Chhatrapati, Vishaal Mahtani, Haiming Gang, Kohen Chia, Deepa Seshadri, Donghan Yu, Yan Meng, Kelsey Peterson, Zhen Yang, Yongqiang Wang, Carina Peng, Doug Kang, Anuva Agarwal, Albert Antony, Juan Lao Tebar, Albin Madappally Jose, Regan Poston, Andy De Wang, Gerard Casamayor, Elmira Amirloo, Violet Yao, Wojciech Kryscinski, Kun Duan, Lezhi L
分类: cs.LG, cs.AI
发布日期: 2025-07-17 (更新: 2025-08-27)
💡 一句话要点
苹果发布Apple Intelligence基础语言模型:包括端侧3B模型和服务器端PT-MoE模型,赋能苹果设备与服务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 多模态学习 端侧部署 混合专家模型 模型量化 并行计算 Transformer Apple Intelligence
📋 核心要点
- 现有端侧设备和云端服务对高质量、低延迟的多语言多模态大模型需求日益增长,但部署和训练面临挑战。
- 论文提出端侧和云端两种模型:端侧模型优化设备性能,云端模型利用并行轨道混合专家Transformer提升质量和效率。
- 实验结果表明,所提出的端侧和云端模型在性能上与同等规模的开源模型相比,具有竞争力甚至更优。
📝 摘要(中文)
本文介绍了两种多语言、多模态基础语言模型,它们为苹果设备和服务的Apple Intelligence功能提供支持:一是30亿参数的端侧模型,通过KV缓存共享和2-bit量化感知训练等架构创新,针对Apple芯片进行了优化;二是可扩展的服务器模型,该模型构建于一种新颖的并行轨道混合专家(PT-MoE)Transformer之上,它结合了轨道并行、混合专家稀疏计算和交错的全局-局部注意力机制,从而在苹果的私有云计算平台上以具有竞争力的成本提供高质量的服务。这两个模型都在大规模多语言和多模态数据集上进行训练,这些数据集通过负责任的网络爬取、许可语料库和高质量合成数据获得,然后通过监督微调和强化学习在一个新的异步平台上进一步优化。最终的模型支持多种语言,同时理解图像并执行工具调用。在公共基准测试和人工评估中,服务器模型和端侧模型均达到或超过了同等规模的开源基线。
🔬 方法详解
问题定义:现有方法在端侧部署大型语言模型面临计算资源有限、延迟高等挑战,而云端服务则需要在保证高质量的同时,降低计算成本。此外,多语言和多模态的支持也是一个重要的需求。
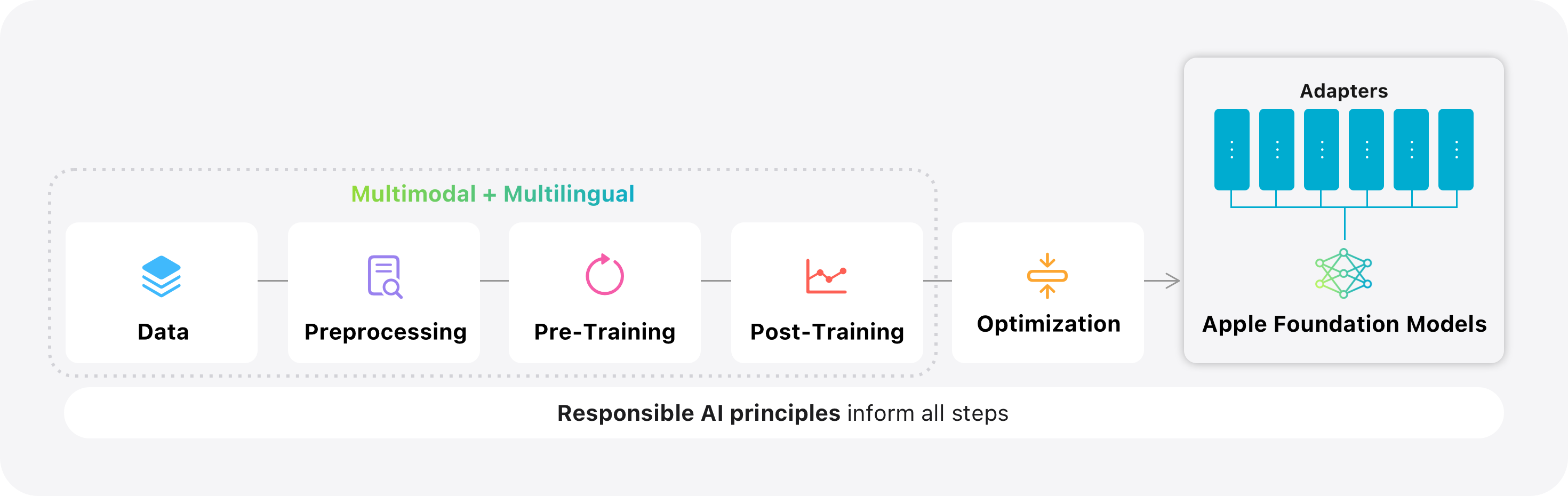
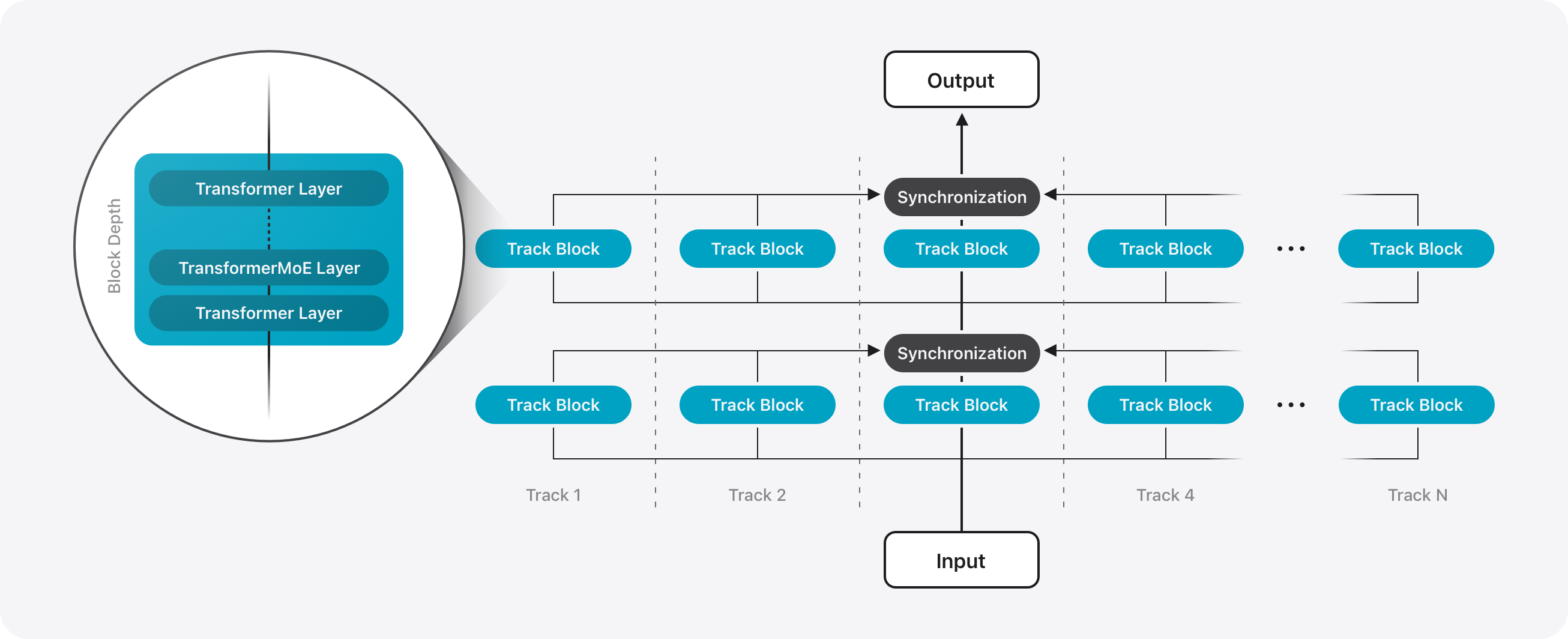
核心思路:论文针对端侧设备和云端服务分别设计了不同的模型架构。端侧模型通过架构创新(如KV缓存共享和2-bit量化感知训练)来优化性能,使其能够在资源受限的设备上高效运行。云端模型则采用并行轨道混合专家(PT-MoE)Transformer,利用稀疏计算和全局-局部注意力机制来提高模型质量和效率。
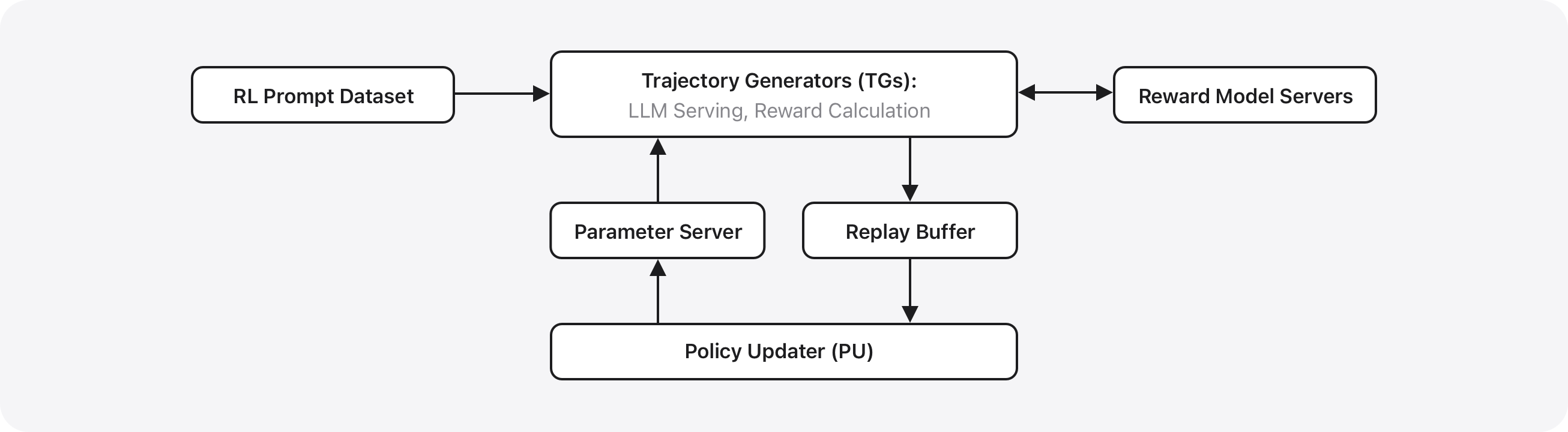
技术框架:端侧模型是一个30亿参数的模型,针对Apple芯片进行了优化。服务器端模型则基于PT-MoE Transformer,包含轨道并行、混合专家稀疏计算和交错的全局-局部注意力机制等模块。训练流程包括大规模多语言和多模态数据集上的预训练,以及监督微调和强化学习。
关键创新:PT-MoE Transformer是服务器端模型的关键创新。它结合了轨道并行、混合专家稀疏计算和交错的全局-局部注意力机制,能够在保证模型质量的同时,降低计算成本。端侧模型的KV缓存共享和2-bit量化感知训练也是重要的创新,能够有效降低模型大小和计算复杂度。
关键设计:端侧模型采用了KV缓存共享和2-bit量化感知训练等技术细节来优化性能。服务器端模型的PT-MoE Transformer则需要仔细设计专家数量、路由策略、注意力机制等参数。此外,训练数据的质量和规模,以及监督微调和强化学习的策略,也会对最终模型的性能产生重要影响。
🖼️ 关键图片
📊 实验亮点
论文提出的端侧模型和服务器端模型在公共基准测试和人工评估中均表现出色,达到或超过了同等规模的开源基线。这表明该研究提出的模型架构和优化技术是有效的,能够为苹果设备和服务的Apple Intelligence功能提供强大的支持。
🎯 应用场景
该研究成果可广泛应用于苹果设备和服务的Apple Intelligence功能,例如智能助手、图像理解、多语言翻译等。此外,该研究提出的模型架构和优化技术,也可为其他端侧设备和云端服务的AI应用提供借鉴,推动AI技术在更广泛领域的应用。
📄 摘要(原文)
We introduce two multilingual, multimodal foundation language models that power Apple Intelligence features across Apple devices and services: i a 3B-parameter on-device model optimized for Apple silicon through architectural innovations such as KV-cache sharing and 2-bit quantization-aware training; and ii a scalable server model built on a novel Parallel-Track Mixture-of-Experts PT-MoE transformer that combines track parallelism, mixture-of-experts sparse computation, and interleaved global-local attention to deliver high quality with competitive cost on Apple's Private Cloud Compute platform. Both models are trained on large-scale multilingual and multimodal datasets sourced via responsible web crawling, licensed corpora, and high-quality synthetic data, then further refined with supervised fine-tuning and reinforcement learning on a new asynchronous platform. The resulting models support several additional languages while understanding images and executing tool calls. In public benchmarks and human evaluations, both the server model and the on-device model match or surpass comparably sized open baselines. A new Swift-centric Foundation Models framework exposes guided generation, constrained tool calling, and LoRA adapter fine-tuning, allowing developers to integrate these capabilities with a few lines of code. The latest advancements in Apple Intelligence models are grounded in our Responsible AI approach with safeguards like content filtering and locale-specific evaluation, as well as our commitment to protecting our users' privacy with innovations like Private Cloud Compute.