Provable Low-Frequency Bias of In-Context Learning of Representations
作者: Yongyi Yang, Hidenori Tanaka, Wei Hu
分类: cs.LG
发布日期: 2025-07-17 (更新: 2025-07-30)
💡 一句话要点
提出双重收敛框架,揭示ICL表征学习的低频偏置特性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 表征学习 低频偏置 双重收敛 大语言模型
📋 核心要点
- 现有研究缺乏对LLM上下文学习(ICL)如何超越预训练知识,从提示中学习新行为的严谨解释。
- 论文提出双重收敛框架,证明隐藏表征在上下文和层之间收敛,导致对低频表征的隐式偏置。
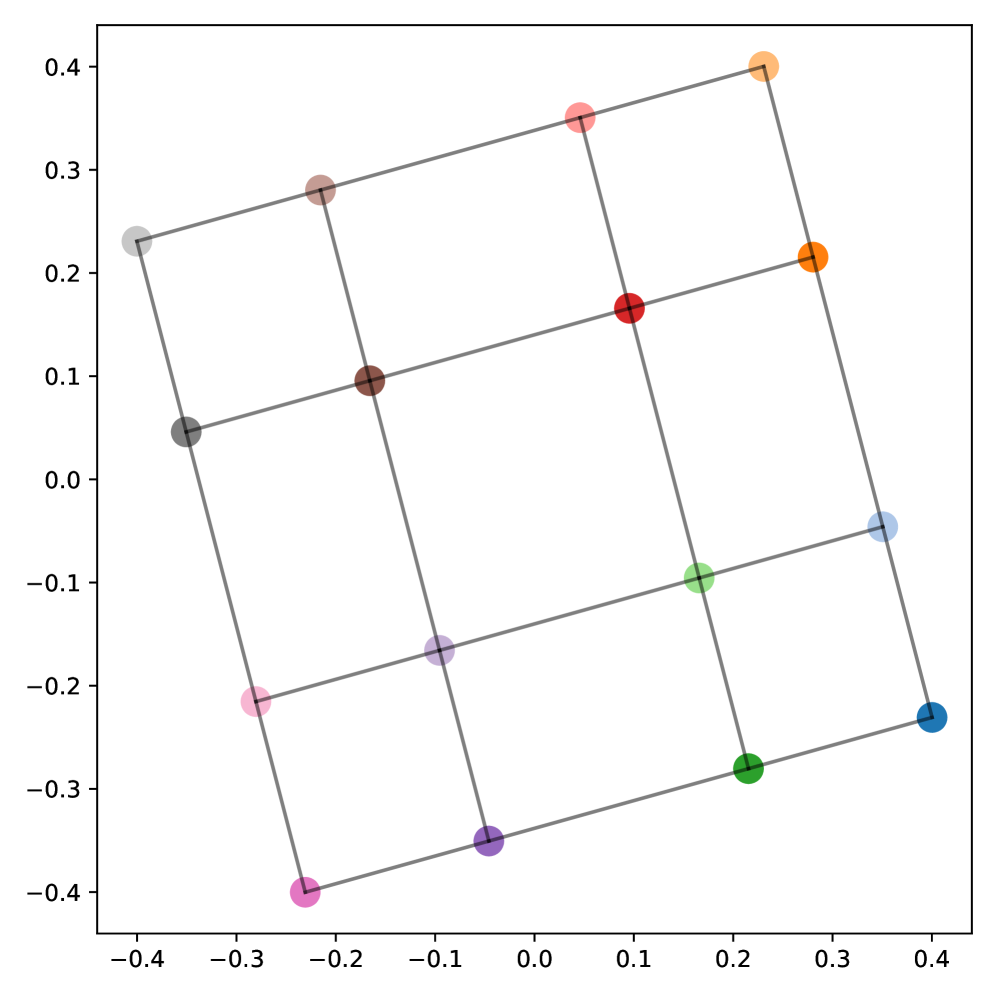
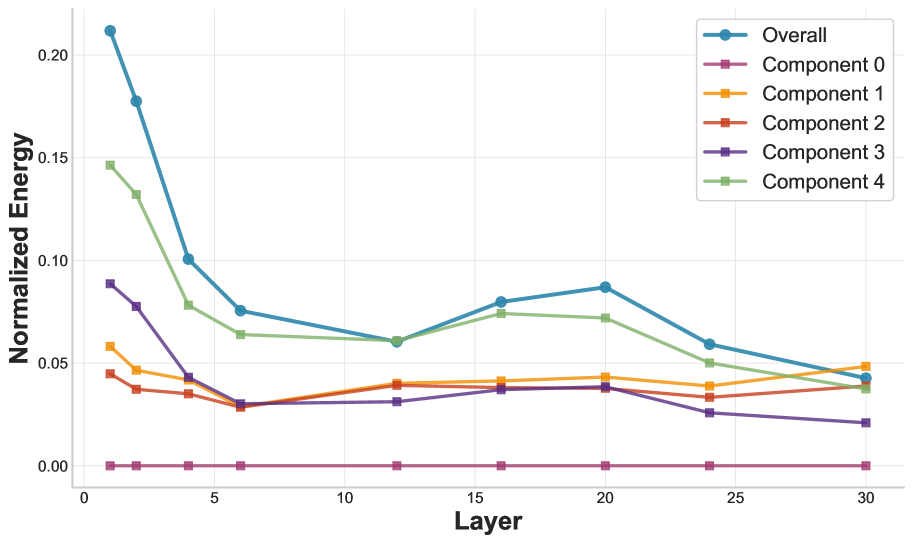
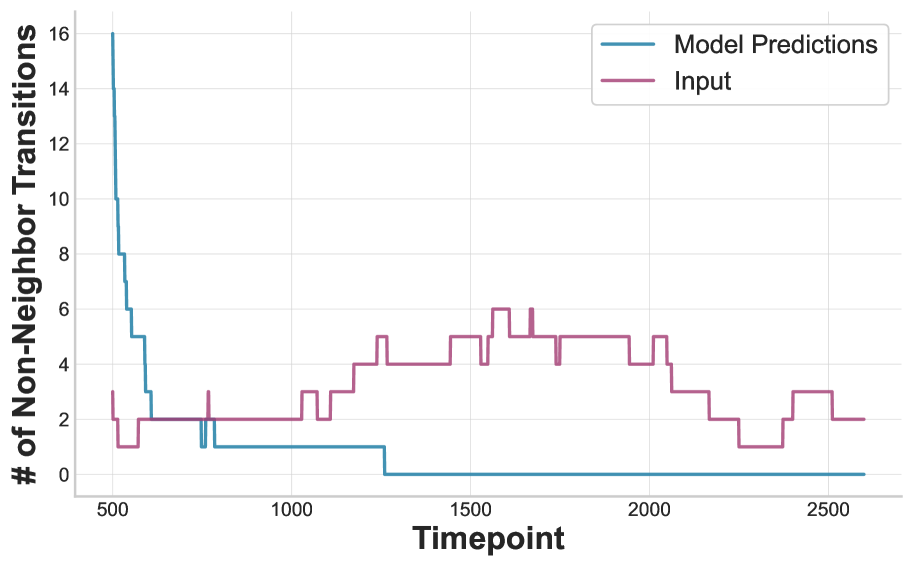
- 理论分析和实验验证表明,ICL具有对高频噪声的鲁棒性,并解释了表征的全局结构化和局部扭曲现象。
📝 摘要(中文)
本文针对大语言模型(LLMs)的上下文学习(ICL)能力,提出了首个严谨的解释。ICL允许LLMs仅通过输入序列获得新行为,无需参数更新。研究表明,ICL能够通过将提示的数据生成过程(DGP)的结构内化到隐藏表征中,从而超越预训练阶段学习到的原始含义。本文提出了一个统一的双重收敛框架,其中隐藏表征在上下文和层之间都收敛。这种双重收敛过程导致了对平滑(低频)表征的隐式偏置,我们对此进行了分析证明和实验验证。我们的理论解释了几个开放的经验观察,包括为什么学习到的表征表现出全局结构化但局部扭曲的几何形状,以及为什么它们的总能量衰减而不会消失。此外,我们的理论预测ICL对高频噪声具有内在的鲁棒性,我们通过实验证实了这一点。这些结果为ICL的潜在机制提供了新的见解,并为研究它提供了一个理论基础,有望扩展到更一般的数据分布和设置。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)的上下文学习(ICL)机制问题,特别是ICL如何通过学习提示中的数据生成过程(DGP)来超越预训练知识。现有方法缺乏对这一过程的严谨理论解释,无法解释ICL学习到的表征的特性,例如全局结构化但局部扭曲的几何形状,以及能量衰减等现象。
核心思路:论文的核心思路是提出一个“双重收敛”框架,即隐藏表征不仅在上下文之间收敛,也在网络层之间收敛。这种双重收敛过程导致模型隐式地偏向于学习低频(平滑)的表征。作者认为,这种低频偏置是ICL能够有效学习和泛化的关键。
技术框架:论文构建了一个理论框架,通过数学推导证明了双重收敛会导致低频偏置。具体来说,作者首先形式化了ICL的学习过程,然后分析了隐藏表征在上下文和层之间的收敛行为。通过分析收敛过程的性质,作者证明了模型倾向于学习低频的表征。此外,作者还通过实验验证了理论分析的正确性。
关键创新:论文最重要的技术创新在于提出了双重收敛框架,并证明了它与ICL的低频偏置之间的关系。这是首次对ICL的表征学习机制进行严谨的理论解释,为理解ICL的能力提供了新的视角。与现有方法相比,该理论框架能够解释更多ICL的经验现象,并预测ICL的鲁棒性。
关键设计:论文的关键设计包括:1) 对ICL学习过程的数学形式化,使其能够进行理论分析;2) 对隐藏表征在上下文和层之间的收敛行为的细致分析;3) 通过实验验证理论分析的正确性,包括验证低频偏置的存在,以及ICL对高频噪声的鲁棒性。
🖼️ 关键图片
📊 实验亮点
论文通过理论分析和实验验证,证明了ICL存在低频偏置。实验结果表明,ICL学习到的表征具有全局结构化但局部扭曲的几何形状,并且总能量衰减。此外,实验还证实了ICL对高频噪声具有内在的鲁棒性,验证了理论预测。
🎯 应用场景
该研究成果可应用于提升大语言模型的上下文学习能力和泛化性能,例如,通过控制或增强低频偏置,可以提高模型在噪声环境下的鲁棒性。此外,该理论框架为设计更有效的ICL方法提供了指导,有助于开发更强大的AI系统。
📄 摘要(原文)
In-context learning (ICL) enables large language models (LLMs) to acquire new behaviors from the input sequence alone without any parameter updates. Recent studies have shown that ICL can surpass the original meaning learned in pretraining stage through internalizing the structure the data-generating process (DGP) of the prompt into the hidden representations. However, the mechanisms by which LLMs achieve this ability is left open. In this paper, we present the first rigorous explanation of such phenomena by introducing a unified framework of double convergence, where hidden representations converge both over context and across layers. This double convergence process leads to an implicit bias towards smooth (low-frequency) representations, which we prove analytically and verify empirically. Our theory explains several open empirical observations, including why learned representations exhibit globally structured but locally distorted geometry, and why their total energy decays without vanishing. Moreover, our theory predicts that ICL has an intrinsic robustness towards high-frequency noise, which we empirically confirm. These results provide new insights into the underlying mechanisms of ICL, and a theoretical foundation to study it that hopefully extends to more general data distributions and settings.