AirLLM: Diffusion Policy-based Adaptive LoRA for Remote Fine-Tuning of LLM over the Air
作者: Shiyi Yang, Xiaoxue Yu, Rongpeng Li, Jianhang Zhu, Zhifeng Zhao, Honggang Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-15
备注: 11 pages, 8 figures
💡 一句话要点
AirLLM:基于扩散策略的自适应LoRA,用于无线环境下的LLM远程微调
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 远程微调 低秩适应 强化学习 扩散模型 无线通信 边缘计算
📋 核心要点
- 现有LoRA方法在无线远程微调LLM时,秩配置固定或启发式,导致传输效率低。
- AirLLM采用分层扩散策略,利用PPO生成粗粒度决策,DDIM细化为高分辨率秩向量。
- 实验表明,AirLLM在不同信噪比下,提升微调性能,显著降低传输成本。
📝 摘要(中文)
在边缘设备上运行大型语言模型(LLM)面临着通信带宽受限以及计算和内存成本紧张的挑战。因此,云辅助远程微调变得不可或缺。然而,现有的低秩适应(LoRA)方法通常采用固定或启发式的秩配置,并且所有LoRA参数的无线传输效率可能较低。为了解决这个限制,我们开发了AirLLM,一个用于通信感知LoRA适配的分层扩散策略框架。具体来说,AirLLM将秩配置建模为一个跨越所有LoRA插入投影的结构化动作向量。为了解决潜在的高维序列决策问题,Proximal Policy Optimization(PPO)智能体通过联合观察无线状态和语言复杂度来生成粗粒度的决策,然后通过Denoising Diffusion Implicit Models(DDIM)对其进行细化,以产生高分辨率、任务和信道自适应的秩向量。这两个模块交替优化,DDIM在Classifier-Free Guidance(CFG)范式下训练,以保持与PPO奖励的一致性。在不同信噪比下的实验表明,AirLLM始终增强微调性能,同时显著降低传输成本,突出了强化学习驱动、扩散细化的秩自适应在可扩展和高效的无线远程微调中的有效性。
🔬 方法详解
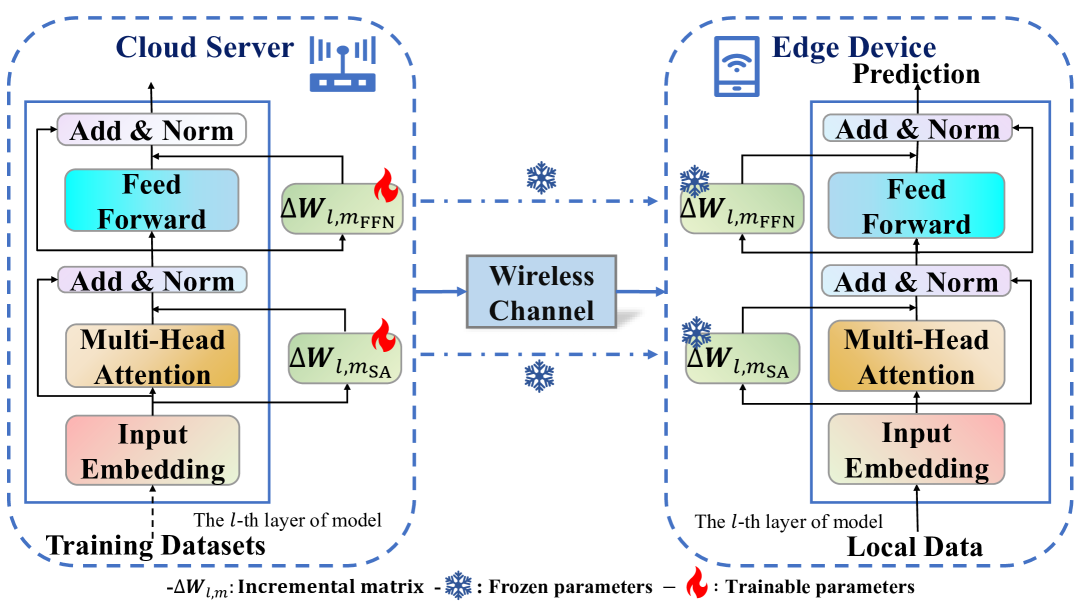
问题定义:论文旨在解决在无线通信环境下,对大型语言模型进行远程微调时,由于带宽限制和计算资源约束,传统LoRA方法传输效率低下的问题。现有方法通常采用固定的或启发式的秩配置,无法根据信道状态和任务复杂度动态调整,导致不必要的参数传输开销。
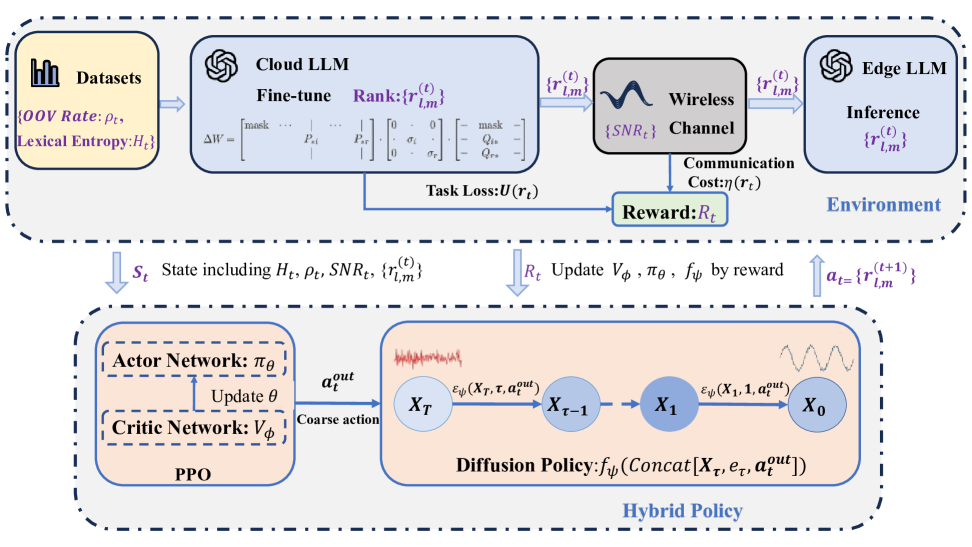
核心思路:AirLLM的核心思路是利用强化学习和扩散模型,实现通信感知的自适应LoRA秩配置。通过PPO智能体学习无线环境和语言复杂度的特征,生成粗粒度的秩配置决策,然后利用DDIM扩散模型将该决策细化为高分辨率的、任务和信道自适应的秩向量。这样可以动态调整LoRA的秩,在保证微调性能的同时,最小化传输开销。
技术框架:AirLLM包含两个主要模块:PPO智能体和DDIM扩散模型。PPO智能体负责生成粗粒度的秩配置决策,其输入包括无线信道状态(如信噪比)和语言复杂度(如困惑度)。DDIM扩散模型则将PPO的输出作为条件,生成高分辨率的秩向量。这两个模块交替训练,PPO智能体根据微调性能和传输成本的奖励进行优化,DDIM扩散模型则在Classifier-Free Guidance(CFG)范式下训练,以保持与PPO奖励的一致性。
关键创新:AirLLM的关键创新在于将强化学习和扩散模型相结合,用于自适应LoRA秩配置。与传统方法相比,AirLLM能够根据无线环境和任务复杂度动态调整LoRA的秩,从而在保证微调性能的同时,显著降低传输开销。此外,使用分层结构,先用PPO做粗略决策,再用DDIM细化,降低了高维动作空间的搜索难度。
关键设计:PPO智能体使用Actor-Critic结构,Actor网络输出秩配置的概率分布,Critic网络评估当前状态的价值。DDIM扩散模型使用U-Net结构,以PPO的输出作为条件,生成秩向量。损失函数包括PPO的策略梯度损失和DDIM的扩散损失。Classifier-Free Guidance(CFG)用于指导DDIM的训练,使其生成的秩向量与PPO的奖励保持一致。
🖼️ 关键图片
📊 实验亮点
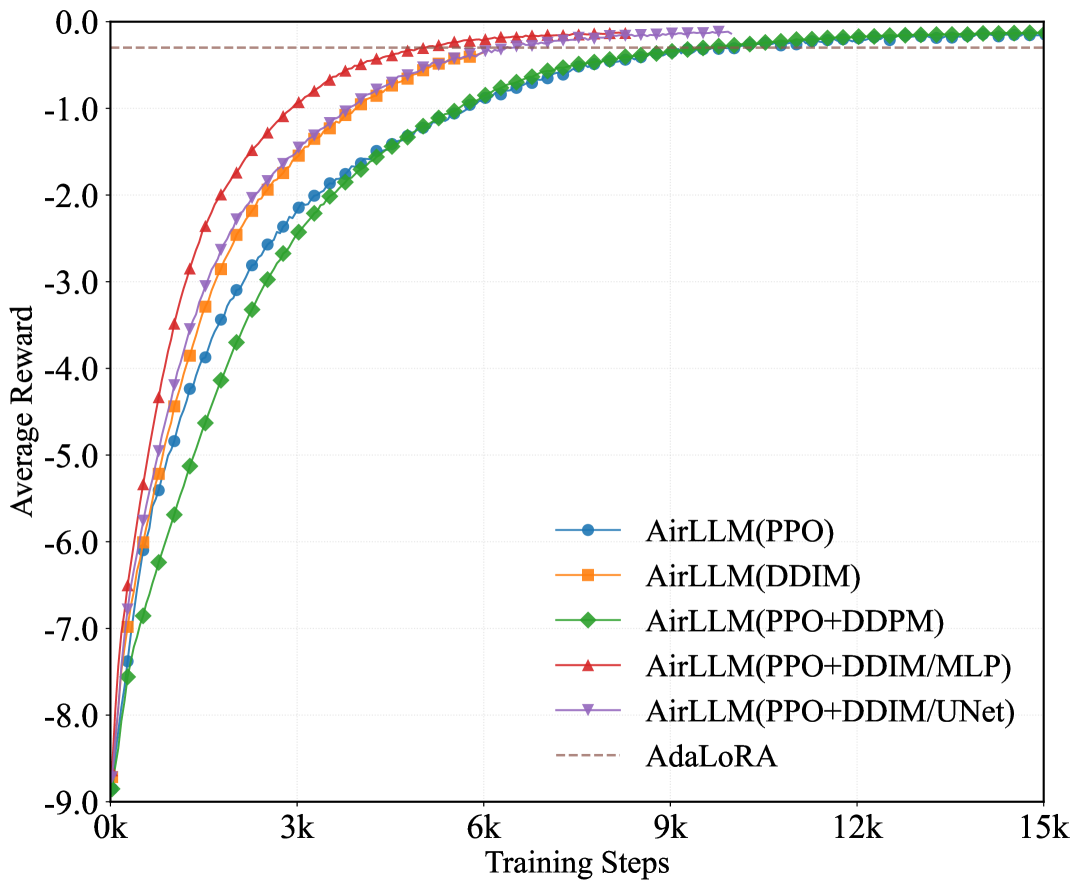
实验结果表明,AirLLM在不同信噪比下,能够显著降低LoRA参数的传输成本,同时保持或提高微调性能。例如,在低信噪比环境下,AirLLM能够将传输成本降低50%以上,而微调性能仅略有下降。在高信噪比环境下,AirLLM甚至能够提高微调性能,同时降低传输成本。
🎯 应用场景
AirLLM适用于各种需要在带宽受限的无线环境下对大型语言模型进行远程微调的场景,例如移动设备上的智能助手、物联网设备上的自然语言处理应用、以及在资源受限的环境中部署LLM等。该研究有助于降低LLM在边缘设备上的部署成本,并提高其在实际应用中的可用性。
📄 摘要(原文)
Operating Large Language Models (LLMs) on edge devices is increasingly challenged by limited communication bandwidth and strained computational and memory costs. Thus, cloud-assisted remote fine-tuning becomes indispensable. Nevertheless, existing Low-Rank Adaptation (LoRA) approaches typically employ fixed or heuristic rank configurations, and the subsequent over-the-air transmission of all LoRA parameters could be rather inefficient. To address this limitation, we develop AirLLM, a hierarchical diffusion policy framework for communication-aware LoRA adaptation. Specifically, AirLLM models the rank configuration as a structured action vector that spans all LoRA-inserted projections. To solve the underlying high-dimensional sequential decision-making problem, a Proximal Policy Optimization (PPO) agent generates coarse-grained decisions by jointly observing wireless states and linguistic complexity, which are then refined via Denoising Diffusion Implicit Models (DDIM) to produce high-resolution, task- and channel-adaptive rank vectors. The two modules are optimized alternatively, with the DDIM trained under the Classifier-Free Guidance (CFG) paradigm to maintain alignment with PPO rewards. Experiments under varying signal-to-noise ratios demonstrate that AirLLM consistently enhances fine-tuning performance while significantly reducing transmission costs, highlighting the effectiveness of reinforcement-driven, diffusion-refined rank adaptation for scalable and efficient remote fine-tuning over the air.