Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination
作者: Mingqi Wu, Zhihao Zhang, Qiaole Dong, Zhiheng Xi, Jun Zhao, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Huijie Lv, Ming Zhang, Yanwei Fu, Qin Liu, Songyang Zhang, Qi Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-14 (更新: 2025-12-17)
备注: 28 pages, AAAI 2026
💡 一句话要点
揭示数据污染对RL微调大模型数学推理能力评估的影响,提出清洁数据集RandomCalculation。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 数据污染 数学推理 基准测试 奖励信号 模型评估
📋 核心要点
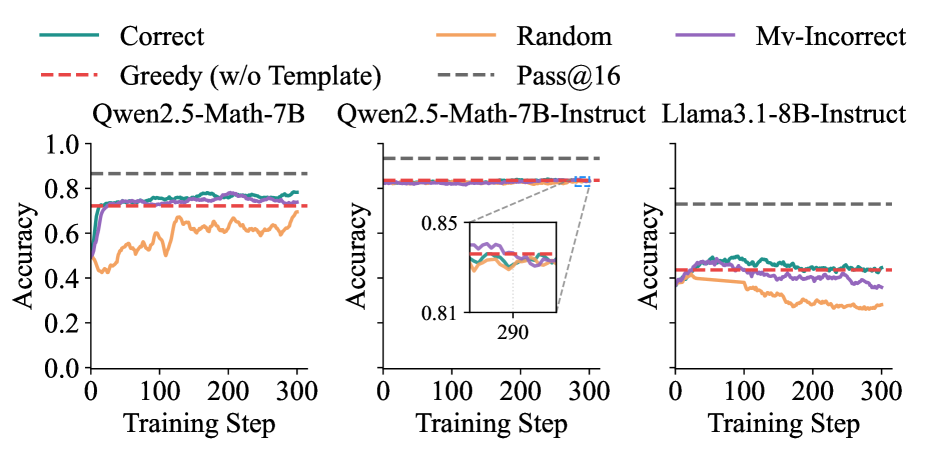
- 现有研究表明,强化学习能提升大语言模型的推理能力,但结果主要集中在Qwen2.5模型上,且可能受到数据污染的影响。
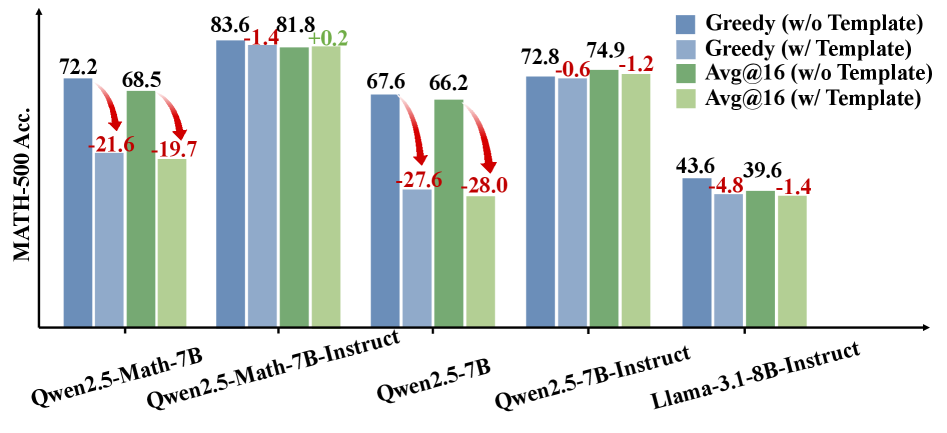
- 该研究的核心在于发现并验证了现有数学推理基准测试对Qwen2.5模型存在数据污染,导致评估结果不可靠。
- 论文提出了RandomCalculation数据集,用于评估模型在无数据泄露情况下的数学推理能力,并验证了准确奖励信号的重要性。
📝 摘要(中文)
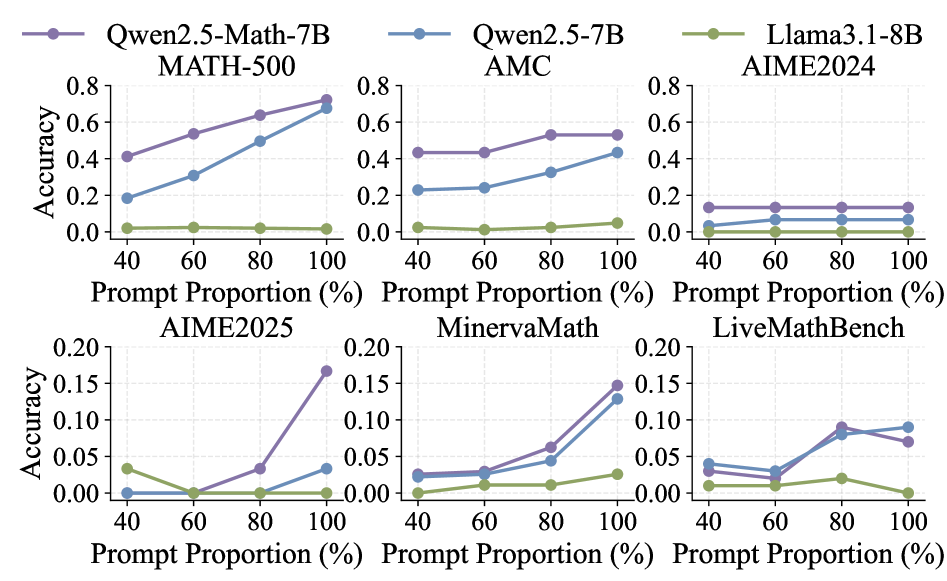
大型语言模型中的推理能力一直是研究的重点。最近,采用强化学习(RL)的研究引入了多种方法,以极少甚至没有外部监督的情况下,实现了显著的性能提升。令人惊讶的是,一些研究甚至表明,随机或不正确的奖励信号可以提高性能。然而,这些突破主要体现在数学能力强的Qwen2.5系列模型在MATH-500、AMC和AIME等基准测试中,而很少迁移到Llama等模型上,这需要更深入的研究。我们的实证分析表明,在海量网络规模语料库上的预训练使Qwen2.5容易受到广泛使用的基准测试中的数据污染。因此,从受污染的基准测试中得出的关于Qwen2.5系列的结论可能不可靠。为了获得可信的评估结果,我们引入了一个生成器,可以创建任意长度和难度的完全干净的算术问题,称为RandomCalculation。使用这个无泄漏的数据集,我们表明只有准确的奖励信号才能产生稳定的改进,从而超过基础模型在数学推理中的性能边界,而随机或不正确的奖励则不能。此外,我们进行了更细粒度的分析,以阐明在MATH-500和RandomCalculation基准测试中观察到的不同性能的根本原因。因此,我们建议未来的研究在未受污染的基准测试中评估模型,并在可行的情况下测试各种模型系列,以确保关于RL和相关方法的可信结论。
🔬 方法详解
问题定义:现有研究使用强化学习微调大型语言模型,并在数学推理任务上取得了显著进展。然而,这些进展主要集中在特定模型(如Qwen2.5)上,并且在广泛使用的基准测试(如MATH-500)中观察到。论文指出,这些基准测试可能存在数据污染,导致对模型真实推理能力的评估产生偏差。现有方法的痛点在于无法区分模型是通过真正的推理能力还是通过记忆来解决问题。
核心思路:论文的核心思路是构建一个完全干净、无数据泄露的数学推理数据集,即RandomCalculation。通过在这个数据集上评估模型,可以更准确地衡量模型通过强化学习获得的推理能力,并消除数据污染带来的干扰。同时,通过对比不同奖励信号(准确、随机、错误)对模型性能的影响,验证了准确奖励信号在强化学习中的重要性。
技术框架:该研究的技术框架主要包括以下几个部分:1) 分析现有基准测试(如MATH-500)可能存在的数据污染问题;2) 设计并实现RandomCalculation数据集生成器,确保生成的数据集完全干净;3) 使用RandomCalculation数据集,通过强化学习微调Qwen2.5等模型;4) 对比不同奖励信号对模型性能的影响;5) 对比模型在MATH-500和RandomCalculation数据集上的表现,分析数据污染的影响。
关键创新:该研究最重要的技术创新点在于提出了RandomCalculation数据集,这是一个完全干净、无数据泄露的数学推理数据集。与现有基准测试相比,RandomCalculation数据集可以更准确地评估模型的推理能力,避免数据污染带来的偏差。此外,该研究还通过实验验证了准确奖励信号在强化学习中的重要性,纠正了之前一些研究中关于随机或错误奖励信号也能提升模型性能的错误结论。
关键设计:RandomCalculation数据集生成器的关键设计在于确保生成的问题具有随机性、多样性和可控性。具体来说,生成器可以控制问题的长度、难度和运算类型,从而生成各种各样的算术问题。此外,生成器还采用了特定的算法,确保生成的问题在互联网上不存在,从而避免数据泄露。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在RandomCalculation数据集上,只有准确的奖励信号才能使模型性能稳定提升,超过基础模型。而随机或错误的奖励信号无法带来性能提升。对比模型在MATH-500和RandomCalculation数据集上的表现,验证了MATH-500数据集存在数据污染,导致评估结果虚高。
🎯 应用场景
该研究成果可应用于更可靠地评估和提升大型语言模型的数学推理能力。RandomCalculation数据集可作为新的基准,用于评估各种模型的推理能力,并推动强化学习在语言模型微调中的应用。此外,该研究也提醒研究人员在评估模型时,需要关注数据污染问题,并采取相应的措施。
📄 摘要(原文)
Reasoning in large language models has long been a central research focus, and recent studies employing reinforcement learning (RL) have introduced diverse methods that yield substantial performance gains with minimal or even no external supervision. Surprisingly, some studies even suggest that random or incorrect reward signals can enhance performance. However, these breakthroughs are predominantly observed for the mathematically strong Qwen2.5 series on benchmarks such as MATH-500, AMC, and AIME, and seldom transfer to models like Llama, which warrants a more in-depth investigation. In this work, our empirical analysis reveals that pre-training on massive web-scale corpora leaves Qwen2.5 susceptible to data contamination in widely used benchmarks. Consequently, conclusions derived from contaminated benchmarks on Qwen2.5 series may be unreliable. To obtain trustworthy evaluation results, we introduce a generator that creates fully clean arithmetic problems of arbitrary length and difficulty, dubbed RandomCalculation. Using this leakage-free dataset, we show that only accurate reward signals yield steady improvements that surpass the base model's performance boundary in mathematical reasoning, whereas random or incorrect rewards do not. Moreover, we conduct more fine-grained analyses to elucidate the factors underlying the different performance observed on the MATH-500 and RandomCalculation benchmarks. Consequently, we recommend that future studies evaluate models on uncontaminated benchmarks and, when feasible, test various model series to ensure trustworthy conclusions about RL and related methods.