Pimba: A Processing-in-Memory Acceleration for Post-Transformer Large Language Model Serving
作者: Wonung Kim, Yubin Lee, Yoonsung Kim, Jinwoo Hwang, Seongryong Oh, Jiyong Jung, Aziz Huseynov, Woong Gyu Park, Chang Hyun Park, Divya Mahajan, Jongse Park
分类: cs.AR, cs.LG
发布日期: 2025-07-14 (更新: 2025-09-16)
期刊: MICRO 2025
💡 一句话要点
Pimba:面向后Transformer大语言模型服务的存内计算加速方案
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 存内计算 后Transformer模型 硬件加速 模型Serving
📋 核心要点
- 现有Transformer模型计算和内存成本高昂,难以支持长上下文推理,后Transformer模型虽然在算法上有所改进,但缺乏统一高效的serving系统。
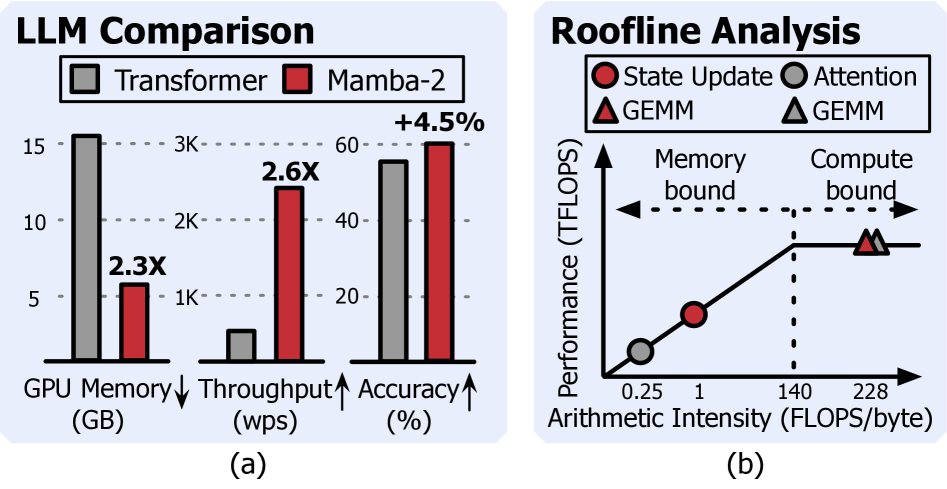
- Pimba通过分析Transformer和后Transformer模型的共性瓶颈——内存带宽限制,提出基于存内计算的状态更新处理单元阵列SPU,加速状态更新和注意力计算。
- 实验结果表明,Pimba相比于LLM优化的GPU和GPU+PIM系统,分别实现了高达4.1倍和2.1倍的token生成吞吐量提升。
📝 摘要(中文)
Transformer是当前大语言模型(LLM)的驱动力,但其计算和内存成本随序列长度增长,对长上下文推理的可扩展性构成挑战。算法社区正在探索替代架构,如状态空间模型(SSM)、线性注意力和循环神经网络(RNN),统称为后Transformer模型。这带来一个关键挑战:构建一个统一的 serving 系统,高效支持 Transformer 和后 Transformer LLM。本文分析了 Transformer 和后 Transformer LLM 的性能特征。尽管算法不同,但由于 Transformer 中的注意力和后 Transformer 中的状态更新,两者在批量推理下都受到内存带宽的限制。进一步分析表明:(1)状态更新操作比注意力产生更高的硬件成本,使得每个 bank 的 PIM 加速效率低下;(2)不同的低精度算术方法提供不同的精度-面积权衡,而 Microsoft 的 MX 是 Pareto 最优选择。基于这些见解,本文设计了 Pimba,作为一个状态更新处理单元(SPU)阵列,每个 SPU 在两个 bank 之间共享,以实现对 PIM 的交错访问。每个 SPU 包括一个状态更新处理引擎(SPE),包含使用基于 MX 的量化算术的 element-wise 乘法器和加法器,从而能够高效执行状态更新和注意力操作。评估表明,与 LLM 优化的 GPU 和 GPU+PIM 系统相比,Pimba 分别实现了高达 4.1 倍和 2.1 倍的 token 生成吞吐量。
🔬 方法详解
问题定义:现有的大语言模型 serving 系统难以同时高效地支持 Transformer 和后 Transformer 模型。Transformer 模型在长序列推理时面临计算和内存瓶颈,而后 Transformer 模型虽然在算法上有所改进,但缺乏专门的硬件加速支持,导致整体 serving 效率不高。现有方法要么针对特定模型进行优化,要么无法充分利用后 Transformer 模型的特性。
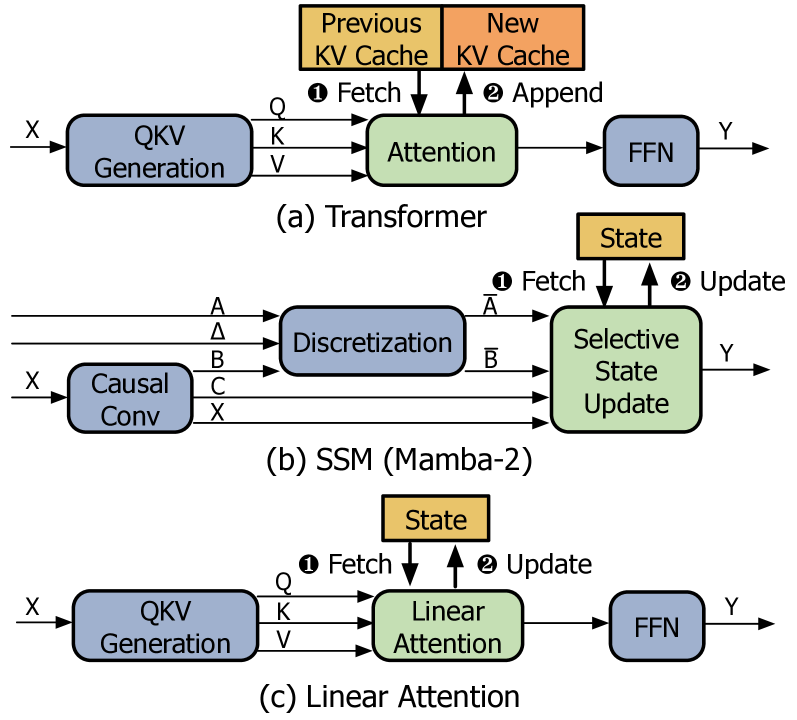
核心思路:论文的核心思路是利用存内计算 (PIM) 加速 Transformer 和后 Transformer 模型中的关键操作,即注意力和状态更新。通过分析发现,尽管两类模型在算法上有所不同,但它们都受到内存带宽的限制。因此,将计算单元放置在内存附近,可以有效减少数据传输,提高整体性能。此外,论文还发现状态更新操作的硬件成本较高,因此设计了共享的 PIM 架构。
技术框架:Pimba 的整体架构包含一个状态更新处理单元 (SPU) 阵列,每个 SPU 在两个内存 bank 之间共享,以实现交错访问。每个 SPU 包含一个状态更新处理引擎 (SPE),SPE 包含 element-wise 乘法器和加法器,使用基于 Microsoft MX 的量化算术。整个系统通过将计算任务卸载到 PIM 阵列来加速状态更新和注意力计算。
关键创新:Pimba 的关键创新在于其针对 Transformer 和后 Transformer 模型共性瓶颈的 PIM 加速架构。与传统的 GPU 或 GPU+PIM 系统相比,Pimba 能够更有效地利用内存带宽,降低数据传输延迟。此外,论文还提出了共享的 SPU 设计,降低了硬件成本,提高了资源利用率。
关键设计:Pimba 的关键设计包括:(1) 基于 Microsoft MX 的量化算术,在精度和面积之间取得 Pareto 最优的平衡;(2) 共享的 SPU 架构,降低硬件成本;(3) 交错的内存访问方式,提高数据吞吐量。具体参数设置和网络结构细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Pimba 相比于 LLM 优化的 GPU 系统,实现了高达 4.1 倍的 token 生成吞吐量提升。与 GPU+PIM 系统相比,Pimba 也实现了 2.1 倍的吞吐量提升。这些结果表明 Pimba 在加速大语言模型 serving 方面具有显著优势,能够有效提高推理效率。
🎯 应用场景
Pimba 的潜在应用领域包括云端大语言模型 serving、边缘设备上的低延迟推理以及需要处理长上下文的各种应用场景,例如智能客服、机器翻译、文本摘要等。通过提高 token 生成吞吐量,Pimba 可以降低 serving 成本,提升用户体验,并推动大语言模型在更多领域的应用。
📄 摘要(原文)
Transformers are the driving force behind today's Large Language Models (LLMs), serving as the foundation for their performance and versatility. Yet, their compute and memory costs grow with sequence length, posing scalability challenges for long-context inferencing. In response, the algorithm community is exploring alternative architectures, such as state space models (SSMs), linear attention, and recurrent neural networks (RNNs), which we refer to as post-transformers. This shift presents a key challenge: building a serving system that efficiently supports both transformer and post-transformer LLMs within a unified framework. To address this challenge, we analyze the performance characteristics of transformer and post-transformer LLMs. Despite their algorithmic differences, both are fundamentally limited by memory bandwidth under batched inference due to attention in transformers and state updates in post-transformers. Further analyses suggest two additional insights: (1) state update operations, unlike attention, incur high hardware cost, making per-bank PIM acceleration inefficient, and (2) different low-precision arithmetic methods offer varying accuracy-area tradeoffs, while we identify Microsoft's MX as the Pareto-optimal choice. Building on these insights, we design Pimba as an array of State-update Processing Units (SPUs), each shared between two banks to enable interleaved access to PIM. Each SPU includes a State-update Processing Engine (SPE) that comprises element-wise multipliers and adders using MX-based quantized arithmetic, enabling efficient execution of state update and attention operations. Our evaluation shows that, compared to LLM-optimized GPU and GPU+PIM systems, Pimba achieves up to 4.1x and 2.1x higher token generation throughput, respectively.