Compression Method for Deep Diagonal State Space Model Based on $H^2$ Optimal Reduction
作者: Hiroki Sakamoto, Kazuhiro Sato
分类: cs.LG, eess.SY
发布日期: 2025-07-14 (更新: 2025-07-30)
备注: Accepted to IEEE Control Systems Letters
💡 一句话要点
提出基于$H^2$最优降阶的深对角状态空间模型压缩方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度学习 状态空间模型 模型压缩 H^2降阶 资源受限设备 长程依赖性 参数减少
📋 核心要点
- 现有的深度学习模型在处理序列数据时,参数规模庞大,导致在资源受限设备上的部署困难。
- 本研究提出了一种将控制理论中的$H^2$模型降阶技术应用于线性SSM组件的参数减少方法。
- 实验结果表明,所提方法在LRA基准测试中优于平衡截断方法,成功将参数数量减少至$1/32$,且性能保持不变。
📝 摘要(中文)
深度学习模型结合线性状态空间模型(SSM)在捕捉序列数据中的长程依赖性方面受到关注。然而,其庞大的参数规模在资源受限的设备上部署时面临挑战。本研究提出了一种高效的参数减少方法,通过将控制理论中的$H^2$模型降阶技术应用于线性SSM组件。在实验中,基于我们提出的方法的模型压缩在LRA基准测试中表现优于现有的平衡截断方法,同时成功将SSM中的参数数量减少至原来的$1/32$,而不牺牲原始模型的性能。
🔬 方法详解
问题定义:本论文旨在解决深度学习模型中线性状态空间模型(SSM)参数过多的问题,导致在资源受限设备上难以有效部署。现有的模型压缩方法往往无法在减少参数的同时保持模型性能。
核心思路:论文提出通过控制理论中的$H^2$模型降阶技术来高效减少线性SSM的参数。该方法旨在在保持模型性能的同时,显著降低参数数量。
技术框架:整体架构包括对线性SSM组件的分析与降阶,首先识别模型的关键特征,然后应用$H^2$降阶技术进行参数压缩,最后通过实验验证压缩后的模型性能。
关键创新:最重要的技术创新在于将$H^2$降阶技术引入到深度学习模型的参数压缩中,区别于传统的平衡截断方法,能够在更大程度上减少参数数量而不损失性能。
关键设计:在参数设置上,采用了特定的损失函数来平衡压缩率与性能之间的关系,同时设计了适应性强的网络结构,以确保在降阶后模型的有效性。具体的参数设置和网络结构细节在实验部分进行了详细描述。
🖼️ 关键图片

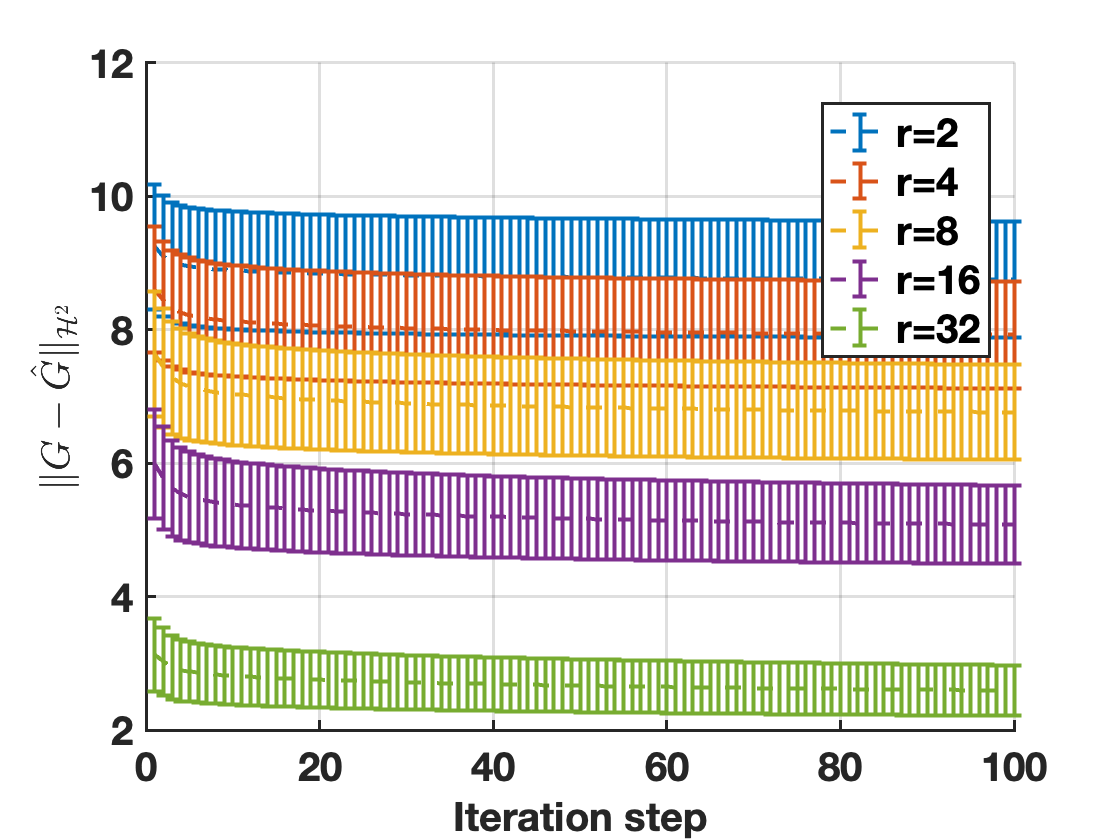

📊 实验亮点
实验结果显示,基于所提方法的模型压缩在LRA基准测试中表现优于平衡截断方法,成功将SSM中的参数数量减少至原来的$1/32$,且模型性能保持稳定。这一结果表明该方法在模型压缩领域的有效性和优势。
🎯 应用场景
该研究的潜在应用领域包括移动设备、嵌入式系统和物联网设备等资源受限环境中的深度学习模型部署。通过有效的参数压缩方法,可以在不牺牲性能的前提下,提升模型的运行效率和适用性,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Deep learning models incorporating linear SSMs have gained attention for capturing long-range dependencies in sequential data. However, their large parameter sizes pose challenges for deployment on resource-constrained devices. In this study, we propose an efficient parameter reduction method for these models by applying $H^{2}$ model order reduction techniques from control theory to their linear SSM components. In experiments, the LRA benchmark results show that the model compression based on our proposed method outperforms an existing method using the Balanced Truncation, while successfully reducing the number of parameters in the SSMs to $1/32$ without sacrificing the performance of the original models.