Memorization Sinks: Isolating Memorization during LLM Training
作者: Gaurav R. Ghosal, Pratyush Maini, Aditi Raghunathan
分类: cs.LG, cs.AI
发布日期: 2025-07-14 (更新: 2025-09-15)
备注: Accepted at the 2025 International Conference of Machine Learning
🔗 代码/项目: GITHUB
💡 一句话要点
提出MemSinks,通过隔离记忆神经元解决LLM训练中的隐私和版权问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 记忆隔离 隐私保护 版权保护 神经元选择
📋 核心要点
- 大型语言模型存在记忆重复序列的风险,导致隐私和版权问题,现有事后移除方法效果不佳。
- MemSinks通过引入序列标识符,为每个序列激活独特的记忆神经元集合,从而隔离记忆内容。
- 实验表明,MemSinks在数十亿参数和token规模下,实现了有效的记忆隔离和强大的泛化能力。
📝 摘要(中文)
大型语言模型容易记忆重复序列,引发隐私和版权担忧。一种常见的缓解策略是在事后从特定神经元中移除记忆的信息,但效果有限。在受控环境中,我们发现自然序列(类似于语言上合理的文本)的记忆在机制上与通用语言能力纠缠在一起,因此难以事后移除。本文提出了一种新的MemSinks范式,旨在通过设计来促进记忆的隔离。我们利用序列标识符来激活每个序列在重复过程中唯一的一组记忆神经元。通过分析学习和遗忘的动态,我们认为MemSinks有助于隔离记忆的内容,使其更容易移除,而不会损害通用语言能力。我们在数十亿参数和数十亿token的规模上实现了MemSinks,并观察到有效的隔离和强大的泛化能力。据我们所知,这是第一个在真实数据上证明同时实现泛化和隔离的概念验证。我们的代码已开源。
🔬 方法详解
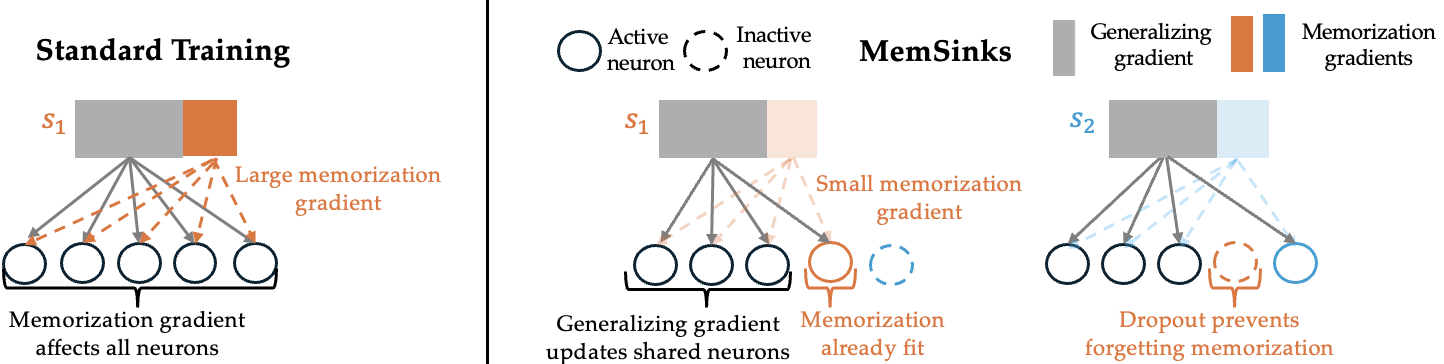
问题定义:大型语言模型(LLM)在训练过程中会记忆训练数据中的重复序列,这带来了严重的隐私和版权问题。现有的事后移除记忆信息的方法,例如直接修改或删除特定神经元,往往难以奏效,因为记忆的内容与模型的通用语言能力纠缠在一起,移除记忆的同时也会损害模型的性能。
核心思路:论文的核心思路是通过设计一种新的训练范式,即MemSinks,来主动地隔离记忆过程。MemSinks的目标是让模型在训练过程中将需要记忆的信息存储到特定的、与其他功能解耦的神经元集合中,从而使得后续移除这些记忆信息变得更加容易,且不会影响模型的通用能力。
技术框架:MemSinks的核心在于引入一个序列标识符(Sequence Identifier)。对于每个输入序列,该标识符会激活一组独特的神经元集合,这些神经元专门用于记忆该序列。整体训练流程与标准的LLM训练类似,但增加了对这些特定神经元的约束,鼓励模型将记忆任务分配给它们。在推理阶段,可以选择性地移除或修改这些神经元,从而达到移除记忆信息的目的。
关键创新:MemSinks的关键创新在于其“隔离记忆”的设计理念。与以往试图在模型训练完成后再进行记忆移除的方法不同,MemSinks从训练之初就引导模型将记忆任务分配给特定的神经元,从而避免了记忆内容与通用语言能力的纠缠。这种设计使得记忆移除更加精准和有效。
关键设计:序列标识符的具体实现方式未知,但其核心功能是为每个序列生成一个唯一的激活模式,用于选择特定的神经元集合。损失函数可能包含正则化项,用于鼓励记忆神经元的稀疏性,即每个神经元只负责记忆少数几个序列。具体的网络结构可能需要在标准LLM的基础上进行修改,以适应序列标识符的输入和记忆神经元的选择。
🖼️ 关键图片
📊 实验亮点
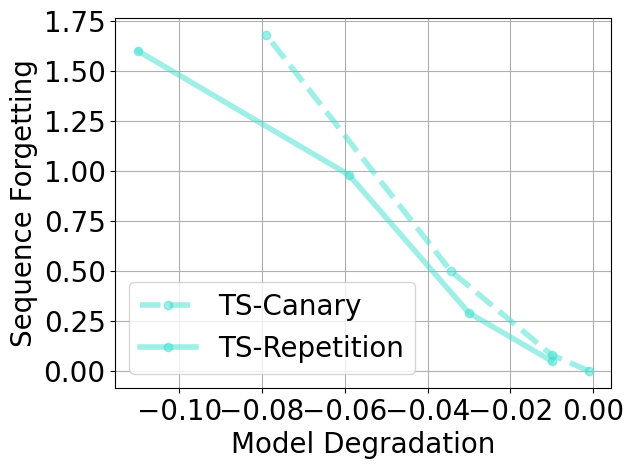
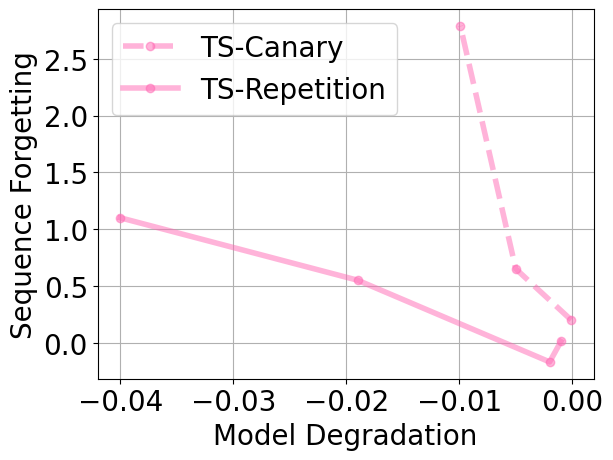
论文在数十亿参数和数十亿token规模的真实数据集上验证了MemSinks的有效性。实验结果表明,MemSinks能够有效地隔离记忆内容,使得在移除记忆信息的同时,模型的通用语言能力几乎不受影响。具体性能数据未知,但论文强调这是第一个在真实数据上证明同时实现泛化和隔离的概念验证。
🎯 应用场景
MemSinks技术可应用于各种需要保护隐私和版权的大型语言模型训练场景,例如:生成式对话系统、代码生成模型、文本摘要模型等。通过隔离记忆,可以有效防止模型泄露敏感信息或生成侵权内容,从而降低法律风险,提升用户信任度。该技术还有助于构建更加安全可靠的AI系统。
📄 摘要(原文)
Large language models are susceptible to memorizing repeated sequences, posing privacy and copyright concerns. A popular mitigation strategy is to remove memorized information from specific neurons post-hoc. However, such approaches have shown limited success so far. In a controlled setting, we show that the memorization of natural sequences (those that resemble linguistically plausible text) become mechanistically entangled with general language abilities, thereby becoming challenging to remove post-hoc. In this work, we put forward a new paradigm of MemSinks that promotes isolation of memorization by design. We leverage a sequence identifier that activates a unique set of memorization neurons for each sequence across repetitions. By analyzing the dynamics of learning and forgetting, we argue that MemSinks facilitates isolation of memorized content, making it easier to remove without compromising general language capabilities. We implement MemSinks at the billion-parameter and billion-token scale, and observe both effective isolation and strong generalization. To our knowledge, this is the first proof-of-concept on real data demonstrating that simultaneous generalization and isolation is achievable. We open-source our code at http://github.com/grghosal/MemSinks.