Algorithm Development in Neural Networks: Insights from the Streaming Parity Task
作者: Loek van Rossem, Andrew M. Saxe
分类: cs.LG, q-bio.NC
发布日期: 2025-07-14 (更新: 2025-08-06)
备注: 28 pages, 20 figures
💡 一句话要点
通过流式奇偶校验任务,揭示神经网络算法涌现的机制
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 循环神经网络 算法涌现 无限泛化 流式奇偶校验 表征学习 有限自动机 相变
📋 核心要点
- 现有神经网络研究主要关注分布内泛化,而忽略了神经网络在某些任务中表现出的无限泛化能力,即算法的真正理解。
- 该论文通过研究RNN在流式奇偶校验任务上的学习动态,揭示了神经网络如何从有限经验中学习并实现无限泛化的机制。
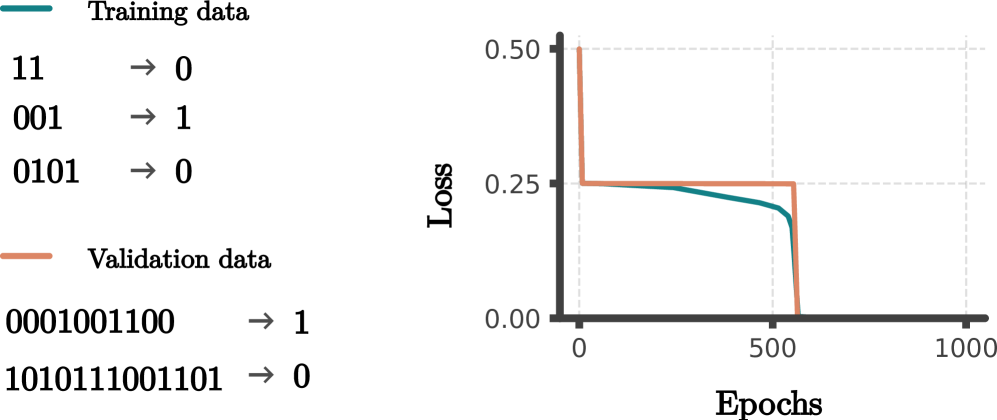
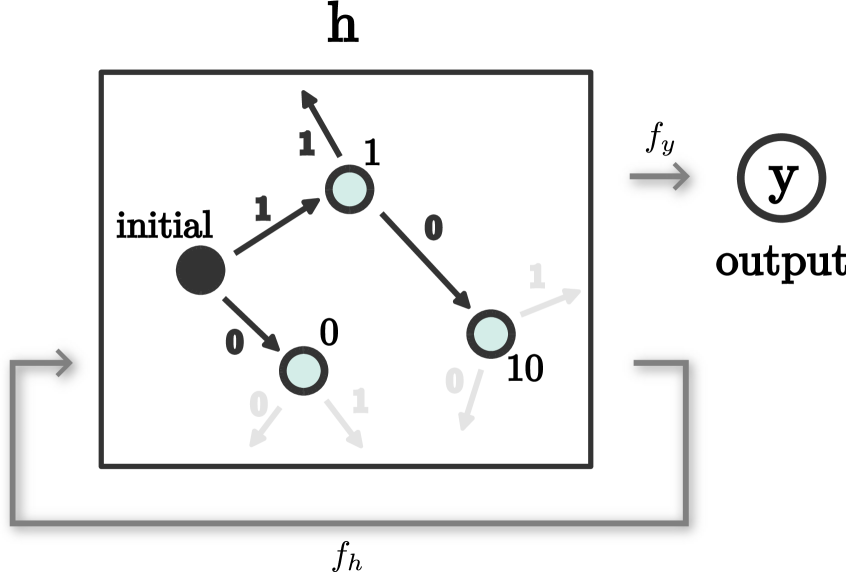
- 研究发现RNN在训练过程中会发生相变,最终构建出一个等价于解决该任务的有限自动机,从而实现无限泛化。
📝 摘要(中文)
深度神经网络即使在过度参数化的情况下,也表现出卓越的泛化能力。对此现象的研究主要集中在通过平滑插值实现的分布内泛化。然而,在某些情况下,神经网络也能外推到远远超出原始训练集范围的数据,有时甚至允许无限泛化,这意味着已经学习到能够解决任务的算法。本文以循环神经网络(RNN)在流式奇偶校验任务上的学习动态为例,深入研究算法涌现的有效理论。流式奇偶校验任务是一个简单但非线性的任务,定义在任意长度的序列上。我们表明,通过足够的有限训练经验,RNN会发生相变,从而实现完美的无限泛化。利用表征动态的有效理论,我们发现了一种隐式的表征合并效应,可以解释为构建了一个能够重现任务的有限自动机。总的来说,我们的结果揭示了神经网络可以通过有限的训练经验实现无限泛化的一种机制。
🔬 方法详解
问题定义:论文旨在研究神经网络如何从有限的训练数据中学习到能够无限泛化的算法。现有方法主要关注分布内的泛化,而忽略了神经网络在某些任务中表现出的外推能力,即从有限数据中学习到解决问题的通用算法。流式奇偶校验任务是一个典型的需要算法泛化的任务,传统的神经网络方法难以解释其泛化机制。
核心思路:论文的核心思路是通过分析RNN在流式奇偶校验任务上的学习动态,揭示神经网络内部表征的变化过程,从而理解算法涌现的机制。通过构建表征动态的有效理论,研究人员发现了一种隐式的表征合并效应,这种效应可以解释为神经网络构建了一个等价于解决该任务的有限自动机。
技术框架:该研究主要分为以下几个阶段:首先,使用RNN在流式奇偶校验任务上进行训练;然后,分析RNN内部表征随训练时间的变化;接着,构建表征动态的有效理论,用于描述表征合并效应;最后,将学习到的表征与有限自动机进行对比,验证神经网络是否学习到了解决该任务的算法。
关键创新:该论文的关键创新在于揭示了神经网络通过表征合并效应学习算法的机制。与传统的泛化理论不同,该研究关注的是神经网络如何从有限数据中学习到能够无限泛化的算法,而不是仅仅在训练数据分布附近进行插值。
关键设计:论文使用了标准的RNN结构,并采用交叉熵损失函数进行训练。关键在于对RNN内部表征的分析,通过观察表征随训练时间的变化,发现表征逐渐合并成几个离散的状态,这些状态对应于有限自动机的状态。研究人员还设计了一种有效理论来描述这种表征合并效应。
🖼️ 关键图片

📊 实验亮点
研究表明,经过有限的训练,RNN可以实现流式奇偶校验任务的完美无限泛化。通过分析RNN的内部表征,发现了一种隐式的表征合并效应,这种效应可以解释为RNN构建了一个等价于解决该任务的有限自动机。该研究为理解神经网络如何从有限经验中学习算法提供了新的视角。
🎯 应用场景
该研究成果有助于理解神经网络的泛化能力,并为设计更具泛化能力的神经网络架构提供指导。潜在应用领域包括序列建模、自然语言处理、机器人控制等,尤其是在需要从少量数据中学习复杂算法的场景下具有重要价值。未来可以进一步研究该机制在其他任务和网络结构上的适用性。
📄 摘要(原文)
Even when massively overparameterized, deep neural networks show a remarkable ability to generalize. Research on this phenomenon has focused on generalization within distribution, via smooth interpolation. Yet in some settings neural networks also learn to extrapolate to data far beyond the bounds of the original training set, sometimes even allowing for infinite generalization, implying that an algorithm capable of solving the task has been learned. Here we undertake a case study of the learning dynamics of recurrent neural networks (RNNs) trained on the streaming parity task in order to develop an effective theory of algorithm development. The streaming parity task is a simple but nonlinear task defined on sequences up to arbitrary length. We show that, with sufficient finite training experience, RNNs exhibit a phase transition to perfect infinite generalization. Using an effective theory for the representational dynamics, we find an implicit representational merger effect which can be interpreted as the construction of a finite automaton that reproduces the task. Overall, our results disclose one mechanism by which neural networks can generalize infinitely from finite training experience.