Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment Dataset
作者: Lily Hong Zhang, Smitha Milli, Karen Jusko, Jonathan Smith, Brandon Amos, Wassim Bouaziz, Manon Revel, Jack Kussman, Yasha Sheynin, Lisa Titus, Bhaktipriya Radharapu, Jane Yu, Vidya Sarma, Kris Rose, Maximilian Nickel
分类: cs.LG
发布日期: 2025-07-13 (更新: 2025-10-24)
💡 一句话要点
提出Community Alignment数据集,解决LLM在多元文化偏好对齐上的挑战。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏好对齐 多元文化 负相关抽样 数据集构建
📋 核心要点
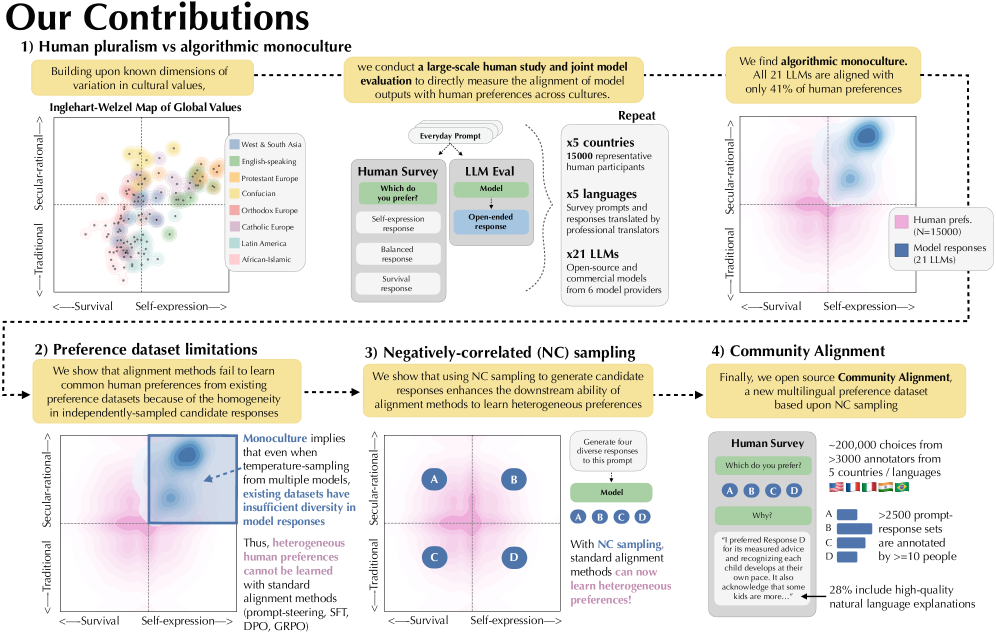
- 现有LLM在处理文化、政治等维度上存在冲突的用户偏好时表现不足,无法充分捕捉人类偏好的多样性。
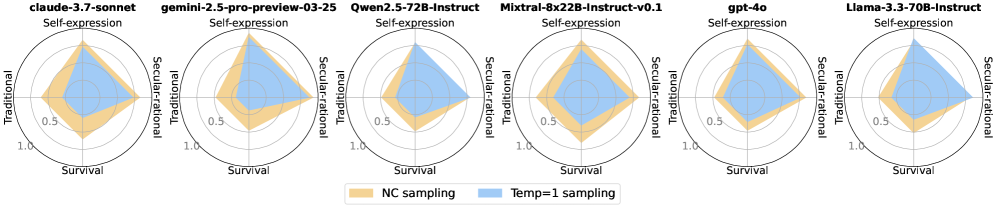
- 论文提出一种负相关抽样方法,用于生成更多样化的候选响应,从而提升LLM学习异构偏好的能力。
- 通过收集包含近20万次比较的Community Alignment数据集,验证了所提方法的有效性,并为后续研究提供了资源。
📝 摘要(中文)
本文旨在解决大型语言模型(LLM)如何服务于具有不同偏好的用户,这些偏好可能在文化、政治或其他维度上存在冲突。研究通过大规模多语言人工研究(N=15,000,来自五个国家)表明,人类在偏好方面表现出比21个最先进的LLM更多的差异。现有偏好数据集收集方法不足以学习人类偏好的多样性,即使沿着全球价值观中最显著的两个维度也是如此,这是由于候选响应的同质性。因此,论文提出在生成候选集时需要负相关的抽样,并展示了基于prompt的简单技术可以显著提高对齐方法在学习异构偏好方面的性能。基于这种新的候选抽样方法,研究收集并开源了Community Alignment,这是迄今为止最大、最具代表性的多语言和多轮偏好数据集,包含来自五个国家注释者的近20万次比较。希望Community Alignment数据集能够成为提高LLM对不同全球人群有效性的宝贵资源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对具有文化、政治等差异的多元用户群体时,如何更好地对齐不同甚至冲突的偏好。现有方法,包括现有的偏好数据集收集方法,无法充分捕捉人类偏好的多样性,导致LLM在服务不同文化背景用户时表现不佳。现有数据集的候选响应同质性高,无法有效训练模型识别和适应不同偏好。
核心思路:论文的核心思路是通过引入负相关抽样,生成更多样化的候选响应集合。具体来说,就是有意识地选择那些与已有候选答案在价值观或偏好上相反或不同的答案,从而扩大候选答案的覆盖范围,提高数据集的多样性。这样,模型在训练时就能接触到更广泛的偏好,从而更好地学习和适应不同用户的需求。
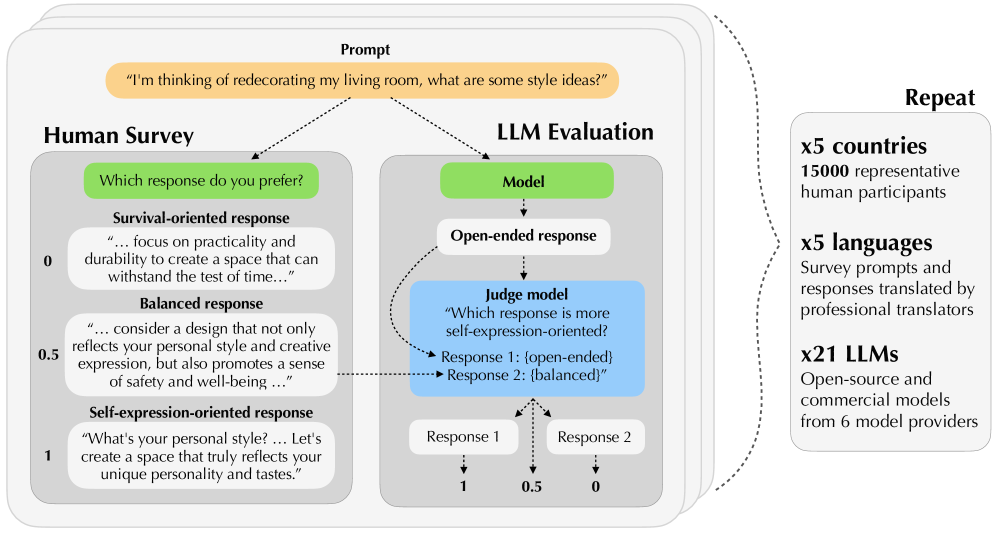
技术框架:论文的技术框架主要包含以下几个阶段:1) 设计基于prompt的负相关抽样方法,用于生成候选响应集合;2) 通过大规模多语言人工研究,收集用户对不同候选响应的偏好数据;3) 构建Community Alignment数据集,包含来自五个国家注释者的近20万次比较;4) 使用Community Alignment数据集训练LLM,并评估其在处理多元用户偏好方面的性能。
关键创新:论文最重要的技术创新点在于提出了负相关抽样方法,用于生成更多样化的候选响应集合。与传统的随机抽样或基于相似性的抽样方法不同,负相关抽样有意识地选择那些与已有候选答案在价值观或偏好上相反或不同的答案,从而扩大候选答案的覆盖范围,提高数据集的多样性。
关键设计:论文的关键设计包括:1) 设计不同的prompt模板,用于引导LLM生成具有不同偏好的候选响应;2) 使用多语言注释者,确保数据集的文化多样性;3) 采用多轮对话的形式,捕捉用户在不同情境下的偏好;4) 使用合适的评估指标,评估LLM在处理多元用户偏好方面的性能。
🖼️ 关键图片
📊 实验亮点
论文通过大规模多语言人工研究(N=15,000)表明,人类在偏好方面表现出比21个最先进的LLM更多的差异。使用负相关抽样方法生成的候选集,能够显著提高对齐方法在学习异构偏好方面的性能。Community Alignment数据集包含来自五个国家注释者的近20万次比较,是迄今为止最大、最具代表性的多语言和多轮偏好数据集。
🎯 应用场景
该研究成果可应用于各种需要处理多元用户偏好的场景,例如个性化推荐系统、智能客服、内容生成等。通过更好地理解和适应不同用户的偏好,可以提高用户满意度、增强用户粘性,并促进跨文化交流和理解。未来,该研究还可以扩展到更多领域,例如医疗、教育等,为不同背景的用户提供更个性化、更有效的服务。
📄 摘要(原文)
How can large language models (LLMs) serve users with varying preferences that may conflict across cultural, political, or other dimensions? To advance this challenge, this paper establishes four key results. First, we demonstrate, through a large-scale multilingual human study with representative samples from five countries (N=15,000), that humans exhibit significantly more variation in preferences than the responses of 21 state-of-the-art LLMs. Second, we show that existing methods for preference dataset collection are insufficient for learning the diversity of human preferences even along two of the most salient dimensions of variability in global values, due to the underlying homogeneity of candidate responses. Third, we argue that this motivates the need for negatively-correlated sampling when generating candidate sets, and we show that simple prompt-based techniques for doing so significantly enhance the performance of alignment methods in learning heterogeneous preferences. Fourth, based on this novel candidate sampling approach, we collect and open-source Community Alignment, the largest and most representative multilingual and multi-turn preference dataset to date, featuring almost 200,000 comparisons from annotators spanning five countries. We hope that the Community Alignment dataset will be a valuable resource for improving the effectiveness of LLMs for a diverse global population.