Temporal Misalignment Attacks against Multimodal Perception in Autonomous Driving
作者: Md Hasan Shahriar, Md Mohaimin Al Barat, Harshavardhan Sundar, Ning Zhang, Naren Ramakrishnan, Y. Thomas Hou, Wenjing Lou
分类: cs.LG
发布日期: 2025-07-12 (更新: 2025-10-01)
备注: 15 pages
💡 一句话要点
提出DejaVu攻击以解决自动驾驶多模态感知的时间对齐问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 自动驾驶 时间对齐 网络攻击 感知系统 安全性评估 激光雷达 摄像头
📋 核心要点
- 现有的多模态融合方法过于依赖精确的时间同步,导致在传感器流延迟情况下感知性能显著下降。
- 本文提出DejaVu攻击,通过引入传感器流的延迟,造成时间错位,从而影响多模态融合的感知任务。
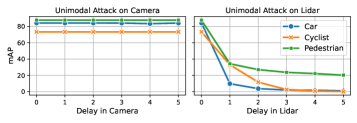
- 实验结果表明,激光雷达和摄像头在不同任务中的敏感性不平衡,攻击可导致汽车检测和跟踪精度大幅下降。
📝 摘要(中文)
多模态融合在自动驾驶感知中至关重要,主要通过融合摄像头和激光雷达数据实现全面的场景理解。然而,过于依赖精确的时间同步使其面临新的脆弱性。本文提出DejaVu攻击,利用车载网络引入传感器流延迟,造成微妙的时间错位,从而严重降低基于多模态融合的感知任务性能。我们的攻击分析显示,传感器对不同任务的敏感性不平衡:物体检测过于依赖激光雷达输入,而物体跟踪则高度依赖摄像头输入。通过单帧激光雷达延迟,攻击者可以将汽车检测的mAP降低至88.5%;而三帧摄像头延迟则使汽车的多目标跟踪精度下降73%。我们还通过汽车以太网测试平台和Autoware堆栈进行了两种攻击场景的验证,展示了DejaVu攻击的可行性及其严重影响,如碰撞和虚假刹车。
🔬 方法详解
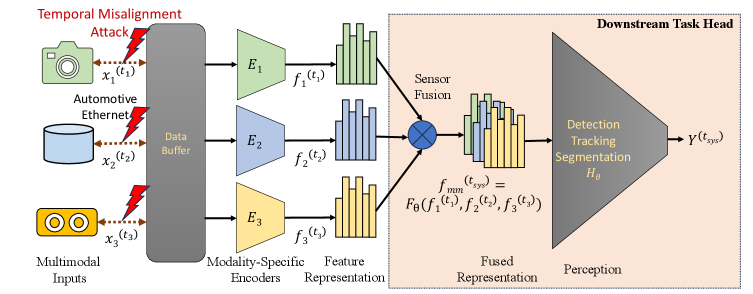
问题定义:本文解决的是自动驾驶系统中多模态感知对时间同步的严格依赖所带来的脆弱性。现有方法在传感器流延迟时,感知性能显著下降,影响安全性。
核心思路:论文提出DejaVu攻击,利用车载网络引入传感器流延迟,制造时间错位,进而影响多模态融合的感知任务。通过这种方式,攻击者可以在不被检测的情况下,显著降低感知系统的性能。
技术框架:整体架构包括攻击模型、传感器流延迟引入模块和感知任务评估模块。攻击模型通过控制网络延迟,影响激光雷达和摄像头数据的同步,进而评估对物体检测和跟踪的影响。
关键创新:最重要的创新在于识别并利用传感器对不同任务的敏感性不平衡,针对性地设计攻击策略,使得攻击效果最大化。与现有方法相比,DejaVu攻击能够在较小的延迟下造成显著的性能下降。
关键设计:在攻击实施过程中,设置了不同的延迟参数,并评估其对mAP和MOTA的影响。使用的损失函数和网络结构经过优化,以确保攻击效果的有效性和可重复性。实验中使用了多种数据集和模型进行验证。
🖼️ 关键图片

📊 实验亮点
实验结果显示,单帧激光雷达延迟可使汽车检测的mAP降低高达88.5%,而三帧摄像头延迟则使多目标跟踪精度下降73%。这些结果表明,DejaVu攻击在实际应用中具有显著的破坏性,能够导致严重的安全隐患,如碰撞和虚假刹车。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶系统的安全性评估和防御机制设计。通过识别多模态感知中的脆弱性,可以帮助开发更为鲁棒的自动驾驶技术,提升交通安全性和系统可靠性。未来,相关技术也可扩展至其他依赖多模态数据的智能系统中。
📄 摘要(原文)
Multimodal fusion (MMF) plays a critical role in the perception of autonomous driving, which primarily fuses camera and LiDAR streams for a comprehensive and efficient scene understanding. However, its strict reliance on precise temporal synchronization exposes it to new vulnerabilities. In this paper, we introduce DejaVu, an attack that exploits the in-vehicular network and induces delays across sensor streams to create subtle temporal misalignments, severely degrading downstream MMF-based perception tasks. Our comprehensive attack analysis across different models and datasets reveals the sensors' task-specific imbalanced sensitivities: object detection is overly dependent on LiDAR inputs, while object tracking is highly reliant on the camera inputs. Consequently, with a single-frame LiDAR delay, an attacker can reduce the car detection mAP by up to 88.5%, while with a three-frame camera delay, multiple object tracking accuracy (MOTA) for car drops by 73%. We further demonstrated two attack scenarios using an automotive Ethernet testbed for hardware-in-the-loop validation and the Autoware stack for end-to-end AD simulation, demonstrating the feasibility of the DejaVu attack and its severe impact, such as collisions and phantom braking.