Action Chunking and Exploratory Data Collection Yield Exponential Improvements in Behavior Cloning for Continuous Control
作者: Thomas T. Zhang, Daniel Pfrommer, Chaoyi Pan, Nikolai Matni, Max Simchowitz
分类: cs.LG, eess.SY, stat.ML
发布日期: 2025-07-11 (更新: 2025-11-26)
备注: Updated manuscript. New visualization figures and control-theory primer
💡 一句话要点
通过动作分块与探索性数据收集,行为克隆在连续控制任务上获得指数级提升
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 行为克隆 连续控制 动作分块 探索性数据收集 控制理论 机器人学习
📋 核心要点
- 模仿学习在连续控制中面临误差随时间指数增长的挑战,限制了其应用。
- 论文提出动作分块和探索性数据收集两种方法,利用控制理论稳定性来缓解误差累积。
- 实验验证了所提方法的有效性,并在理论上提供了更严格的误差界限保证。
📝 摘要(中文)
本文对机器人和连续控制中,两种影响深远的示范学习干预手段进行了理论分析:动作分块(以开环方式预测动作序列)和专家示范数据的探索性增强。尽管最近的研究表明,在连续环境中,示范学习(也称为模仿学习,IL)可能遭受随任务时间跨度呈指数增长的误差累积,但我们证明了动作分块和探索性数据收集可以在不同的情况下规避这种指数级的误差累积。我们的结果表明,控制理论稳定性是这些干预措施带来收益的关键机制。在实验方面,我们通过在流行的机器人学习基准上进行实验,验证了我们的预测以及控制理论稳定性的作用。在理论方面,我们证明了控制理论视角能够提供对误差累积如何产生的细粒度见解,从而在应用这些干预措施时,相比于仅基于信息论考虑的先前技术,能够得到更严格的模仿学习误差统计保证。
🔬 方法详解
问题定义:论文旨在解决连续控制任务中,模仿学习(IL)因误差累积而导致性能下降的问题。传统的模仿学习方法,特别是行为克隆(Behavior Cloning),在长时程任务中会因为预测动作的微小偏差,导致状态分布偏离专家轨迹,从而产生指数级的误差累积。现有方法难以有效应对这种误差累积现象。
核心思路:论文的核心思路是利用控制理论中的稳定性概念,来分析和缓解模仿学习中的误差累积。具体而言,通过动作分块和探索性数据收集两种方式,增强系统的控制稳定性,从而限制状态分布的偏离,降低误差累积的速度。动作分块通过预测动作序列,减少了单步预测误差的影响;探索性数据收集则通过增加对未知状态的覆盖,提高了模型的泛化能力。
技术框架:论文的整体框架包括以下几个关键部分:首先,对模仿学习中的误差累积进行控制理论分析,建立误差增长与系统稳定性之间的关系模型。其次,提出动作分块和探索性数据收集两种干预手段,并分析其对系统稳定性的影响。然后,通过实验验证这些干预手段的有效性。最后,从理论上推导了在这些干预手段下的更严格的误差界限。
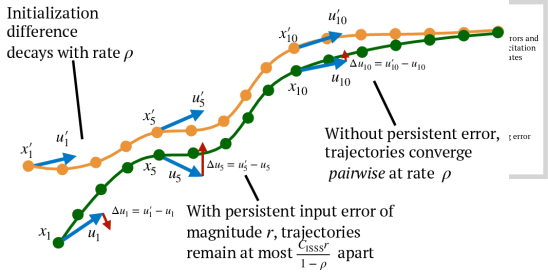
关键创新:论文最重要的创新点在于将控制理论引入模仿学习的分析中,并以此为基础提出了动作分块和探索性数据收集两种有效的干预手段。与以往基于信息论的分析方法不同,控制理论的视角能够提供更细粒度的误差分析,从而指导更有效的算法设计。
关键设计:动作分块的关键设计在于确定合适的动作序列长度。序列长度过短,则无法有效减少单步预测误差的影响;序列长度过长,则可能导致预测难度增加。探索性数据收集的关键设计在于如何有效地探索未知状态。一种常用的方法是添加噪声到专家动作中,或者使用随机策略进行探索。损失函数通常采用均方误差(MSE)或交叉熵损失函数,用于衡量预测动作与专家动作之间的差异。
🖼️ 关键图片

📊 实验亮点
论文通过在多个机器人学习基准测试中进行实验,验证了动作分块和探索性数据收集的有效性。实验结果表明,与传统的行为克隆方法相比,采用这两种干预手段后,模仿学习的性能得到了显著提升,误差累积速度明显降低。具体性能提升数据未知。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域。通过动作分块和探索性数据收集,可以显著提高模仿学习在复杂连续控制任务中的性能和鲁棒性,降低对大量专家数据的依赖,加速智能体在真实环境中的部署。
📄 摘要(原文)
This paper presents a theoretical analysis of two of the most impactful interventions in modern learning from demonstration in robotics and continuous control: the practice of action-chunking (predicting sequences of actions in open-loop) and exploratory augmentation of expert demonstrations. Though recent results show that learning from demonstration, also known as imitation learning (IL), can suffer errors that compound exponentially with task horizon in continuous settings, we demonstrate that action chunking and exploratory data collection circumvent exponential compounding errors in different regimes. Our results identify control-theoretic stability as the key mechanism underlying the benefits of these interventions. On the empirical side, we validate our predictions and the role of control-theoretic stability through experimentation on popular robot learning benchmarks. On the theoretical side, we demonstrate that the control-theoretic lens provides fine-grained insights into how compounding error arises, leading to tighter statistical guarantees on imitation learning error when these interventions are applied than previous techniques based on information-theoretic considerations alone.