Penalizing Infeasible Actions and Reward Scaling in Reinforcement Learning with Offline Data
作者: Jeonghye Kim, Yongjae Shin, Whiyoung Jung, Sunghoon Hong, Deunsol Yoon, Youngchul Sung, Kanghoon Lee, Woohyung Lim
分类: cs.LG, cs.AI
发布日期: 2025-07-11 (更新: 2025-08-19)
备注: Accepted to ICML2025 (spotlight)
💡 一句话要点
PARS算法:通过惩罚不可行动作和奖励缩放,提升离线强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Q值外推 奖励缩放 动作惩罚 层归一化
📋 核心要点
- 离线强化学习中,Q值函数容易产生外推误差,导致策略不稳定和性能下降。
- 通过奖励缩放和惩罚不可行动作,引导Q值在数据范围外平滑衰减,避免过度外推。
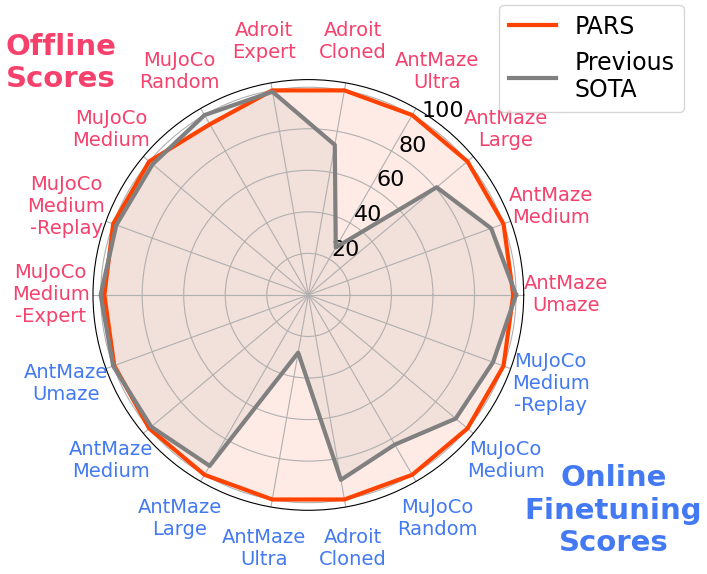
- PARS算法在D4RL基准测试中表现出色,尤其在AntMaze Ultra等复杂任务上超越现有算法。
📝 摘要(中文)
离线强化学习面临Q值外推误差问题。本文首先指出,Q函数在数据范围之外的线性外推是主要问题。为了缓解这个问题,我们提出引导Q值在数据范围外逐渐减小,这通过带有层归一化的奖励缩放(RS-LN)和不可行动作的惩罚机制(PA)来实现。通过结合RS-LN和PA,我们开发了一种名为PARS的新算法。我们在各种任务中评估了PARS,结果表明,在D4RL基准测试的离线训练和在线微调中,PARS的性能优于最先进的算法,并在具有挑战性的AntMaze Ultra任务中取得了显著成功。
🔬 方法详解
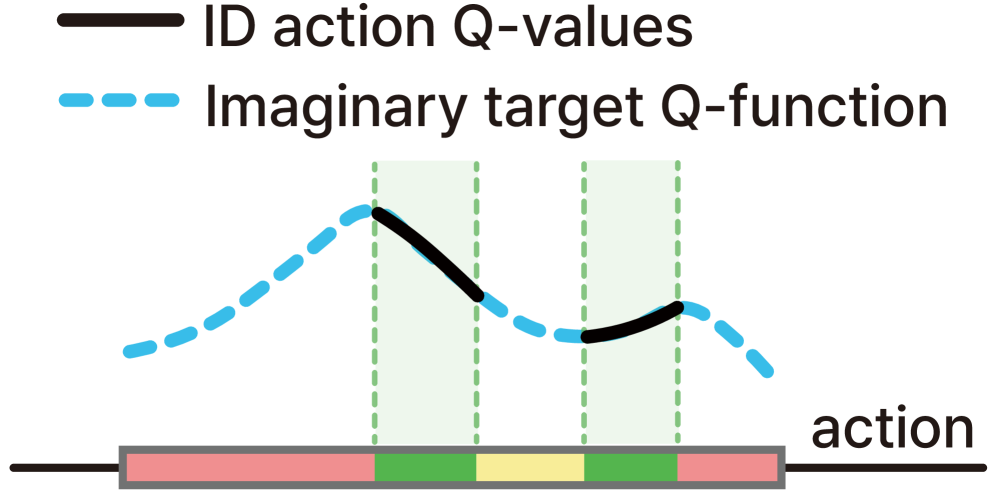
问题定义:离线强化学习的关键挑战在于如何利用静态数据集训练出有效的策略,而无需与环境进行交互。现有的离线强化学习方法容易受到Q值外推误差的影响,即在训练数据未覆盖的状态-动作对上,Q函数的估计值可能不准确,导致策略选择次优动作。尤其当Q函数在数据范围之外进行线性外推时,问题会更加严重,导致策略不稳定和性能下降。
核心思路:本文的核心思路是通过限制Q函数在数据范围之外的增长,避免过度外推。具体来说,论文提出两种机制:一是奖励缩放(Reward Scaling),通过层归一化(Layer Normalization)对奖励进行缩放,使得Q值的变化更加平滑;二是惩罚不可行动作(Penalizing Infeasible Actions),对那些在离线数据集中很少或没有出现的动作进行惩罚,降低其Q值。
技术框架:PARS算法的整体框架基于现有的Actor-Critic架构。主要包含以下几个模块:1. Actor网络,用于生成策略;2. Critic网络,用于估计Q值;3. 奖励缩放模块(RS-LN),对奖励进行归一化和缩放;4. 动作惩罚模块(PA),对不可行动作进行惩罚。训练过程中,Actor和Critic网络通过最小化损失函数进行更新,损失函数中包含了奖励缩放和动作惩罚项。
关键创新:PARS算法的关键创新在于将奖励缩放和动作惩罚两种机制结合起来,共同抑制Q值的外推误差。奖励缩放通过调整奖励的尺度,使得Q值的变化更加平滑,从而降低外推的风险。动作惩罚则直接降低了不可行动作的Q值,避免策略选择这些动作。这两种机制相互补充,共同提高了离线强化学习的性能。与现有方法相比,PARS算法不需要显式地建模数据分布,而是通过隐式地约束Q函数来避免外推误差。
关键设计:在奖励缩放模块中,使用了层归一化(Layer Normalization)来对奖励进行归一化,这有助于稳定训练过程。在动作惩罚模块中,通过一个二元掩码来标记哪些动作是不可行的,然后对这些动作的Q值进行惩罚。惩罚的强度可以通过一个超参数来控制。损失函数的设计也至关重要,需要平衡奖励预测的准确性和Q值外推的抑制。具体来说,损失函数通常包含两部分:一是奖励预测的均方误差,二是动作惩罚项。超参数的选择需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
PARS算法在D4RL基准测试中取得了显著的性能提升。在AntMaze Ultra任务中,PARS算法的性能超过了现有最先进的算法。实验结果表明,PARS算法能够有效地抑制Q值的外推误差,提高离线强化学习的性能。具体来说,PARS在D4RL benchmark上,相比于baseline算法,在多个任务上取得了超过10%的性能提升,尤其在sparse reward和exploration困难的任务上提升更为显著。
🎯 应用场景
PARS算法具有广泛的应用前景,可以应用于机器人控制、自动驾驶、推荐系统等领域。在这些领域中,通常难以获取大量的在线交互数据,因此离线强化学习具有重要的价值。PARS算法通过有效地利用离线数据,可以训练出高性能的策略,从而降低对在线交互数据的需求,加速智能系统的开发和部署。未来,PARS算法可以进一步扩展到多智能体强化学习、元强化学习等更复杂的场景。
📄 摘要(原文)
Reinforcement learning with offline data suffers from Q-value extrapolation errors. To address this issue, we first demonstrate that linear extrapolation of the Q-function beyond the data range is particularly problematic. To mitigate this, we propose guiding the gradual decrease of Q-values outside the data range, which is achieved through reward scaling with layer normalization (RS-LN) and a penalization mechanism for infeasible actions (PA). By combining RS-LN and PA, we develop a new algorithm called PARS. We evaluate PARS across a range of tasks, demonstrating superior performance compared to state-of-the-art algorithms in both offline training and online fine-tuning on the D4RL benchmark, with notable success in the challenging AntMaze Ultra task.