AbbIE: Autoregressive Block-Based Iterative Encoder for Efficient Sequence Modeling
作者: Preslav Aleksandrov, Meghdad Kurmanji, Fernando Garcia Redondo, David O'Shea, William Shen, Alex Iacob, Lorenzo Sani, Xinchi Qiu, Nicola Cancedda, Nicholas D. Lane
分类: cs.LG
发布日期: 2025-07-11 (更新: 2025-08-07)
备注: 14 pages and 6 figures. Submitted to NeurIPS 2025
💡 一句话要点
提出基于自回归块的迭代编码器AbbIE,提升序列建模效率并支持动态计算缩放。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自回归模型 迭代编码器 Transformer 序列建模 动态计算 语言模型 zero-shot学习
📋 核心要点
- 现有Transformer模型在处理复杂序列时计算成本高昂,且难以根据任务复杂度动态调整计算资源。
- AbbIE通过递归迭代的方式在潜在空间中进行编码,允许模型根据需要动态增加计算量,提升效率。
- 实验表明,AbbIE在zero-shot in-context learning和语言困惑度上均优于传统Transformer和其它迭代方法。
📝 摘要(中文)
本文介绍了一种新颖的递归式Transformer架构泛化方法,即自回归块迭代编码器(AbbIE)。AbbIE在标准Transformer的基础上实现了更好的困惑度,并允许在测试时动态缩放计算资源。这种简单的递归方法是对通过参数和token数量扩展大型语言模型(LLM)性能的一种补充。AbbIE在潜在空间中执行迭代,但与潜在推理模型不同,它不需要专门的数据集或训练协议。我们证明了AbbIE在测试时具有向上泛化能力(能够泛化到任意迭代长度),仅使用2次迭代进行训练,就远远优于其他迭代方法。AbbIE能够根据任务的复杂性来扩展其计算支出,与其他迭代和标准方法相比,在zero-shot in-context learning任务中获得了高达12%的改进,在语言困惑度方面获得了高达5%的改进。这项研究的结果为Transformer性能扩展开辟了一条新途径。我们所有的评估都是在高达3.5亿参数的模型尺寸上进行的。
🔬 方法详解
问题定义:现有Transformer模型在处理长序列时,计算复杂度呈平方级增长,导致计算成本高昂。此外,传统的Transformer模型在推理阶段的计算量是固定的,无法根据输入序列的复杂程度动态调整计算资源,造成了资源浪费或性能瓶颈。
核心思路:AbbIE的核心思路是通过迭代的方式,在潜在空间中逐步提炼序列的表示。每次迭代都基于前一次迭代的结果进行更新,从而允许模型逐步逼近最优解。这种迭代的方式使得模型可以根据任务的复杂程度动态调整计算量,从而提高效率。
技术框架:AbbIE的整体架构基于Transformer encoder,但引入了迭代机制。模型首先将输入序列编码到潜在空间,然后通过多个迭代块进行处理。每个迭代块包含一个Transformer encoder层,用于更新潜在表示。迭代过程可以重复多次,直到达到预定的迭代次数或满足某种收敛条件。最终,模型将最终的潜在表示解码为输出序列。
关键创新:AbbIE的关键创新在于其递归迭代的结构和在潜在空间中进行迭代的能力。与传统的Transformer模型相比,AbbIE可以通过迭代的方式逐步提炼序列的表示,从而提高模型的表达能力。与潜在推理模型相比,AbbIE不需要专门的数据集或训练协议,可以直接在标准数据集上进行训练。
关键设计:AbbIE的关键设计包括迭代次数的选择、迭代块的结构和损失函数的设计。迭代次数可以根据任务的复杂程度进行调整。迭代块的结构可以采用标准的Transformer encoder层,也可以采用其他更复杂的结构。损失函数可以采用标准的交叉熵损失函数,也可以采用其他更适合迭代模型的损失函数。论文中使用了2次迭代进行训练,并在测试时验证了向上泛化的能力。
🖼️ 关键图片


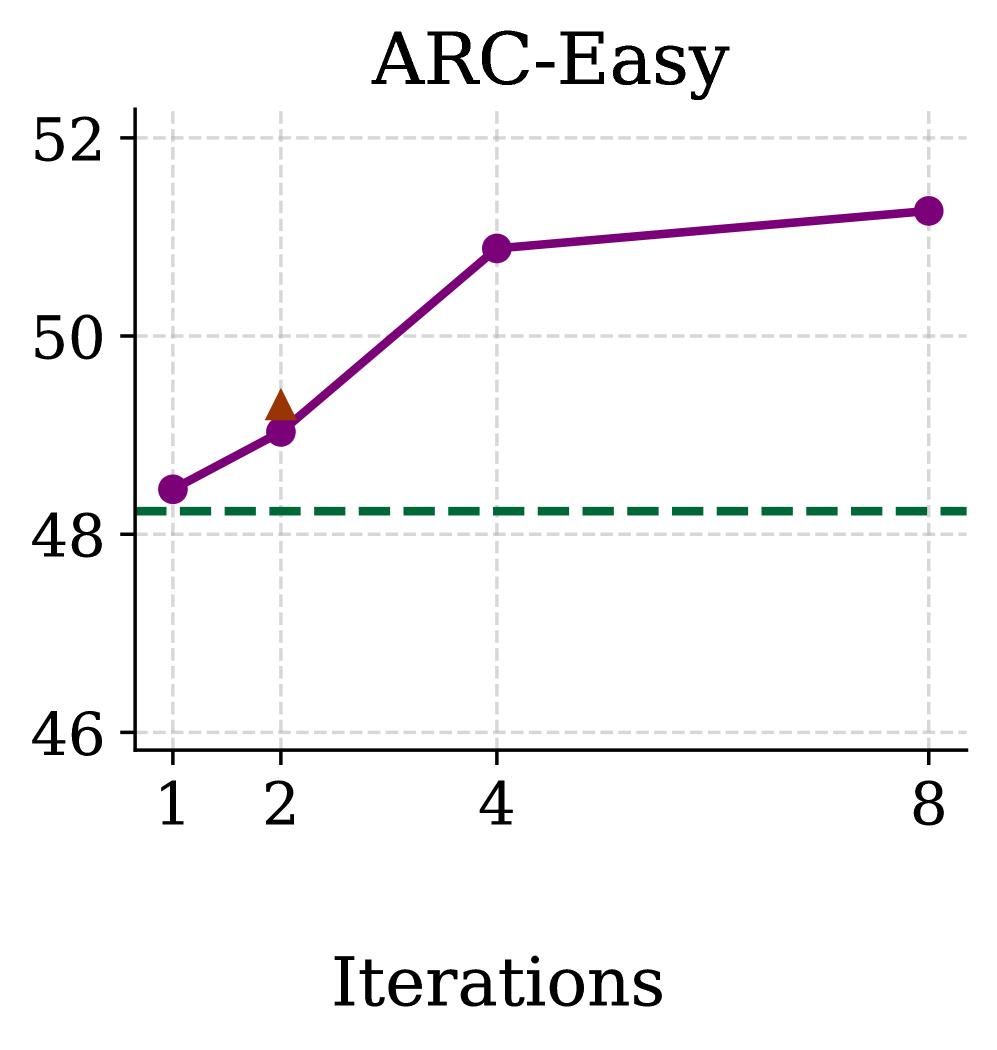
📊 实验亮点
实验结果表明,AbbIE在zero-shot in-context learning任务中获得了高达12%的改进,在语言困惑度方面获得了高达5%的改进。此外,AbbIE仅使用2次迭代进行训练,就能够泛化到任意迭代长度,显示了其强大的泛化能力。这些结果表明,AbbIE是一种非常有前景的序列建模方法。
🎯 应用场景
AbbIE具有广泛的应用前景,例如自然语言处理、语音识别、计算机视觉等领域。它可以用于处理长文本、音频和视频序列,提高模型的性能和效率。此外,AbbIE的动态计算缩放能力使其非常适合于资源受限的设备,例如移动设备和嵌入式系统。
📄 摘要(原文)
We introduce the Autoregressive Block-Based Iterative Encoder (AbbIE), a novel recursive generalization of the encoder-only Transformer architecture, which achieves better perplexity than a standard Transformer and allows for the dynamic scaling of compute resources at test time. This simple, recursive approach is a complement to scaling large language model (LLM) performance through parameter and token counts. AbbIE performs its iterations in latent space, but unlike latent reasoning models, does not require a specialized dataset or training protocol. We show that AbbIE upward generalizes (ability to generalize to arbitrary iteration lengths) at test time by only using 2 iterations during train time, far outperforming alternative iterative methods. AbbIE's ability to scale its computational expenditure based on the complexity of the task gives it an up to \textbf{12\%} improvement in zero-shot in-context learning tasks versus other iterative and standard methods and up to 5\% improvement in language perplexity. The results from this study open a new avenue to Transformer performance scaling. We perform all of our evaluations on model sizes up to 350M parameters.