Quantile Reward Policy Optimization: Alignment with Pointwise Regression and Exact Partition Functions
作者: Simon Matrenok, Skander Moalla, Caglar Gulcehre
分类: cs.LG
发布日期: 2025-07-10 (更新: 2025-11-30)
备注: 58 pages, NeurIPS2025 camera-ready version
💡 一句话要点
提出分位数奖励策略优化(QRPO),实现绝对奖励下的离线策略对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分位数奖励 策略优化 离线学习 语言模型对齐 KL正则化
📋 核心要点
- 现有方法如DPO等无法直接利用绝对奖励进行离线策略优化,限制了数据利用率。
- QRPO通过分位数奖励实现KL正则化RL目标的闭式解回归,简化了离线优化。
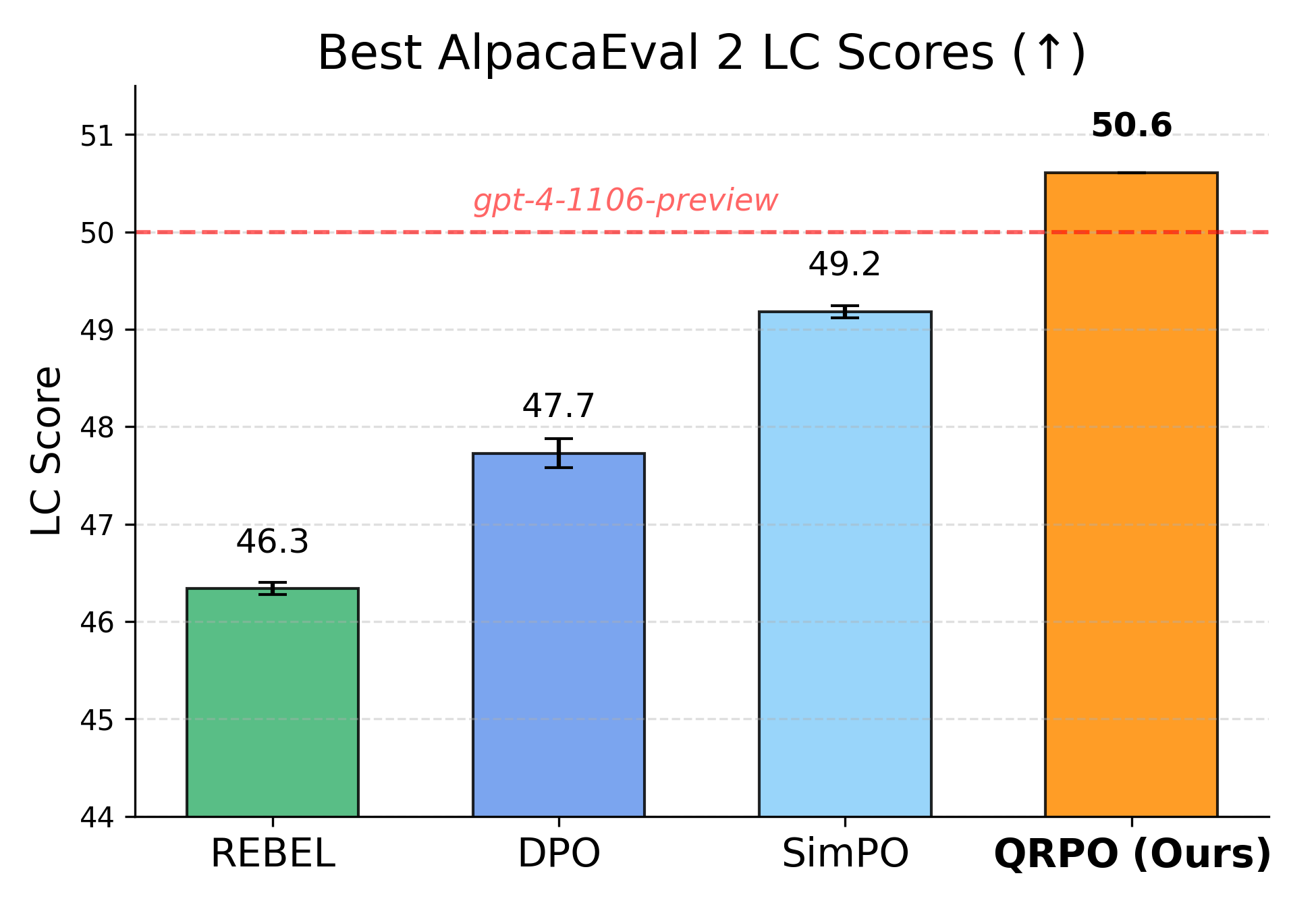
- 实验表明,QRPO在聊天和编码任务上优于DPO等方法,并能有效减少长度偏差。
📝 摘要(中文)
目前,将大型语言模型与逐点绝对奖励对齐通常需要在线、on-policy算法,如PPO和GRPO。相比之下,DPO和REBEL等更简单的方法只能从偏好对或相对信号中学习,无法利用离线或off-policy数据。为了弥合这一差距,我们引入了分位数奖励策略优化(QRPO),它从逐点绝对奖励中学习,同时保留了DPO类方法的简单性和离线适用性。QRPO使用分位数奖励来实现KL正则化RL目标的闭式解回归。这种奖励产生了一个解析上易于处理的配分函数,无需相对信号来消除该项。此外,QRPO可以通过增加计算量来估计分位数奖励,从而开辟了预计算扩展的新维度。在经验上,与DPO、REBEL和SimPO相比,QRPO在各种数据集和8B规模模型上始终在聊天和编码评估(奖励模型分数、AlpacaEval 2和LeetCode)中取得最佳性能。最后,我们发现使用鲁棒奖励而不是将其转换为偏好可以减少长度偏差。
🔬 方法详解
问题定义:现有方法,如DPO和REBEL,在对齐大型语言模型时,主要依赖于偏好对或相对信号进行学习,无法直接利用逐点绝对奖励。这限制了离线数据的利用,因为获取偏好数据通常比获取绝对奖励更困难。因此,如何设计一种能够直接从绝对奖励中学习,并且能够像DPO一样进行离线策略优化的方法,是一个重要的挑战。
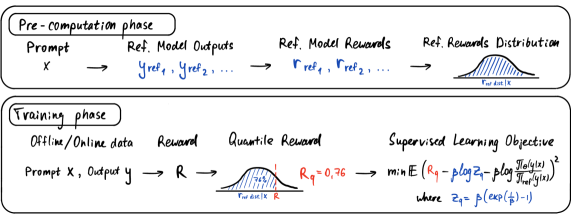
核心思路:QRPO的核心思路是利用分位数奖励来近似绝对奖励,并将其用于KL正则化强化学习目标的闭式解回归。通过将绝对奖励转化为分位数,可以得到一个解析上易于处理的配分函数,从而避免了像DPO那样需要相对信号来消除配分函数项的限制。这种方法使得可以直接从绝对奖励中学习,并且保留了DPO类方法的离线适用性。
技术框架:QRPO的整体框架包括以下几个主要步骤:1) 使用奖励模型为每个样本生成绝对奖励值。2) 将绝对奖励转化为分位数奖励。3) 使用分位数奖励进行策略优化,目标是最小化策略与参考策略之间的KL散度,同时最大化分位数奖励。4) 利用闭式解进行回归,更新策略参数。
关键创新:QRPO的关键创新在于使用分位数奖励来表示绝对奖励,并利用其解析特性简化了KL正则化强化学习目标的求解。与DPO等方法相比,QRPO可以直接从绝对奖励中学习,无需依赖偏好对或相对信号。此外,QRPO还具有可扩展性,可以通过增加计算量来更精确地估计分位数奖励。
关键设计:QRPO的关键设计包括:1) 分位数奖励的计算方法,例如使用经验分位数或模型预测分位数。2) KL散度的正则化系数,用于平衡策略探索和策略利用。3) 策略网络的结构和训练方法,例如使用Transformer架构和Adam优化器。4) 损失函数的设计,目标是最小化策略与参考策略之间的KL散度,同时最大化分位数奖励。
🖼️ 关键图片

📊 实验亮点
实验结果表明,QRPO在聊天和编码任务上均取得了优异的性能。在AlpacaEval 2和LeetCode等基准测试中,QRPO显著优于DPO、REBEL和SimPO等方法。此外,QRPO还能够有效减少长度偏差,生成更符合人类偏好的文本。
🎯 应用场景
QRPO具有广泛的应用前景,可以应用于各种需要对齐大型语言模型的场景,例如对话系统、代码生成、文本摘要等。通过直接利用绝对奖励,QRPO可以更有效地利用离线数据,提高模型的性能和效率。此外,QRPO还可以用于训练更鲁棒的模型,减少长度偏差等问题。
📄 摘要(原文)
Aligning large language models with pointwise absolute rewards has so far required online, on-policy algorithms such as PPO and GRPO. In contrast, simpler methods that can leverage offline or off-policy data, such as DPO and REBEL, are limited to learning from preference pairs or relative signals. To bridge this gap, we introduce Quantile Reward Policy Optimization (QRPO), which learns from pointwise absolute rewards while preserving the simplicity and offline applicability of DPO-like methods. QRPO uses quantile rewards to enable regression to the closed-form solution of the KL-regularized RL objective. This reward yields an analytically tractable partition function, removing the need for relative signals to cancel this term. Moreover, QRPO scales with increased compute to estimate quantile rewards, opening a new dimension for pre-computation scaling. Empirically, QRPO consistently achieves top performance on chat and coding evaluations--reward model scores, AlpacaEval 2, and LeetCode--compared to DPO, REBEL, and SimPO across diverse datasets and 8B-scale models. Finally, we find that training with robust rewards instead of converting them to preferences induces less length bias.