Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
作者: Zhiwei Zhang, Hui Liu, Xiaomin Li, Zhenwei Dai, Jingying Zeng, Fali Wang, Minhua Lin, Ramraj Chandradevan, Zhen Li, Chen Luo, Xianfeng Tang, Qi He, Suhang Wang
分类: cs.LG, cs.CL
发布日期: 2025-07-10
💡 一句话要点
提出联合训练框架,结合Bradley-Terry和多目标奖励建模,提升奖励模型泛化性和打分能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 人类反馈强化学习 异分布泛化 Bradley-Terry模型 多目标学习
📋 核心要点
- 现有奖励模型在异分布场景下易受奖励黑客攻击,泛化能力不足,难以应对真实世界的复杂情况。
- 提出联合训练框架,结合Bradley-Terry单目标和多目标奖励建模,利用二者的互补优势提升模型性能。
- 实验结果表明,该框架显著提升了奖励模型的鲁棒性和评分性能,使得7B模型超越了70B的基线模型。
📝 摘要(中文)
奖励模型在人类偏好数据上训练,已证明在将大型语言模型(LLM)与人类意图对齐方面非常有效,尤其是在人类反馈强化学习(RLHF)框架下。然而,RLHF仍然容易受到奖励黑客攻击的影响,即策略利用奖励函数的不完善之处,而不是真正学习预期的行为。尽管已经做出了重大努力来缓解奖励黑客攻击,但它们主要集中在同分布(in-distribution)场景中进行评估。本文通过实验表明,现有方法在更具挑战性的异分布(out-of-distribution,OOD)设置中表现不佳。进一步证明,结合细粒度的多属性分数有助于解决这一挑战。然而,高质量数据的有限可用性通常导致多目标奖励函数性能较弱,这可能会对整体性能产生负面影响并成为瓶颈。为了解决这个问题,我们提出了一个统一的奖励建模框架,该框架使用共享嵌入空间联合训练基于Bradley-Terry(BT)的单目标和基于回归的多目标奖励函数。我们在理论上建立了BT损失和回归目标之间的联系,并强调了它们的互补优势。具体而言,回归任务增强了单目标奖励函数在具有挑战性的OOD设置中缓解奖励黑客攻击的能力,而基于BT的训练提高了多目标奖励函数的评分能力,使7B模型能够优于70B基线。大量的实验结果表明,我们的框架显着提高了奖励模型的鲁棒性和评分性能。
🔬 方法详解
问题定义:现有奖励模型在同分布数据上表现良好,但在异分布数据上容易受到奖励黑客攻击,泛化能力不足。同时,多目标奖励模型虽然能提供更细粒度的反馈,但由于数据质量和数量的限制,性能往往较差,难以有效利用。
核心思路:论文的核心思路是结合Bradley-Terry(BT)单目标奖励模型和多目标回归奖励模型的优势,通过联合训练的方式,利用回归任务提升单目标奖励模型的泛化能力,同时利用BT训练提升多目标奖励模型的评分能力。这种互补的方式可以有效缓解奖励黑客攻击,提高模型在异分布场景下的鲁棒性。
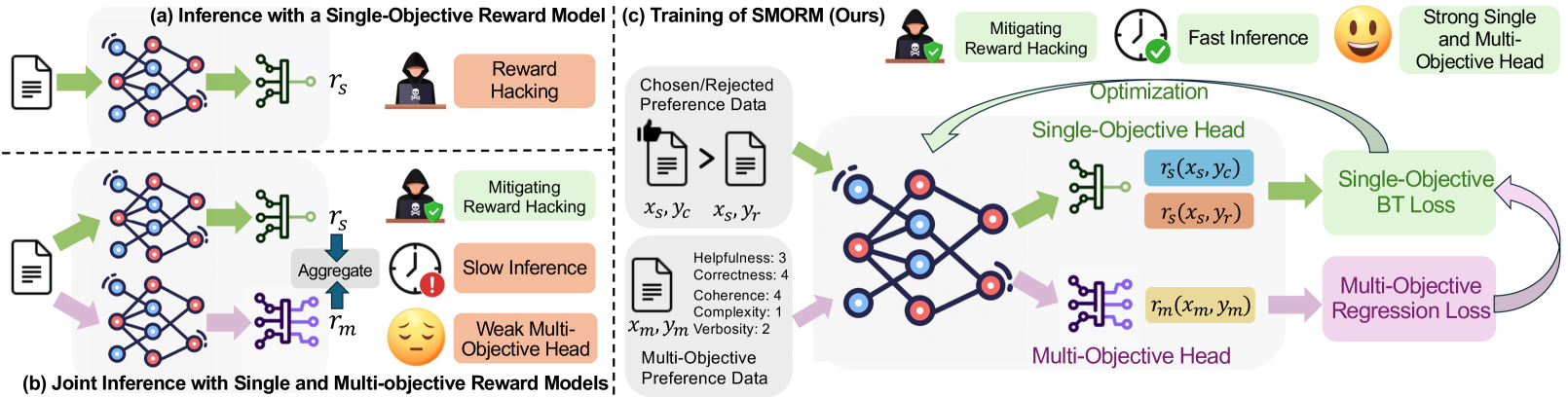
技术框架:该框架包含两个主要部分:Bradley-Terry单目标奖励模型和多目标回归奖励模型。这两个模型共享一个嵌入空间,使得它们可以相互学习和提升。训练过程中,同时优化BT损失和回归损失,从而实现联合训练。整体流程包括数据预处理、模型训练和评估三个阶段。
关键创新:该论文的关键创新在于提出了一个统一的奖励建模框架,将Bradley-Terry单目标奖励模型和多目标回归奖励模型结合起来,并证明了它们之间的互补性。这种联合训练的方式可以有效提升奖励模型的泛化能力和评分性能,缓解奖励黑客攻击。
关键设计:关键设计包括:1) 共享嵌入空间,使得两个模型可以相互学习;2) 联合训练策略,同时优化BT损失和回归损失;3) 针对多目标奖励模型的训练数据增强策略,以缓解数据稀疏问题;4) 针对异分布场景的评估指标,以更全面地评估模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
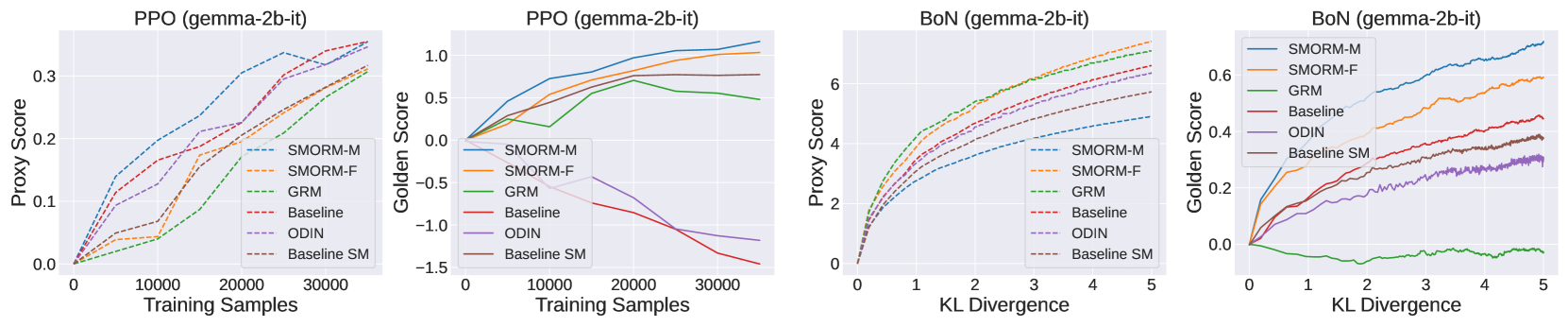
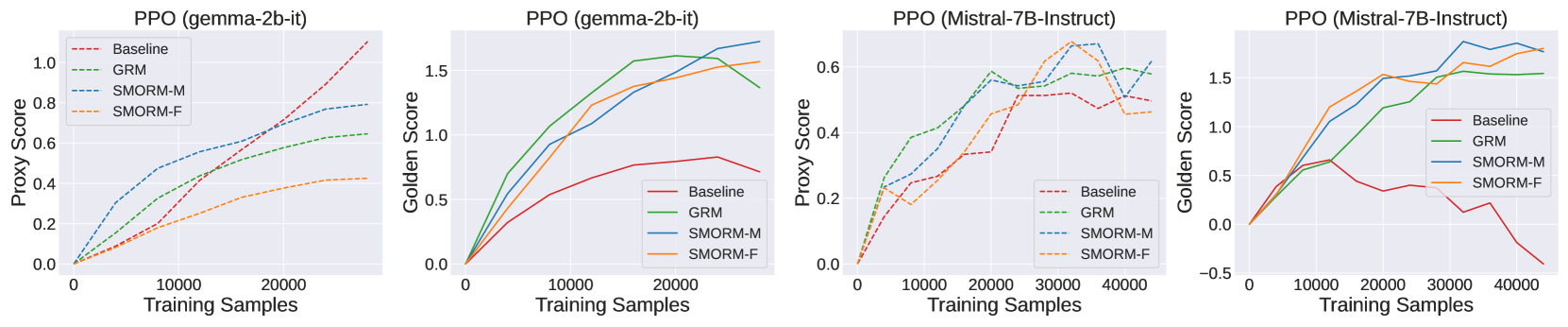
实验结果表明,该框架在异分布场景下显著提升了奖励模型的鲁棒性和评分性能。具体而言,使用该框架训练的7B模型能够超越70B的基线模型,表明该方法在提升模型性能的同时,也降低了对模型规模的需求。此外,实验还验证了Bradley-Terry单目标奖励模型和多目标回归奖励模型之间的互补性。
🎯 应用场景
该研究成果可应用于各种需要人类反馈强化学习的场景,例如对话系统、文本生成、机器人控制等。通过提升奖励模型的鲁棒性和泛化能力,可以更好地对齐AI系统与人类意图,减少奖励黑客攻击的风险,从而提高AI系统的安全性和可靠性。该方法在提升模型性能的同时,也降低了对数据量的需求,具有重要的实际应用价值。
📄 摘要(原文)
Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.