Weighted Multi-Prompt Learning with Description-free Large Language Model Distillation
作者: Sua Lee, Kyubum Shin, Jung Ho Park
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2025-07-09
备注: Published as a conference paper at ICLR 2025
💡 一句话要点
提出无描述多提示学习DeMul,通过LLM知识蒸馏提升VLM在下游任务中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 提示学习 知识蒸馏 大型语言模型 多提示学习 无描述学习 模型优化
📋 核心要点
- 现有方法依赖从LLM提取描述信息来增强VLM提示,但描述信息存在高变异性和低可靠性问题。
- DeMul通过直接将LLM知识蒸馏到提示中,避免了描述提取,使提示包含更丰富的语义并易于优化。
- 实验表明,DeMul在11个识别数据集上表现优异,证明了无描述多提示学习的有效性。
📝 摘要(中文)
近年来,预训练视觉语言模型(VLM)在通过提示学习有效适应下游任务方面展现出巨大潜力,无需额外的标注配对数据集。为了补充VLM中与视觉数据相关的文本信息,一些新方法利用大型语言模型(LLM)来增强提示,从而提高对未见过的多样化数据的鲁棒性。现有方法通常从LLM中提取基于文本的响应(即描述)以融入提示中;然而,这种方法存在高变异性和低可靠性的问题。本文提出了一种新颖的无描述多提示学习(DeMul)方法,该方法消除了提取描述的过程,而是直接将知识从LLM蒸馏到提示中。通过采用无描述方法,提示可以封装更丰富的语义,同时仍然表示为连续向量以进行优化,从而消除了对离散预定义模板的需求。此外,在多提示设置中,我们通过实验证明了提示权重在反映训练期间不同提示重要性方面的潜力。实验结果表明,我们的方法在11个识别数据集上取得了优异的性能。
🔬 方法详解
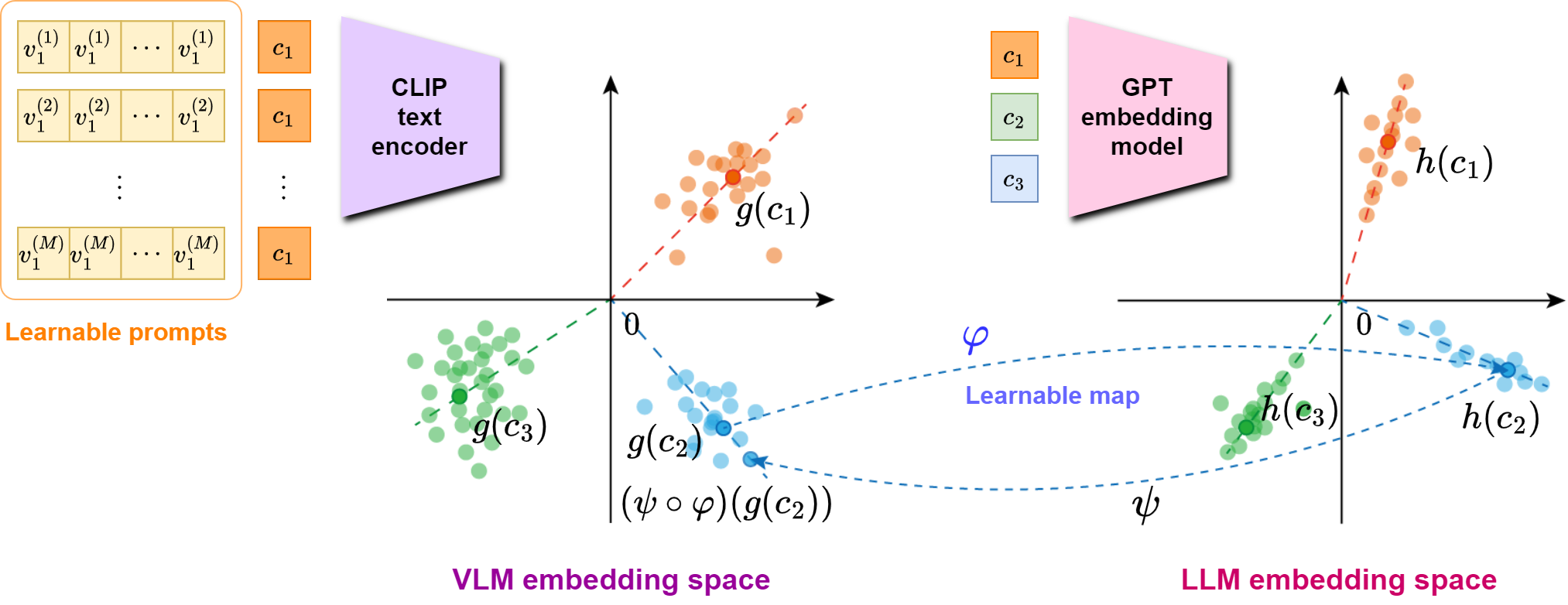
问题定义:现有方法在利用大型语言模型(LLM)增强视觉语言模型(VLM)的提示学习时,通常依赖于从LLM中提取文本描述。然而,这种方法存在固有的问题,即LLM生成的描述具有高度的变异性,并且可能不够可靠,从而影响了VLM在下游任务中的性能。此外,依赖离散的预定义模板限制了提示的表达能力和优化空间。
核心思路:DeMul的核心思路是消除从LLM提取描述信息的步骤,直接将LLM的知识蒸馏到VLM的提示中。通过这种方式,提示可以学习到更丰富、更稳定的语义表示,同时保持连续向量的形式,便于优化。此外,DeMul引入了提示权重机制,允许模型根据不同提示的重要性进行加权,从而进一步提升性能。
技术框架:DeMul的整体框架包括以下几个主要步骤:1) 使用多个不同的提示初始化VLM;2) 利用LLM生成目标任务的知识表示;3) 通过知识蒸馏,将LLM的知识迁移到VLM的多个提示中,优化提示向量;4) 引入提示权重机制,根据不同提示的重要性对它们进行加权;5) 在下游任务上进行微调和评估。
关键创新:DeMul最重要的创新点在于提出了“无描述”的提示学习方法。与现有方法依赖LLM生成文本描述不同,DeMul直接将LLM的知识蒸馏到提示向量中,避免了描述信息带来的噪声和不确定性。此外,DeMul还引入了提示权重机制,允许模型自适应地调整不同提示的重要性,从而进一步提升性能。
关键设计:DeMul的关键设计包括:1) 使用连续向量表示提示,以便进行优化;2) 设计合适的损失函数,用于将LLM的知识蒸馏到VLM的提示中,例如可以使用KL散度损失或对比学习损失;3) 引入可学习的提示权重参数,并使用梯度下降等优化算法进行更新;4) 在多提示学习中,可以采用不同的提示初始化策略,例如随机初始化或基于先验知识进行初始化。
🖼️ 关键图片


📊 实验亮点
DeMul在11个图像识别数据集上进行了广泛的实验,结果表明DeMul显著优于现有的提示学习方法。例如,在某些数据集上,DeMul的性能提升超过了5%。实验还验证了提示权重机制的有效性,表明它可以有效地反映不同提示的重要性,从而进一步提升性能。此外,消融实验也证明了无描述学习策略的优势。
🎯 应用场景
DeMul方法具有广泛的应用前景,可以应用于图像分类、目标检测、图像描述等各种视觉任务。该方法尤其适用于缺乏标注数据的场景,可以通过利用LLM的知识来提升VLM的性能。此外,DeMul还可以应用于跨领域学习,将LLM在其他领域的知识迁移到视觉任务中,从而提高模型的泛化能力。未来,DeMul有望成为一种通用的VLM提示学习方法,为各种视觉任务提供强大的支持。
📄 摘要(原文)
Recent advances in pre-trained Vision Language Models (VLM) have shown promising potential for effectively adapting to downstream tasks through prompt learning, without the need for additional annotated paired datasets. To supplement the text information in VLM trained on correlations with vision data, new approaches leveraging Large Language Models (LLM) in prompts have been proposed, enhancing robustness to unseen and diverse data. Existing methods typically extract text-based responses (i.e., descriptions) from LLM to incorporate into prompts; however, this approach suffers from high variability and low reliability. In this work, we propose Description-free Multi-prompt Learning(DeMul), a novel method that eliminates the process of extracting descriptions and instead directly distills knowledge from LLM into prompts. By adopting a description-free approach, prompts can encapsulate richer semantics while still being represented as continuous vectors for optimization, thereby eliminating the need for discrete pre-defined templates. Additionally, in a multi-prompt setting, we empirically demonstrate the potential of prompt weighting in reflecting the importance of different prompts during training. Experimental results show that our approach achieves superior performance across 11 recognition datasets.