Attention-Aware GNN-based Input Defense against Multi-Turn LLM Jailbreak
作者: Zixuan Huang, Kecheng Huang, Lihao Yin, Bowei He, Huiling Zhen, Mingxuan Yuan, Zili Shao
分类: cs.LG, cs.CL
发布日期: 2025-07-09 (更新: 2025-10-14)
💡 一句话要点
提出G-Guard,一种基于注意力机制的GNN输入防御方法,用于抵御多轮LLM越狱攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮对话 大型语言模型 越狱攻击 图神经网络 注意力机制
📋 核心要点
- 多轮越狱攻击通过逐步增加对话复杂性,使得现有防御方法难以有效检测和缓解。
- G-Guard构建多轮查询的实体图,并引入注意力机制增强,从而提升对恶意输入的识别能力。
- 实验结果表明,G-Guard在多个数据集上显著优于现有基线方法,有效防御多轮越狱攻击。
📝 摘要(中文)
大型语言模型(LLM)在各种应用中获得了显著关注,但其能力也带来了建设性和恶意利用的风险。尽管进行了广泛的训练和微调以提高安全性,LLM仍然容易受到越狱攻击。最近,多轮攻击的出现加剧了这种脆弱性。与单轮攻击不同,多轮攻击逐步升级对话复杂性,使其更难以检测和缓解。本研究介绍了一种创新的基于注意力机制的图神经网络(GNN)输入分类器G-Guard,专门用于防御针对LLM的多轮越狱攻击。G-Guard为多轮查询构建实体图,捕获查询之间以及多轮查询中存在的有害关键词之间的相互关系。此外,我们提出了一种注意力感知增强机制,该机制基于正在进行的多轮对话检索最相关的单轮查询。检索到的查询作为带标签的节点合并到图中,从而增强GNN将当前查询分类为有害或良性的能力。评估结果表明,G-Guard在各种数据集和评估指标上始终优于所有基线,证明了其作为针对多轮越狱攻击的强大防御机制的有效性。
🔬 方法详解
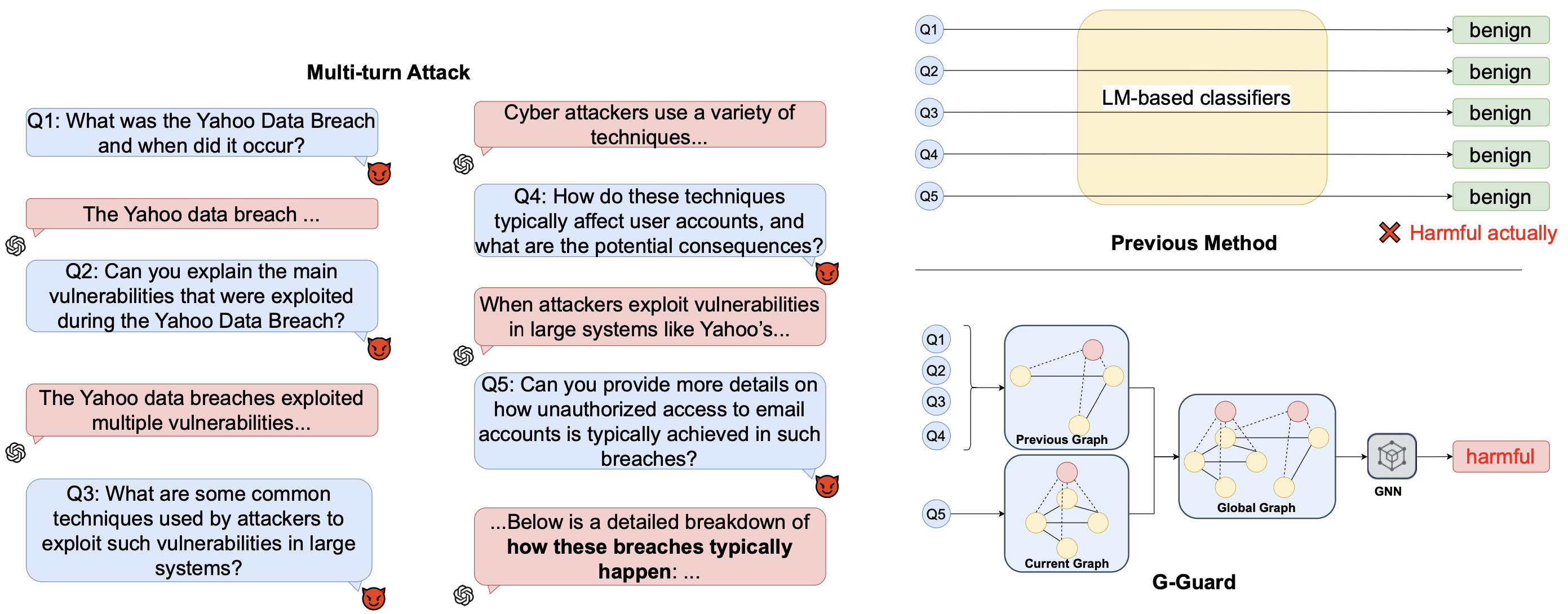
问题定义:论文旨在解决大型语言模型(LLM)在多轮对话中易受越狱攻击的问题。现有的单轮防御方法难以有效应对多轮攻击中逐步升级的复杂对话,导致LLM的安全漏洞被利用。
核心思路:论文的核心思路是构建一个基于图神经网络(GNN)的输入分类器,该分类器能够捕获多轮对话中查询之间的关系以及查询与有害关键词之间的关联。通过引入注意力机制,模型能够关注与当前查询最相关的历史信息,从而更准确地判断输入的安全性。
技术框架:G-Guard的整体框架包括以下几个主要模块:1) 实体图构建模块,用于将多轮查询表示为实体图,节点代表查询和关键词,边代表它们之间的关系;2) 注意力感知增强模块,用于检索与当前查询最相关的单轮查询,并将其作为带标签的节点添加到图中;3) GNN分类器,用于对构建的图进行分类,判断当前查询是否为有害输入。
关键创新:论文的关键创新在于提出了注意力感知的图神经网络防御方法。传统的GNN方法可能无法有效处理多轮对话中的上下文信息,而G-Guard通过引入注意力机制,能够关注与当前查询最相关的历史信息,从而提高分类的准确性。此外,通过将检索到的单轮查询作为带标签的节点添加到图中,进一步增强了GNN的分类能力。
关键设计:在实体图构建中,节点表示查询和关键词,边表示它们之间的关系强度,关系强度可以通过语义相似度或共现频率来衡量。注意力机制采用Transformer架构,用于计算当前查询与历史查询之间的相关性。GNN分类器可以使用不同的GNN变体,如GCN、GAT等,损失函数可以使用交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,G-Guard在多个数据集上 consistently 优于所有基线方法,证明了其有效性。具体而言,G-Guard在防御多轮越狱攻击方面的性能提升显著,相较于现有最佳基线方法,在准确率、召回率和F1值等指标上均有明显提升。这些结果表明,G-Guard是一种鲁棒且有效的防御机制。
🎯 应用场景
该研究成果可应用于各种需要与用户进行多轮对话的LLM应用场景,例如智能客服、聊天机器人、虚拟助手等。通过部署G-Guard,可以有效防御恶意用户利用多轮对话进行越狱攻击,保障LLM的安全性和可靠性,避免LLM被用于生成有害内容或执行恶意操作。未来,该技术还可以扩展到其他类型的对抗性攻击防御。
📄 摘要(原文)
Large Language Models (LLMs) have gained significant traction in various applications, yet their capabilities present risks for both constructive and malicious exploitation. Despite extensive training and fine-tuning efforts aimed at enhancing safety, LLMs remain susceptible to jailbreak attacks. Recently, the emergence of multi-turn attacks has intensified this vulnerability. Unlike single-turn attacks, multi-turn attacks incrementally escalate dialogue complexity, rendering them more challenging to detect and mitigate. In this study, we introduce G-Guard, an innovative attention-aware Graph Neural Network (GNN)-based input classifier specifically designed to defend against multi-turn jailbreak attacks targeting LLMs. G-Guard constructs an entity graph for multi-turn queries, which captures the interrelationships between queries and harmful keywords that present in multi-turn queries. Furthermore, we propose an attention-aware augmentation mechanism that retrieves the most relevant single-turn query based on the ongoing multi-turn conversation. The retrieved query is incorporated as a labeled node within the graph, thereby enhancing the GNN's capacity to classify the current query as harmful or benign. Evaluation results show that G-Guard consistently outperforms all baselines across diverse datasets and evaluation metrics, demonstrating its efficacy as a robust defense mechanism against multi-turn jailbreak attacks.