Assuring the Safety of Reinforcement Learning Components: AMLAS-RL
作者: Calum Corrie Imrie, Ioannis Stefanakos, Sepeedeh Shahbeigi, Richard Hawkins, Simon Burton
分类: cs.LG, cs.AI, cs.RO, cs.SE
发布日期: 2025-07-08
💡 一句话要点
提出AMLAS-RL框架,保障强化学习组件在网络物理系统中的安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习安全 网络物理系统 安全保障 AMLAS方法 风险评估
📋 核心要点
- 现有Safe-RL方法难以在强化学习的整个生命周期中提供系统性的安全保障,存在局限性。
- 论文核心在于将AMLAS方法适配于强化学习,提出了AMLAS-RL框架,用于生成RL系统的安全保障论证。
- 通过轮式车辆避障到达目标的实验,验证了AMLAS-RL框架在实际场景中的可行性。
📝 摘要(中文)
机器学习的快速发展使其越来越多地集成到各个领域的网络物理系统(CPS)中。虽然CPS功能强大,但引入ML组件也带来了重大的安全和保障挑战。在ML技术中,强化学习(RL)特别适合CPS,因为它能够处理复杂的动态环境,在这些环境中,系统和环境之间交互的显式模型不可用或难以构建。然而,在安全关键型应用中,这种学习过程不仅必须有效,而且必须具有可证明的安全性。Safe-RL方法旨在通过在学习过程中加入安全约束来解决这个问题,但它们在RL生命周期中提供系统性保障方面存在不足。AMLAS方法为保证监督学习组件的安全性提供了结构化的指导,但它并不直接适用于RL带来的独特挑战。在本文中,我们调整AMLAS,通过一个迭代过程,为RL系统的保障论证生成框架;AMLAS-RL。我们使用一个轮式车辆的运行示例来演示AMLAS-RL,该车辆的任务是在没有碰撞的情况下到达目标。
🔬 方法详解
问题定义:论文旨在解决将强化学习(RL)应用于网络物理系统(CPS)时面临的安全保障问题。现有的Safe-RL方法虽然在学习过程中考虑了安全约束,但缺乏对整个RL生命周期的系统性保障,难以满足安全关键应用的需求。因此,需要一种方法能够系统地论证RL组件的安全性。
核心思路:论文的核心思路是将已有的AMLAS方法(用于监督学习组件的安全保障)进行适配和扩展,使其能够应用于RL组件。通过迭代的过程,生成RL系统的安全保障论证,从而提高RL在安全关键系统中的可信度。
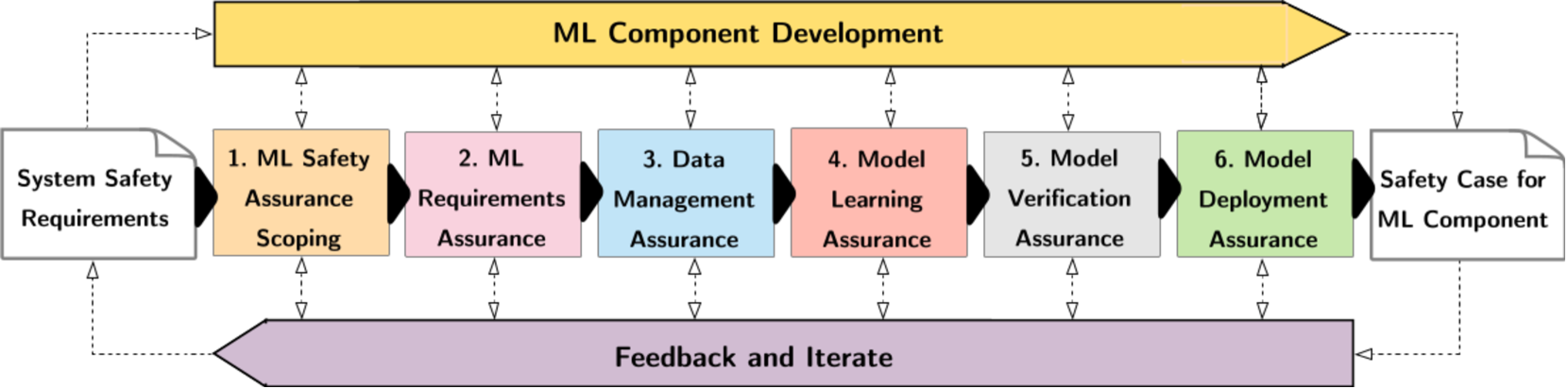
技术框架:AMLAS-RL框架是一个迭代过程,它借鉴了AMLAS的结构化指导,并针对RL的特点进行了调整。具体流程包括:1) 定义系统目标和安全需求;2) 识别RL组件的潜在风险;3) 构建安全保障论证;4) 验证论证的有效性;5) 根据验证结果迭代改进论证和系统设计。该框架强调对RL生命周期的全面考虑,包括训练、验证和部署阶段。
关键创新:该论文的关键创新在于将AMLAS方法成功地应用于RL领域,弥补了现有Safe-RL方法在系统性安全保障方面的不足。AMLAS-RL提供了一种结构化的方法,用于生成RL系统的安全保障论证,从而提高了RL在安全关键应用中的可信度。与现有方法相比,AMLAS-RL更加注重对整个RL生命周期的考虑,并强调通过迭代的方式不断改进安全保障论证。
关键设计:AMLAS-RL框架的关键设计在于其迭代的特性,允许根据验证结果不断改进安全保障论证和系统设计。此外,该框架还强调对RL组件的风险进行全面评估,并针对不同的风险制定相应的安全保障措施。论文使用轮式车辆避障到达目标的实验来演示AMLAS-RL框架的应用,并展示了如何使用该框架来识别和缓解RL组件的潜在风险。具体的参数设置、损失函数、网络结构等技术细节取决于具体的RL算法和应用场景,论文中未详细描述。
🖼️ 关键图片

📊 实验亮点
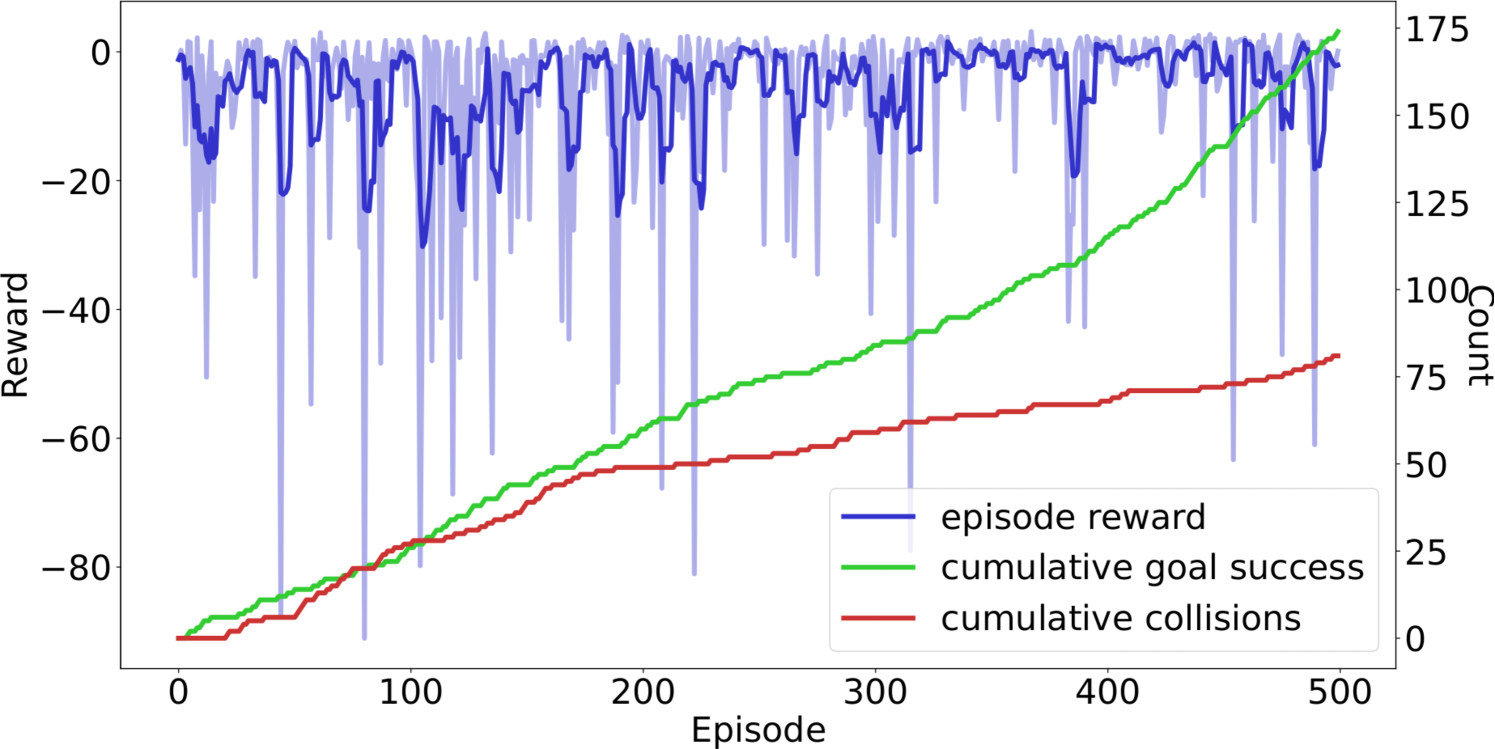
论文通过一个轮式车辆避障到达目标的实验,验证了AMLAS-RL框架的可行性。实验结果表明,使用AMLAS-RL框架可以有效地识别和缓解RL组件的潜在风险,提高系统的安全性。虽然论文没有提供具体的性能数据和对比基线,但该实验为AMLAS-RL框架在实际应用中的有效性提供了初步的证据。
🎯 应用场景
该研究成果可应用于各种安全关键型网络物理系统,例如自动驾驶汽车、无人机、机器人等。通过AMLAS-RL框架,可以提高这些系统中RL组件的安全性和可靠性,降低事故发生的风险。未来,该框架有望成为RL在安全关键领域广泛应用的重要保障。
📄 摘要(原文)
The rapid advancement of machine learning (ML) has led to its increasing integration into cyber-physical systems (CPS) across diverse domains. While CPS offer powerful capabilities, incorporating ML components introduces significant safety and assurance challenges. Among ML techniques, reinforcement learning (RL) is particularly suited for CPS due to its capacity to handle complex, dynamic environments where explicit models of interaction between system and environment are unavailable or difficult to construct. However, in safety-critical applications, this learning process must not only be effective but demonstrably safe. Safe-RL methods aim to address this by incorporating safety constraints during learning, yet they fall short in providing systematic assurance across the RL lifecycle. The AMLAS methodology offers structured guidance for assuring the safety of supervised learning components, but it does not directly apply to the unique challenges posed by RL. In this paper, we adapt AMLAS to provide a framework for generating assurance arguments for an RL-enabled system through an iterative process; AMLAS-RL. We demonstrate AMLAS-RL using a running example of a wheeled vehicle tasked with reaching a target goal without collision.