Growing Transformers: Modular Composition and Layer-wise Expansion on a Frozen Substrate
作者: A. Bochkov
分类: cs.LG, cs.CL
发布日期: 2025-07-08 (更新: 2025-11-04)
备注: Controlled Comparative Study added
💡 一句话要点
提出一种基于冻结底层和模块化扩展的Transformer增长方法,实现高效可扩展的LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 Transformer 增量学习 模块化扩展 低秩适应 层冻结 涌现语义
📋 核心要点
- 现有LLM扩展方法依赖于资源密集的整体训练,缺乏灵活性和可扩展性。
- 该论文提出一种建设性的LLM增长方法,通过冻结底层并逐层扩展Transformer,实现高效训练。
- 实验表明,该方法在SQuAD等任务上表现出色,与同等规模的整体训练模型性能相当。
📝 摘要(中文)
大规模语言模型(LLM)扩展的主流范式是整体式的端到端训练,这种方法资源密集且缺乏灵活性。本文探索了一种替代的、建设性的扩展范式,该范式基于Transformer中冻结的、非语义输入嵌入所产生的涌现语义原理。我们认为,由于高层含义是Transformer深层网络的组合属性,而非其输入向量,因此嵌入层和训练过的底层可以作为固定的基础。这使得反向传播能够专注于新添加的组件,从而使增量增长成为可能。我们通过一种分层建设性方法来实现这一点,该方法结合了早期阶段的严格层冻结和通过低秩适应(LoRA)对整个模型堆栈进行高效的整体微调,随着复杂性的增加。这种方法不仅展示了稳定的收敛性,还揭示了模型深度与复杂推理能力(例如SQuAD所需的能力)之间的直接相关性,而这些能力在较浅的模型中是不存在的。在一项受控研究中,我们建设性增长的模型在性能上与相同大小的整体训练基线相媲美,验证了该方法的效率和有效性。我们的发现表明,可以从整体优化转向更具生物学或建设性的AI开发模型。这为更高效的资源扩展、持续学习以及构建强大AI系统的更模块化方法开辟了道路。我们发布所有代码和模型,以促进进一步研究。
🔬 方法详解
问题定义:现有大规模语言模型(LLM)的训练通常采用端到端的方式,需要大量的计算资源和时间。这种整体训练方法缺乏灵活性,难以适应新的任务或数据,并且难以进行模块化的扩展和维护。因此,如何高效且灵活地扩展LLM的规模,同时保持其性能,是一个重要的研究问题。
核心思路:该论文的核心思路是利用Transformer的涌现语义特性,即高层语义是由深层网络层组合产生的,而非直接来源于输入向量。因此,可以冻结Transformer的底层(包括嵌入层和部分浅层),将其作为固定的语义基础,然后在此基础上逐层添加新的Transformer层,并仅对新添加的层进行训练。这种方法可以显著减少训练所需的计算资源,并允许对模型进行模块化的扩展。
技术框架:该方法主要包含以下几个阶段:1) 初始化:使用预训练的Transformer模型作为基础,冻结其嵌入层和部分浅层。2) 逐层扩展:每次添加一层或多层新的Transformer层到冻结的底层之上。3) 训练:仅对新添加的层进行训练,可以使用传统的反向传播算法或更高效的参数高效微调方法,如LoRA。4) 整体微调:随着模型复杂度的增加,使用LoRA对整个模型进行微调,以进一步提升性能。
关键创新:该论文的关键创新在于提出了一种建设性的LLM增长方法,通过冻结底层和逐层扩展Transformer,实现了高效且灵活的模型扩展。与传统的整体训练方法相比,该方法可以显著减少训练所需的计算资源,并允许对模型进行模块化的扩展和维护。此外,该论文还发现模型深度与复杂推理能力之间存在直接相关性。
关键设计:在具体实现上,该论文采用了以下关键设计:1) 层冻结策略:在早期阶段,严格冻结底层,以确保语义基础的稳定性。2) LoRA微调:使用LoRA对新添加的层进行训练,以及对整个模型进行微调,以提高训练效率和模型性能。3) 模型深度控制:通过控制模型深度,研究了模型深度与复杂推理能力之间的关系。4) SQuAD评估:使用SQuAD数据集评估了模型的推理能力。
🖼️ 关键图片
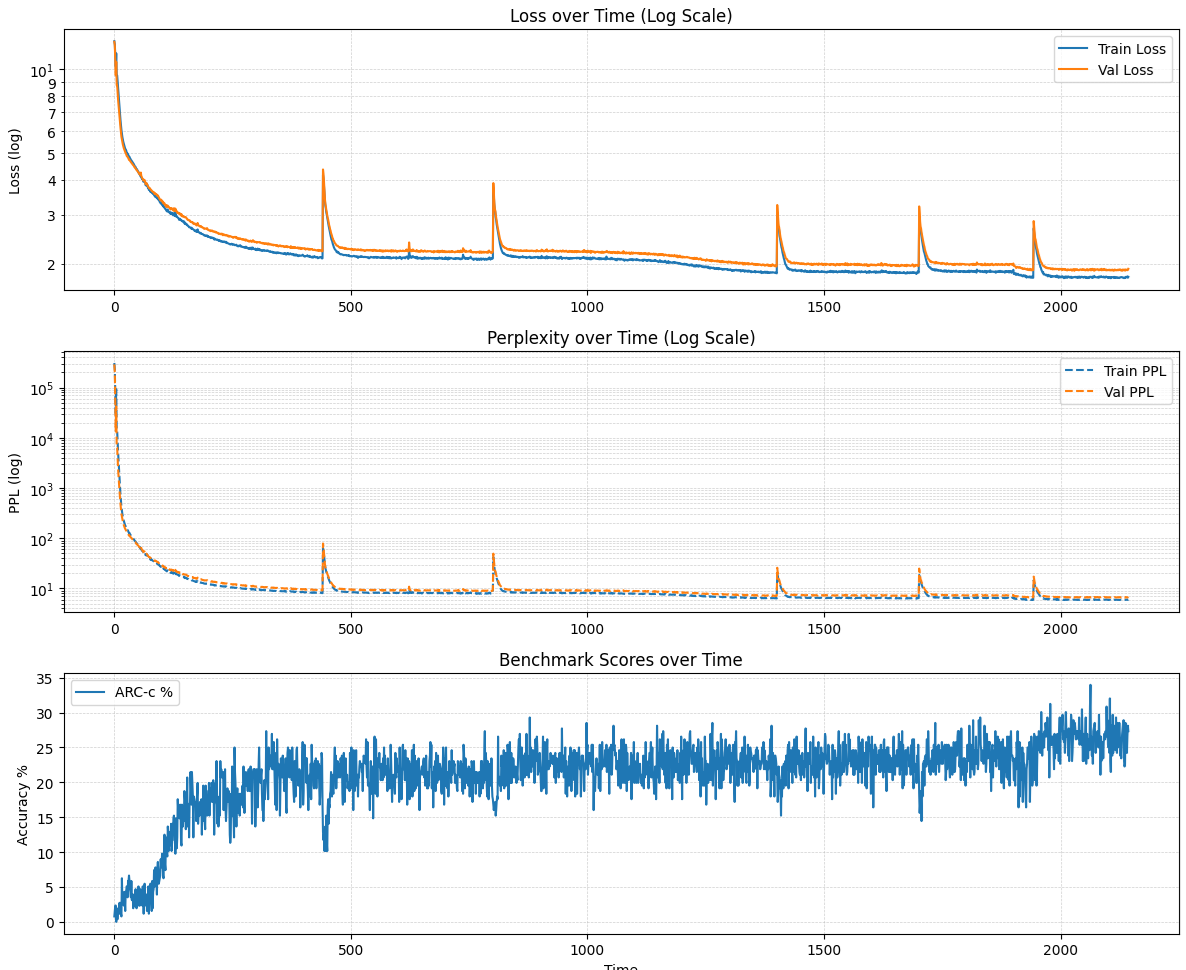
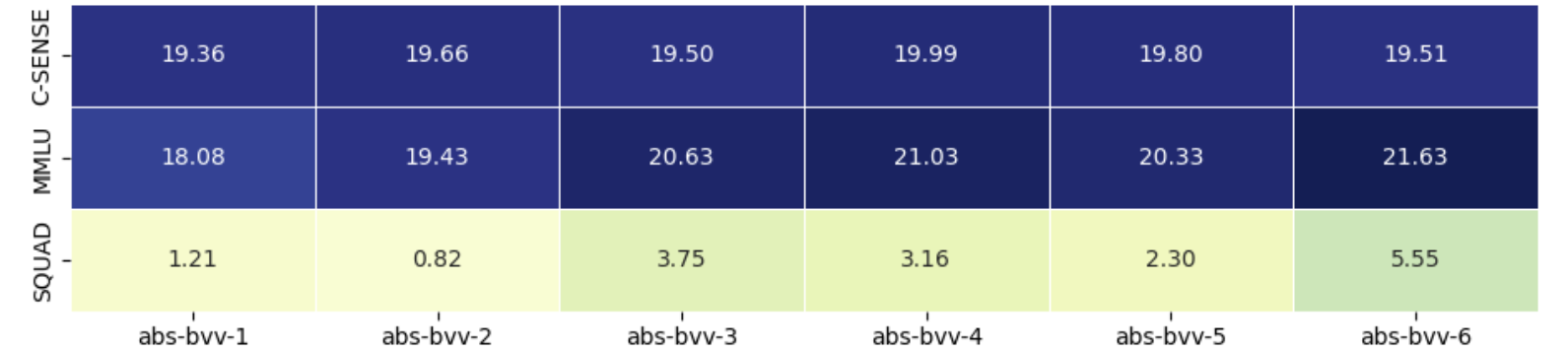
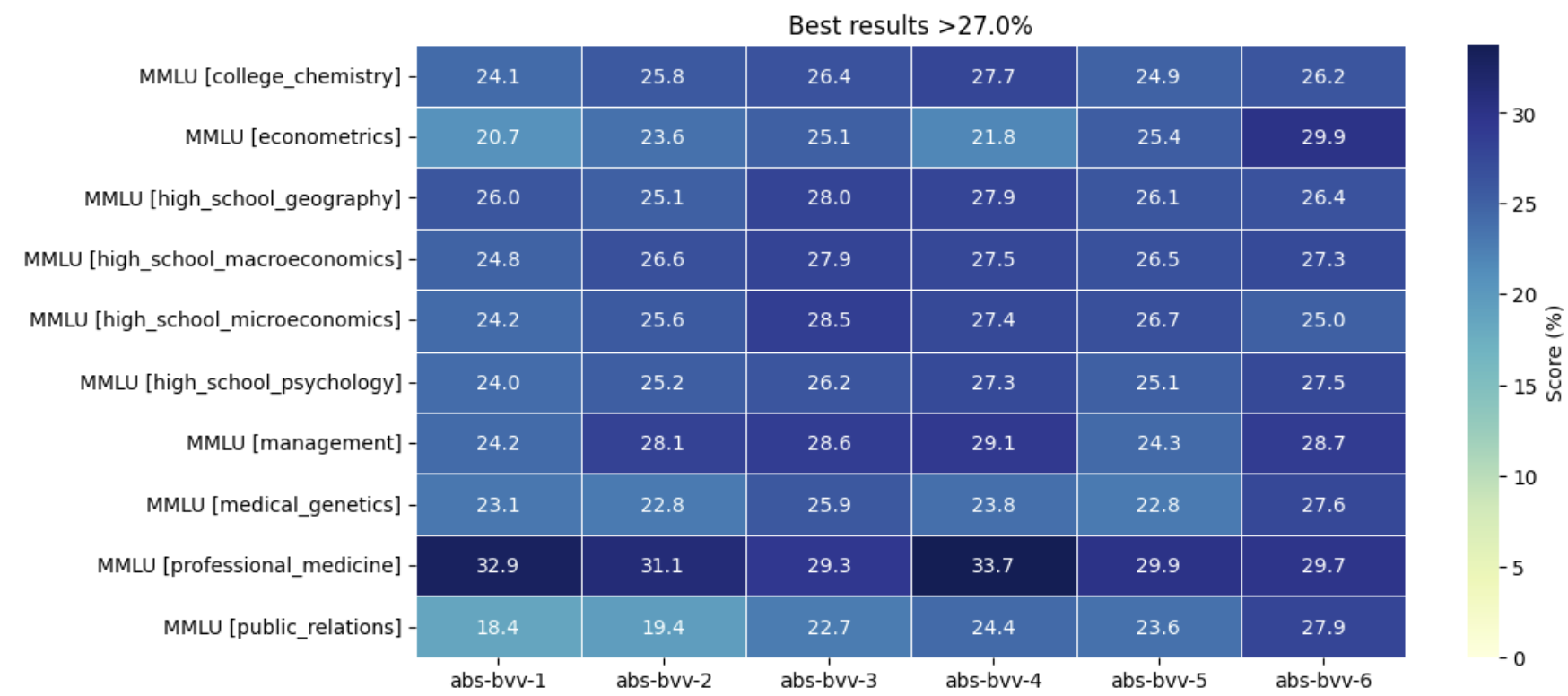
📊 实验亮点
该论文通过实验验证了所提出的建设性增长方法的有效性。实验结果表明,通过该方法训练的模型在SQuAD等任务上表现出色,与同等规模的整体训练模型性能相当。此外,实验还揭示了模型深度与复杂推理能力之间的直接相关性,表明更深的模型能够更好地处理复杂的推理任务。
🎯 应用场景
该研究成果可应用于多种场景,例如:1) 资源受限环境下的LLM训练和部署;2) 持续学习,通过增量式地添加新层来适应新的任务和数据;3) 模块化AI系统构建,将不同的Transformer模块组合起来,构建更复杂的AI系统。该方法有望降低LLM的训练成本,加速LLM的应用普及,并促进更灵活和可扩展的AI系统设计。
📄 摘要(原文)
The prevailing paradigm for scaling large language models (LLMs) involves monolithic, end-to-end training, a resource-intensive process that lacks flexibility. This paper explores an alternative, constructive scaling paradigm, enabled by the principle of emergent semantics in Transformers with frozen, non-semantic input embeddings. We posit that because high-level meaning is a compositional property of a Transformer's deep layers, not its input vectors, the embedding layer and trained lower layers can serve as a fixed foundation. This liberates backpropagation to focus solely on newly added components, making incremental growth viable. We operationalize this with a layer-wise constructive methodology that combines strict layer freezing in early stages with efficient, holistic fine-tuning of the entire model stack via low-rank adaptation (LoRA) as complexity increases. This method not only demonstrates stable convergence but also reveals a direct correlation between model depth and the emergence of complex reasoning abilities, such as those required for SQuAD, which are absent in shallower models. In a controlled study, our constructively grown model rivals the performance of a monolithically trained baseline of the same size, validating the efficiency and efficacy of the approach. Our findings suggest a path towards a paradigm shift from monolithic optimization towards a more biological or constructive model of AI development. This opens a path for more resource-efficient scaling, continual learning, and a more modular approach to building powerful AI systems. We release all code and models to facilitate further research.