Fine-tuning on simulated data outperforms prompting for agent tone of voice
作者: Ingo Marquardt, Philippe Brule
分类: cs.LG
发布日期: 2025-07-07
备注: 22 pages, 5 figures, 6 tables
💡 一句话要点
通过在模拟数据上微调,可显著提升Agent语音交互的自然对话风格,优于Prompting方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型微调 对话风格 语音交互 模拟数据 低秩适应 量化训练 自然语言处理
📋 核心要点
- 现有方法依赖复杂Prompting,难以保证语言模型在语音交互中风格一致性和自然度,存在指令遵循限制和上下文偏差。
- 该研究提出在模拟数据上微调小型开源语言模型,以实现特定的对话风格,避免复杂Prompting带来的问题。
- 实验结果表明,微调方法在少量数据下即可有效提升对话风格,且不影响内容质量,优于Prompting方法。
📝 摘要(中文)
在面向客户的语音应用中部署语言模型(LMs)需要流畅的对话能力和对特定风格指南的遵守。由于指令遵循限制和上下文偏差等问题,使用复杂的系统提示来实现这一点具有挑战性。本研究调查了微调与系统提示在使LMs与特定行为目标(以适合语音交互的自然、对话语气进行响应)对齐方面的有效性。我们使用低秩适应(LoRA)在从维基百科衍生的合成数据集上微调了一个小型开源模型(Llama3.2-1B-Instruct)。此外,我们还微调了两个闭源模型(gpt-4o-mini, gpt-4.1-mini)。结果表明,即使仅使用100个数据样本进行训练,微调也优于系统提示,实现了高比例的对话式响应。语义相似性分析证实,微调不会降低内容质量。有趣的是,使用8位整数量化进行微调比使用bfloat16精度更快地收敛到目标风格,这可能是由于隐式正则化效应。我们得出结论,在模拟数据上微调小型开源LMs是一种高效且数据高效的方法,可以灌输特定的风格行为,为需要细微响应风格的实际应用提供了一种优于复杂系统提示的替代方案。
🔬 方法详解
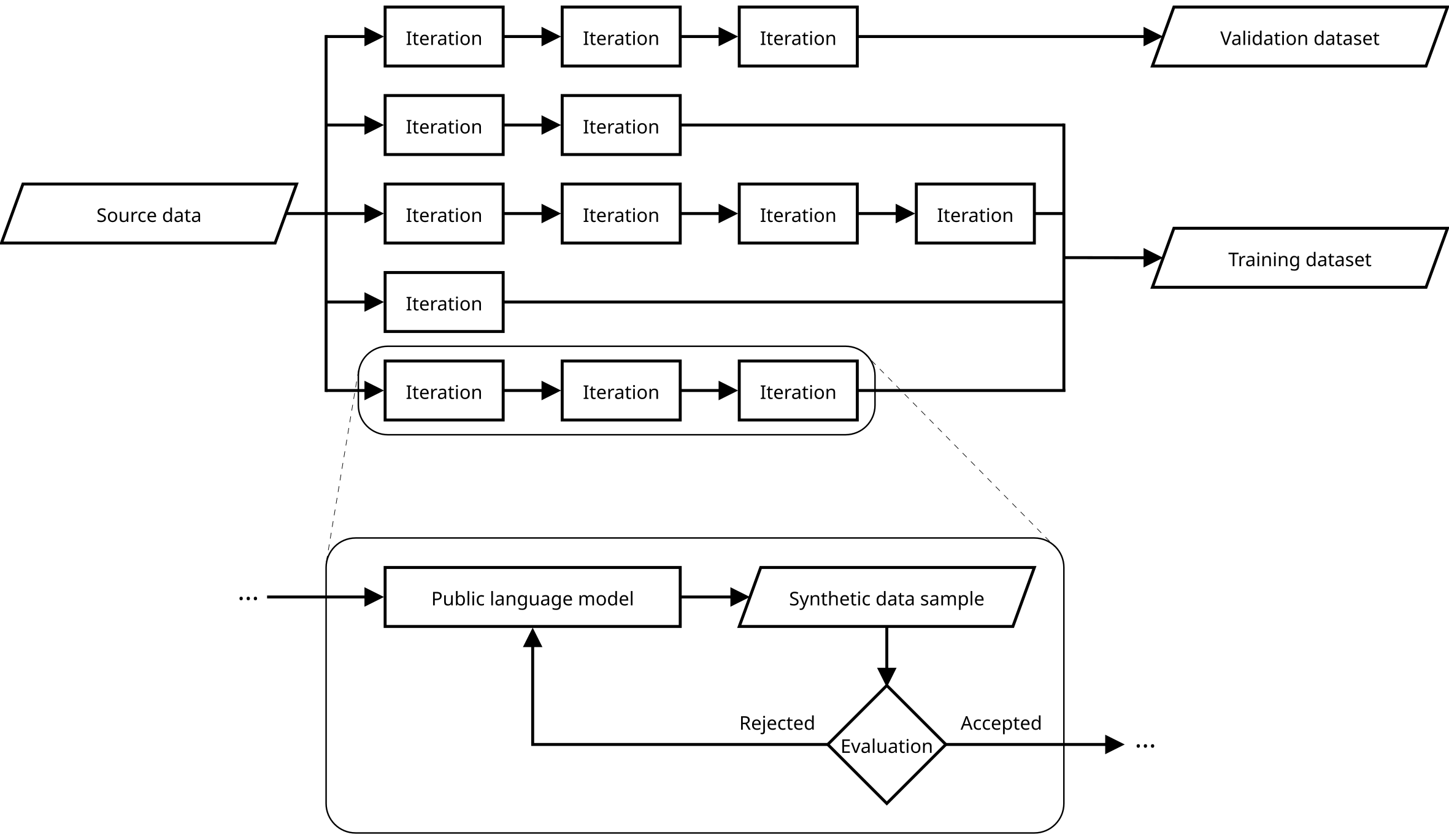
问题定义:论文旨在解决在客户语音交互场景下,如何让语言模型生成自然、流畅且符合特定风格的对话。现有方法主要依赖复杂的系统Prompting,但这种方法容易受到指令遵循限制和上下文偏差的影响,难以保证风格的一致性和可控性。此外,Prompting方法通常需要大量的实验和调整,效率较低。
核心思路:论文的核心思路是通过在模拟数据上对小型开源语言模型进行微调,使其学习到目标对话风格。这种方法避免了复杂Prompting带来的问题,并且可以通过控制训练数据来精确地塑造模型的行为。微调后的模型可以直接用于语音交互场景,无需额外的Prompting。
技术框架:整体框架包括以下几个步骤:1) 构建模拟数据集:从维基百科等来源生成包含目标对话风格的文本数据。2) 选择预训练语言模型:选择小型开源语言模型作为基础模型,例如Llama3.2-1B-Instruct。3) 微调模型:使用低秩适应(LoRA)等技术在模拟数据集上对预训练模型进行微调。4) 评估模型:使用指标(如对话性响应比例和语义相似性)评估微调后模型的性能。
关键创新:该研究的关键创新在于证明了在模拟数据上微调小型开源语言模型是一种高效且数据高效的方法,可以灌输特定的风格行为。与传统的Prompting方法相比,微调方法可以更好地控制模型的行为,并且需要的训练数据更少。此外,研究还发现使用8位整数量化进行微调可以加速收敛,这可能是由于隐式正则化效应。
关键设计:在微调过程中,使用了低秩适应(LoRA)技术来减少训练参数,提高训练效率。研究人员还尝试了不同的量化方法(如8位整数量化和bfloat16精度),并发现8位整数量化可以加速收敛。损失函数未知,但通常会使用交叉熵损失函数来训练语言模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在仅使用100个数据样本进行训练的情况下,微调方法即可显著提升模型的对话风格,优于传统的Prompting方法。语义相似性分析证实,微调不会降低内容质量。此外,研究还发现使用8位整数量化进行微调比使用bfloat16精度更快地收敛到目标风格,这为模型训练提供了新的思路。
🎯 应用场景
该研究成果可广泛应用于智能客服、虚拟助手、语音聊天机器人等领域。通过微调,可以使这些应用具备更自然、更人性化的对话风格,提升用户体验。此外,该方法还可以用于定制特定行业的对话风格,例如医疗、金融等,从而满足不同场景的需求。未来,该研究可以进一步探索如何利用更少的模拟数据来训练出更强大的对话模型。
📄 摘要(原文)
Deploying language models (LMs) in customer-facing speech applications requires conversational fluency and adherence to specific stylistic guidelines. This can be challenging to achieve reliably using complex system prompts due to issues like instruction following limitations and in-context bias. This study investigates the effectiveness of fine-tuning versus system prompting for aligning LMs with a specific behavioral target: responding in a natural, conversational tone suitable for voice interactions. We fine-tuned a small, open-weights model (
Llama3.2-1B-Instruct) using Low-Rank Adaptation (LoRA) on a synthetically generated dataset derived from Wikipedia. Additionally, we fine-tuned two closed-source models (gpt-4o-mini,gpt-4.1-mini). Our results demonstrate that fine-tuning outperformed system prompting, achieving a high percentage of conversational responses, even when trained on only 100 data samples. Semantic similarity analysis confirmed that fine-tuning did not degrade content quality. Interestingly, fine-tuning with 8-bit integer quantization converged faster towards the target style than using bfloat16 precision, potentially due to implicit regularization effects. We conclude that fine-tuning small, open-weights LMs on simulated data is a highly effective and data-efficient method for instilling specific stylistic behaviors, offering a preferable alternative to complex system prompting for practical applications requiring nuanced response styles.