Beyond Training-time Poisoning: Component-level and Post-training Backdoors in Deep Reinforcement Learning
作者: Sanyam Vyas, Alberto Caron, Chris Hicks, Pete Burnap, Vasilios Mavroudis
分类: cs.LG, cs.AI, cs.CR
发布日期: 2025-07-07
💡 一句话要点
揭示深度强化学习供应链漏洞,提出组件级和后训练的后门攻击
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 后门攻击 安全漏洞 对抗攻击 模型安全
📋 核心要点
- 现有DRL后门攻击研究主要集中在训练阶段,需要较高的权限访问训练数据和流程,现实场景中难以实现。
- 论文提出TrojanentRL和InfrectroRL两种新型后门攻击,分别针对组件级漏洞和后训练阶段,降低了攻击者的权限要求。
- 实验证明,提出的攻击方法在Atari游戏中能达到与现有训练时攻击相当的性能,并且能有效绕过现有的防御机制。
📝 摘要(中文)
深度强化学习(DRL)系统越来越多地应用于安全关键型应用中,但其安全性仍未得到充分探索。本文研究了后门攻击,这种攻击会植入隐藏的触发器,只有当特定输入出现在观察空间中时才会导致恶意行为。现有的DRL后门研究仅关注训练时攻击,这需要不切实际地访问训练流程。相比之下,我们揭示了DRL供应链中的关键漏洞,后门可以在其中嵌入,且对抗权限显著降低。我们提出了两种新的攻击方法:(1) TrojanentRL,它利用组件级缺陷植入持久性后门,该后门可以在完全模型重新训练后幸存;(2) InfrectroRL,一种后训练后门攻击,不需要访问训练、验证或测试数据。在六个Atari环境中的经验和分析评估表明,我们的攻击在更严格的对抗约束下,可以与最先进的训练时后门攻击相媲美。我们还证明InfrectroRL进一步逃避了两种领先的DRL后门防御。这些发现挑战了当前的研究重点,并强调了对强大防御的迫切需求。
🔬 方法详解
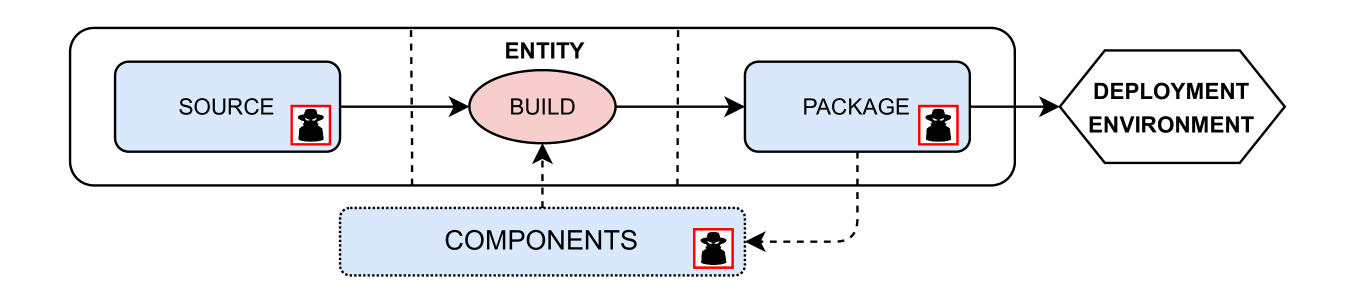
问题定义:现有的深度强化学习后门攻击主要集中在训练阶段,攻击者需要访问甚至控制训练数据和训练过程。这种假设在实际应用中往往难以满足,因为攻击者可能无法直接干预模型的训练流程。因此,如何降低攻击者权限要求,在更现实的场景下实现有效的后门攻击,是本文要解决的核心问题。现有方法的痛点在于对攻击者权限要求过高,缺乏对DRL供应链其他环节漏洞的关注。
核心思路:本文的核心思路是探索DRL供应链中除训练阶段以外的潜在漏洞,并设计相应的后门攻击方法。具体而言,论文提出了两种攻击方法:TrojanentRL利用模型组件中的漏洞,植入可以在模型重新训练后仍然存在的后门;InfrectroRL则直接在训练完成的模型上进行后门植入,无需访问任何训练数据。通过这种方式,大大降低了攻击者的权限要求,使其能够在更广泛的场景下发起攻击。
技术框架:论文提出了两种攻击方法,分别针对不同的攻击场景: 1. TrojanentRL:该攻击利用DRL模型组件(如特定层或模块)中的漏洞,通过修改这些组件的参数来植入后门。由于这些组件在模型重新训练时可能被保留或复用,因此后门可以持续存在。 2. InfrectroRL:该攻击直接在训练完成的模型上进行后门植入,无需访问任何训练数据。攻击者通过分析模型的结构和参数,找到合适的注入点,并修改相应的权重,使得模型在特定触发条件下产生恶意行为。
关键创新:本文最重要的技术创新在于提出了两种全新的DRL后门攻击方法,这两种方法都显著降低了攻击者的权限要求,使其能够在更现实的场景下发起攻击。与现有的训练时攻击相比,TrojanentRL和InfrectroRL分别针对组件级漏洞和后训练阶段,扩展了DRL后门攻击的研究范围,并揭示了DRL供应链中潜在的安全风险。
关键设计: 1. TrojanentRL:关键在于选择合适的模型组件进行攻击,并设计能够持久存在的后门。这可能涉及到对特定层的权重进行微调,或者在模型中插入额外的恶意模块。 2. InfrectroRL:关键在于找到合适的注入点,并设计能够有效触发恶意行为的触发器。这可能涉及到对模型的激活函数进行修改,或者在模型的输入层添加特定的噪声模式。此外,论文还研究了如何使InfrectroRL攻击能够绕过现有的后门防御机制,例如通过使用对抗样本来隐藏触发器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TrojanentRL和InfrectroRL两种攻击方法在六个Atari游戏中均能达到与现有训练时攻击相当的性能,同时显著降低了攻击者的权限要求。更重要的是,InfrectroRL攻击能够成功绕过两种领先的DRL后门防御机制,表明现有防御方法的局限性,并突出了开发更有效防御措施的必要性。
🎯 应用场景
该研究揭示了深度强化学习系统在实际应用中面临的严重安全威胁,尤其是在安全关键领域,如自动驾驶、金融交易和智能电网等。研究成果有助于提高对DRL系统安全性的认识,并促进开发更强大的防御机制,从而保障这些系统在实际应用中的可靠性和安全性。未来的研究可以进一步探索更隐蔽、更复杂的后门攻击方法,并开发相应的检测和防御技术。
📄 摘要(原文)
Deep Reinforcement Learning (DRL) systems are increasingly used in safety-critical applications, yet their security remains severely underexplored. This work investigates backdoor attacks, which implant hidden triggers that cause malicious actions only when specific inputs appear in the observation space. Existing DRL backdoor research focuses solely on training-time attacks requiring unrealistic access to the training pipeline. In contrast, we reveal critical vulnerabilities across the DRL supply chain where backdoors can be embedded with significantly reduced adversarial privileges. We introduce two novel attacks: (1) TrojanentRL, which exploits component-level flaws to implant a persistent backdoor that survives full model retraining; and (2) InfrectroRL, a post-training backdoor attack which requires no access to training, validation, nor test data. Empirical and analytical evaluations across six Atari environments show our attacks rival state-of-the-art training-time backdoor attacks while operating under much stricter adversarial constraints. We also demonstrate that InfrectroRL further evades two leading DRL backdoor defenses. These findings challenge the current research focus and highlight the urgent need for robust defenses.