any4: Learned 4-bit Numeric Representation for LLMs
作者: Mostafa Elhoushi, Jeff Johnson
分类: cs.LG, cs.AI
发布日期: 2025-07-07
备注: ICML 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出any4:一种面向LLM的可学习4比特数值表示方法,无需预处理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 大型语言模型 低精度计算 模型压缩 GPU加速
📋 核心要点
- 现有4比特量化方法(int4, fp4, nf4等)在LLM压缩时精度受限,且部分方法需要复杂的预处理步骤。
- any4通过学习得到优化的4比特数值表示,无需预处理权重或激活,从而提升量化精度。
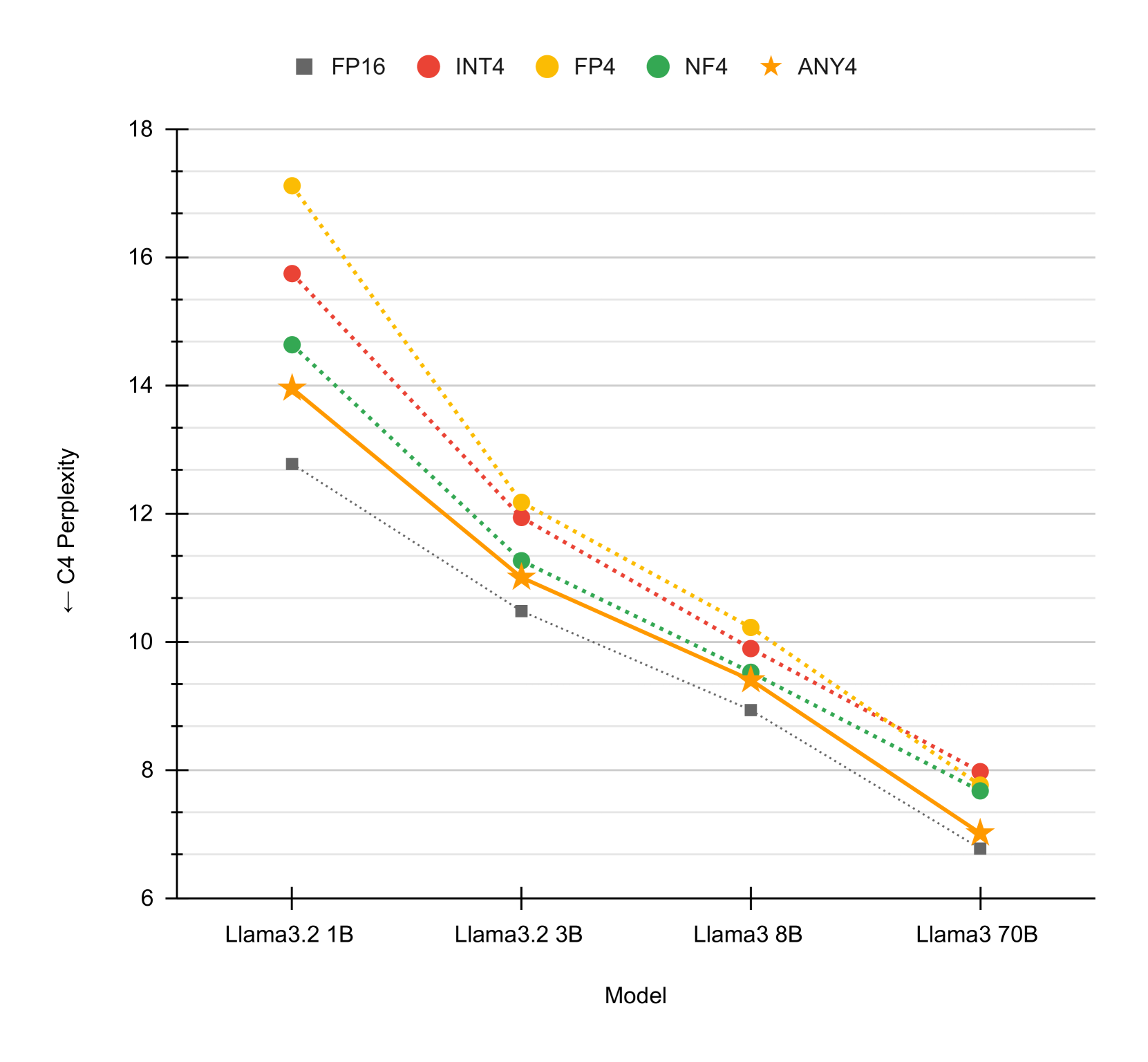
- 实验表明,any4在多种LLM上优于其他4比特量化方法,且仅需少量样本即可完成校准。
📝 摘要(中文)
本文提出any4,一种用于大型语言模型(LLMs)的可学习4比特权重量化解决方案,它提供任意数值表示,无需预处理权重或激活。在各种模型大小、生成任务和模型家族(Llama 2、Llama 3、Mistral和Mixtral)上的评估表明,any4相比其他相关的4比特数值表示类型(int4、fp4和nf4)具有更高的准确性。any4虽然不需要预处理权重或激活,但其性能与需要此类预处理的正交技术(例如,AWQ和GPTQ)相比也具有竞争力。我们还实验了any3和any2,并展示了在更低比特数下的竞争力。此外,我们表明可以使用单个精心策划的多样化样本进行校准,而不是像大多数量化方法那样使用来自数据集的数百个样本。我们还开源了tinygemm,这是一个针对LLM的延迟优化GPU矩阵乘法库,它使用GPU高效查找表策略实现了any4以及其他常见的量化方法。我们的代码已在https://github.com/facebookresearch/any4开源。
🔬 方法详解
问题定义:现有的大型语言模型量化方法,特别是4比特量化,在保持模型性能的同时压缩模型大小方面面临挑战。传统的int4、fp4和nf4等方法在精度上存在局限性,并且一些先进的量化技术,如AWQ和GPTQ,需要对权重或激活进行预处理,增加了计算复杂度和部署难度。
核心思路:any4的核心思路是通过学习得到一个优化的4比特数值表示,使得量化后的模型能够更好地保留原始模型的性能。与预定义的数值表示(如int4、fp4等)不同,any4允许模型学习最适合其权重的数值表示,从而提高量化精度。这种方法旨在消除对权重或激活进行预处理的需求,简化量化流程。
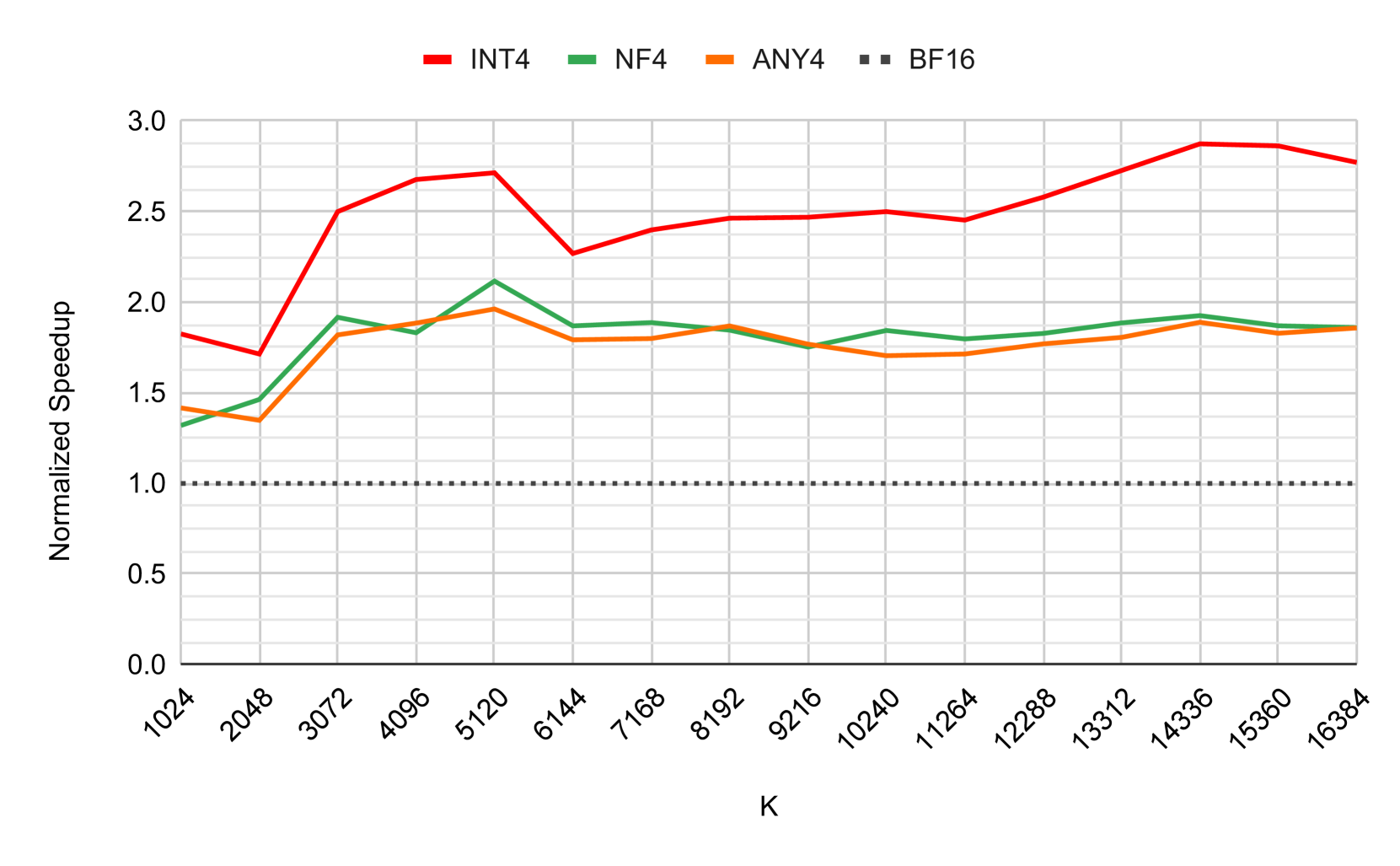
技术框架:any4的整体框架包括以下几个关键步骤:首先,使用少量校准数据(例如,单个精心策划的多样化样本)来确定最佳的4比特数值表示。然后,使用学习到的数值表示对模型的权重进行量化。最后,使用量化后的模型进行推理。为了加速推理过程,论文还开源了一个名为tinygemm的GPU矩阵乘法库,该库针对any4和其他量化方法进行了优化。
关键创新:any4的关键创新在于其可学习的数值表示方法。与传统的固定数值表示方法相比,any4能够根据模型的具体权重分布学习到更优的数值表示,从而提高量化精度。此外,any4不需要对权重或激活进行预处理,简化了量化流程,降低了计算复杂度。
关键设计:any4的关键设计包括:1) 使用少量校准数据来学习数值表示;2) 使用查找表(lookup table)在GPU上高效地实现量化和反量化操作;3) 开源tinygemm库,该库针对any4和其他量化方法进行了优化,提高了推理速度。具体的损失函数和网络结构细节在论文中可能未详细描述,需要参考开源代码以获取更多信息。
🖼️ 关键图片

📊 实验亮点
any4在Llama 2、Llama 3、Mistral和Mixtral等多种LLM上进行了评估,结果表明其性能优于int4、fp4和nf4等其他4比特量化方法。此外,any4的性能与需要预处理的AWQ和GPTQ等方法具有竞争力,同时仅需少量校准数据即可实现高性能。
🎯 应用场景
any4可应用于各种需要低精度量化的场景,例如在资源受限的设备上部署大型语言模型,或者在云端进行高效的模型推理。该方法可以显著减小模型大小,降低计算成本,并提高推理速度,从而使得LLM能够在更广泛的场景中得到应用。
📄 摘要(原文)
We present any4, a learned 4-bit weight quantization solution for large language models (LLMs) providing arbitrary numeric representations without requiring pre-processing of weights or activations. any4 yields higher accuracy compared to other related 4-bit numeric representation types: int4, fp4 and nf4, as evaluated on a range of model sizes, generations and families (Llama 2, Llama 3, Mistral and Mixtral). While any4 does not require preprocessing of weights or activations, it is also competitive with orthogonal techniques that require such preprocessing (e.g., AWQ and GPTQ). We also experiment with any3 and any2 and show competitiveness at lower bits. Additionally, we show that we can calibrate using a single curated diverse sample rather than hundreds of samples from a dataset as done in most quantization approaches. We also open source tinygemm, a latency optimized GPU matrix multiplication library for LLMs, that implements any4 using a GPU-efficient lookup table strategy along with other common quantization methods. We open source our code at https://github.com/facebookresearch/any4 .