Evaluating LLMs on Real-World Forecasting Against Expert Forecasters
作者: Janna Lu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-06 (更新: 2025-08-04)
💡 一句话要点
评估LLM在真实世界预测中的表现,对比专家预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预测 Brier分数 专家预测 真实世界评估
📋 核心要点
- 现有研究对LLM在真实世界预测任务中的能力评估不足,缺乏与人类专家预测的直接对比。
- 该研究对比了先进LLM与Metaculus平台上的顶级预测者,评估其在464个预测问题上的表现。
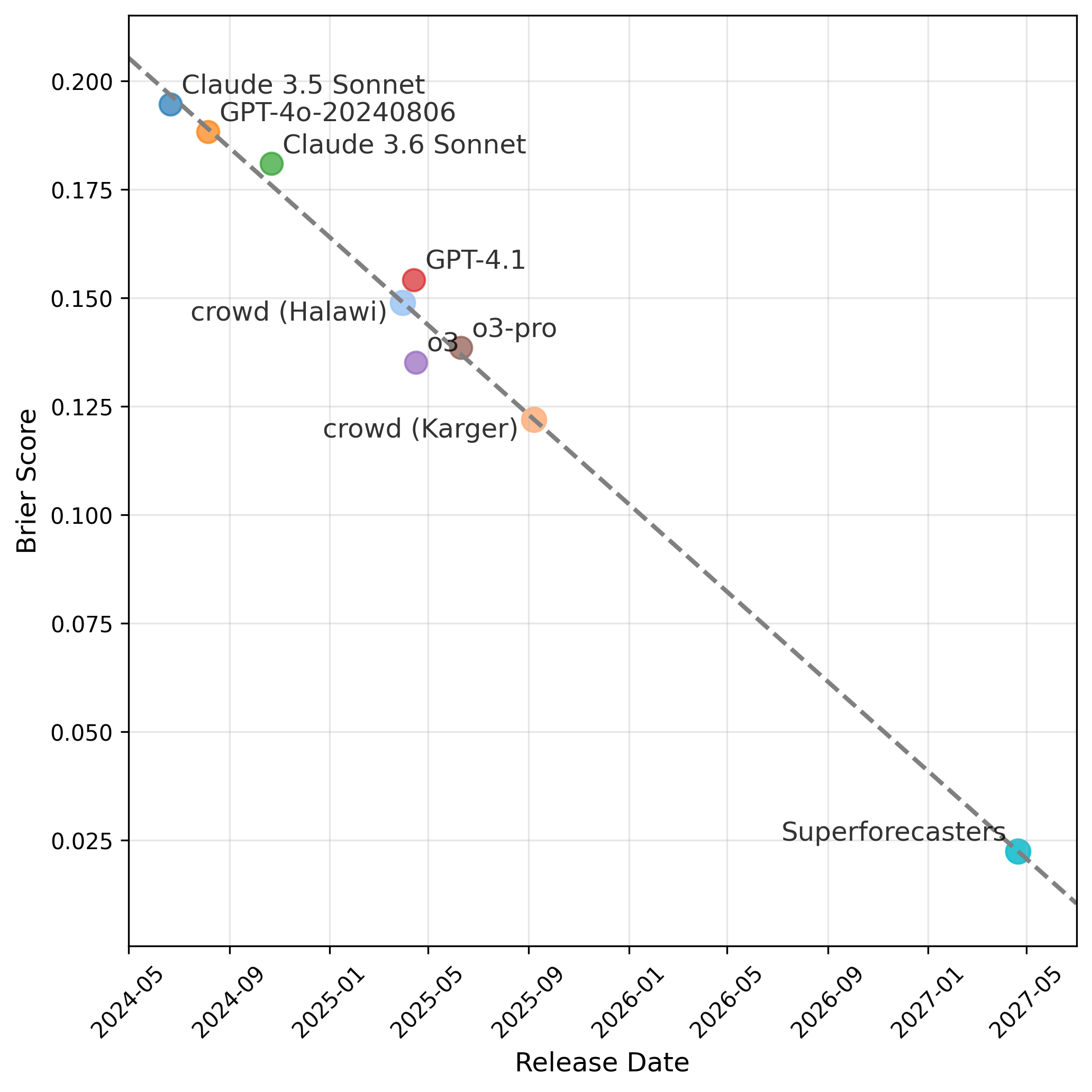
- 实验结果表明,LLM在Brier分数上优于人类群体,但与专家组相比仍有显著差距。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中展现了卓越的能力,但它们预测未来事件的能力仍未得到充分研究。一年前,大型语言模型在准确性方面难以接近人类群体。本文评估了最先进的LLM在Metaculus的464个预测问题上的表现,并将它们与顶级预测者的表现进行比较。前沿模型实现了表面上超过人类群体的Brier分数,但仍然明显低于专家组的表现。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在真实世界预测任务中的能力。现有方法主要依赖于在特定数据集上的评估,缺乏与人类专家预测能力的直接对比,难以衡量LLM在实际复杂场景下的预测性能。此外,如何设计有效的评估指标来衡量LLM的预测能力也是一个挑战。
核心思路:论文的核心思路是将LLM的预测结果与Metaculus平台上顶级预测者的预测结果进行对比,从而评估LLM在真实世界预测任务中的表现。Metaculus是一个汇集了大量人类预测的平台,其顶级预测者通常具有较高的预测准确性,因此可以作为评估LLM预测能力的一个有效基准。通过比较LLM与这些专家的表现,可以更客观地了解LLM在预测方面的优势和不足。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 从Metaculus平台收集464个预测问题及其对应的专家预测数据。2) 使用最先进的LLM(具体模型未知)对这些问题进行预测,生成LLM的预测结果。3) 使用Brier分数作为评估指标,计算LLM和专家组的预测准确性。4) 对比LLM和专家组的Brier分数,分析LLM在不同类型问题上的表现差异。
关键创新:该研究的关键创新在于将LLM的预测能力与真实世界中的专家预测能力进行直接对比。这种对比方法能够更客观地评估LLM在实际复杂场景下的预测性能,并揭示LLM在预测方面的优势和不足。此外,该研究使用了Metaculus平台的数据,该平台汇集了大量人类预测,为评估LLM的预测能力提供了一个可靠的基准。
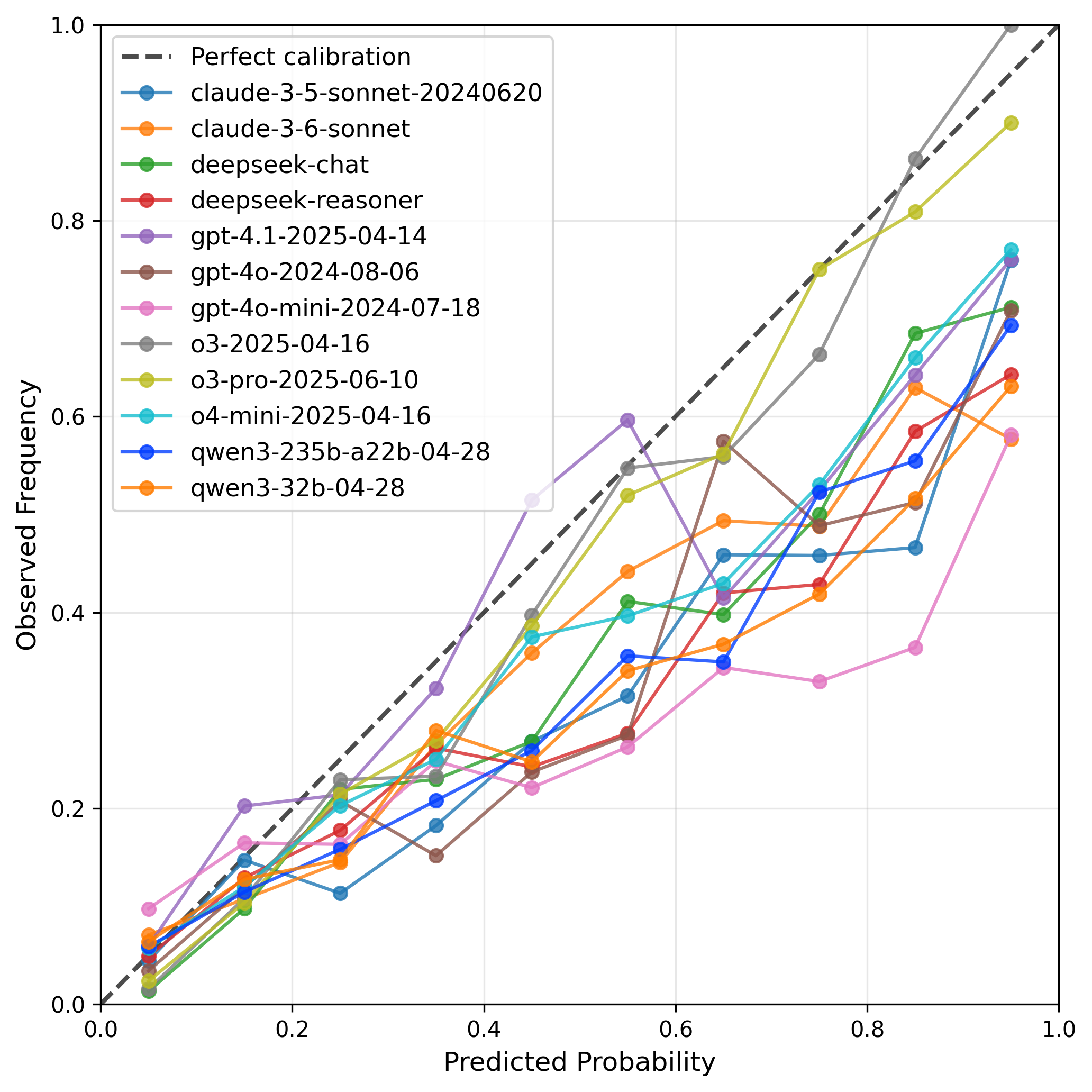
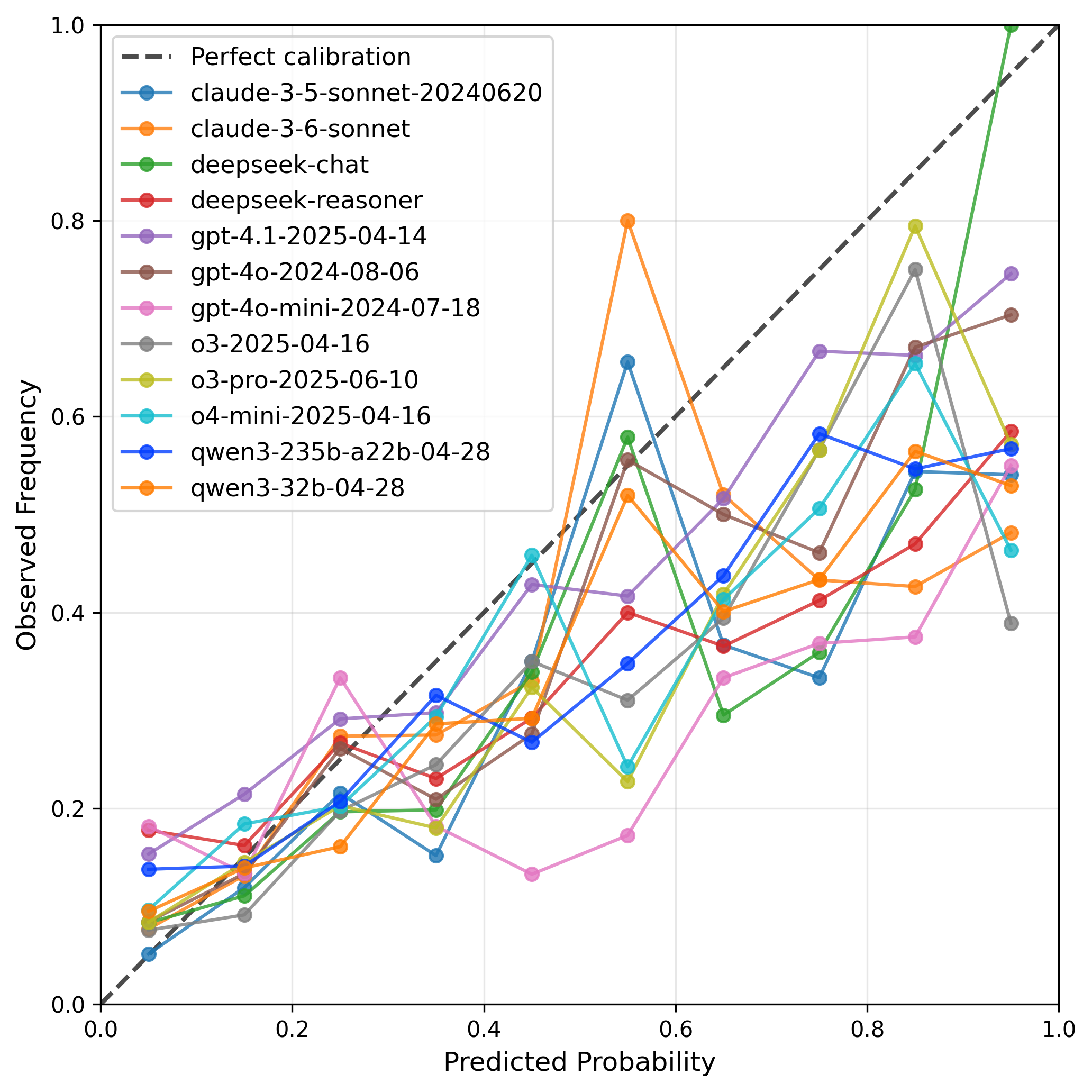
关键设计:论文的关键设计包括:1) 选择Metaculus平台作为数据来源,保证了数据的真实性和多样性。2) 使用Brier分数作为评估指标,Brier分数是一种常用的概率预测评估指标,能够有效地衡量预测的准确性。3) 选择最先进的LLM(具体模型未知)进行实验,保证了评估结果的代表性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,最先进的LLM在Brier分数上表面上超过了人类群体,但在预测准确性方面仍然明显低于专家组。这表明LLM在某些预测任务中具有一定的潜力,但仍需进一步改进才能达到专家的水平。具体的性能提升幅度未知。
🎯 应用场景
该研究的成果可应用于评估和改进LLM在预测任务中的能力,例如在金融预测、市场趋势分析、风险评估等领域。通过了解LLM在预测方面的优势和不足,可以更好地利用LLM辅助决策,提高决策的准确性和效率。此外,该研究也为未来LLM在预测领域的应用提供了参考。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities across diverse tasks, but their ability to forecast future events remains understudied. A year ago, large language models struggle to come close to the accuracy of a human crowd. I evaluate state-of-the-art LLMs on 464 forecasting questions from Metaculus, comparing their performance against top forecasters. Frontier models achieve Brier scores that ostensibly surpass the human crowd but still significantly underperform a group of experts.