ESSA: Evolutionary Strategies for Scalable Alignment
作者: Daria Korotyshova, Boris Shaposhnikov, Alexey Malakhov, Alexey Khokhulin, Nikita Surnachev, Kirill Ovcharenko, George Bredis, Alexey Gorbatovski, Viacheslav Sinii, Daniil Gavrilov
分类: cs.LG
发布日期: 2025-07-06 (更新: 2025-12-22)
💡 一句话要点
ESSA:一种可扩展的进化策略对齐大型语言模型,无需梯度优化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 进化策略 低秩适配器 黑盒优化 梯度无关优化
📋 核心要点
- 现有LLM对齐方法依赖于基于梯度的强化学习,如PPO和GRPO,存在训练复杂、内存需求高和超参数调优困难等问题。
- ESSA采用进化策略,仅通过前向推理和黑盒优化对齐LLM,避免了梯度计算,降低了计算复杂度和资源需求。
- 实验表明,ESSA在多个基准测试中优于GRPO,并在大规模设置中展现出更强的扩展性,同时降低了时间和工程成本。
📝 摘要(中文)
本文提出了一种名为ESSA(Evolutionary Strategies for Scalable Alignment)的框架,它使用进化策略对齐大型语言模型(LLM),无需梯度优化,仅依赖前向推理和黑盒优化。ESSA专注于优化低秩适配器(LoRA),并通过优化每个适配器矩阵奇异值分解(SVD)后的奇异值来进一步压缩参数空间。这种降维使得进化搜索即使对于非常大的模型也切实可行,并允许在量化的INT4和INT8推理模式下高效运行。在多个基准测试中,ESSA将Qwen2.5-Math-7B在GSM8K上的测试精度提高了12.6%,在PRM800K上提高了14.8%,并将LLaMA3.1-8B在IFEval上的精度提高了22.5%,所有这些都与GRPO相比。在大规模设置中,ESSA显示出比基于梯度的方法更强的扩展性:在Qwen2.5-32B上,对于PRM800K,在16个GPU上达到接近最佳的精度速度是GRPO的两倍,在128个GPU上是GRPO的六倍。这些结果表明,进化策略是一种引人注目的、对硬件友好的LLM对齐替代方案,它将具有竞争力的质量与大大减少的挂钟时间和工程开销相结合。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法,如基于强化学习的方法(PPO、GRPO),依赖于梯度优化,这导致了训练过程的复杂性,需要大量的计算资源和内存,并且对超参数的调整非常敏感,尤其是在模型规模达到数十亿参数时,这些问题变得更加突出。
核心思路:ESSA的核心思路是利用进化策略(Evolutionary Strategies)进行黑盒优化,避免了梯度计算。通过仅使用前向推理和评估函数,ESSA能够有效地搜索参数空间,找到使模型与人类偏好对齐的最佳参数配置。这种方法特别适用于大规模模型,因为它降低了计算复杂度和内存需求。
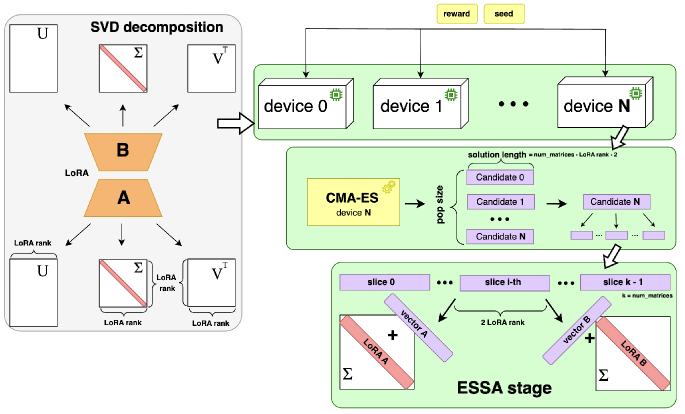
技术框架:ESSA的整体框架包括以下几个主要步骤:1) 初始化:随机初始化LoRA适配器的参数。2) 评估:使用评估函数(例如,基于人类反馈的奖励模型)评估当前参数配置下模型的性能。3) 变异:通过对当前参数进行微小的扰动(例如,添加高斯噪声)生成新的候选参数配置。4) 选择:根据评估结果,选择表现最佳的参数配置作为下一代的父代。5) 迭代:重复步骤2-4,直到达到预定的迭代次数或性能收敛。
关键创新:ESSA的关键创新在于:1) 使用进化策略进行LLM对齐,避免了梯度计算。2) 专注于优化LoRA适配器,降低了参数空间的维度。3) 通过优化LoRA适配器矩阵的奇异值分解(SVD)后的奇异值,进一步压缩参数空间。4) 能够在量化的INT4和INT8推理模式下高效运行。
关键设计:ESSA的关键设计包括:1) 使用低秩适配器(LoRA)来减少需要优化的参数数量。2) 对LoRA适配器矩阵进行奇异值分解(SVD),并仅优化奇异值,进一步降低参数空间的维度。3) 使用高斯噪声进行参数变异,并调整噪声的方差以控制搜索的步长。4) 使用基于排名的选择策略,选择表现最佳的参数配置作为下一代的父代。
🖼️ 关键图片
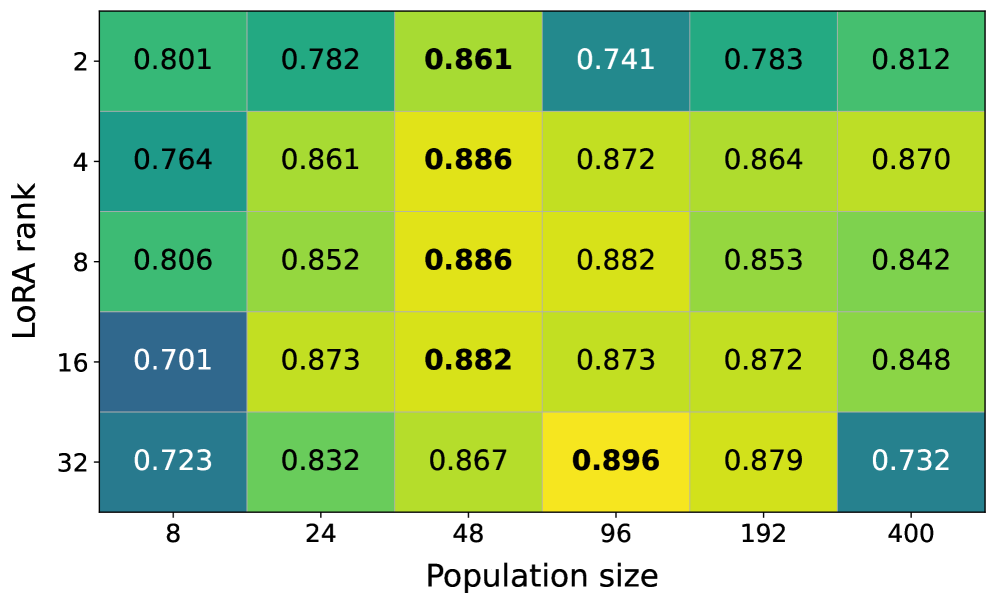
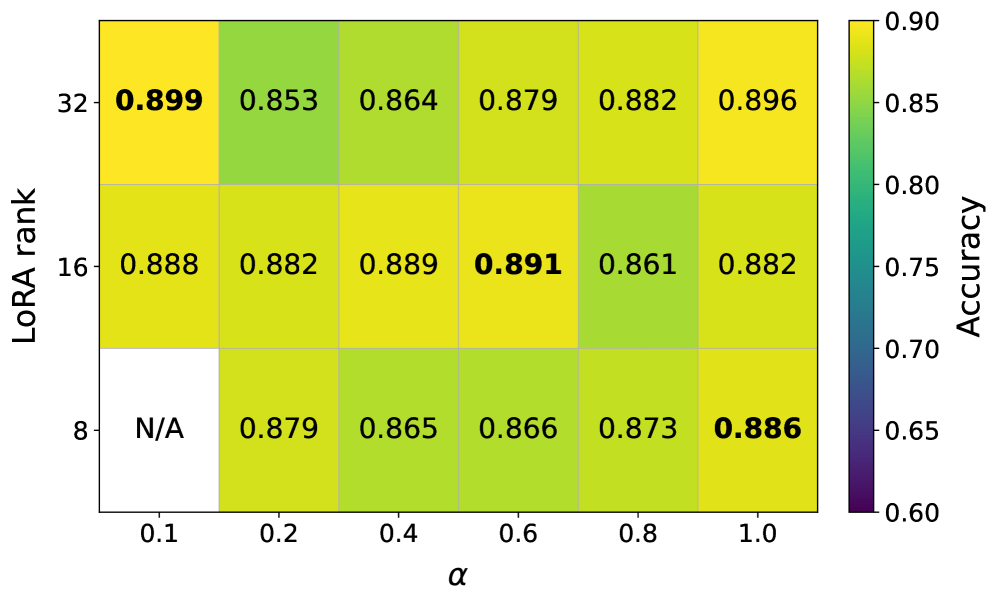
📊 实验亮点
ESSA在多个基准测试中取得了显著的性能提升。例如,在GSM8K和PRM800K上,ESSA将Qwen2.5-Math-7B的测试精度分别提高了12.6%和14.8%。在IFEval上,ESSA将LLaMA3.1-8B的精度提高了22.5%,所有这些都优于GRPO。此外,在大规模设置中,ESSA展现出更强的扩展性,在Qwen2.5-32B上,对于PRM800K,在16个GPU上达到接近最佳的精度速度是GRPO的两倍,在128个GPU上是GRPO的六倍。
🎯 应用场景
ESSA具有广泛的应用前景,可用于对齐各种大型语言模型,使其更好地服务于特定任务和人类偏好。该方法尤其适用于资源受限的环境,例如边缘设备或低功耗服务器。此外,ESSA还可以应用于其他机器学习模型的优化和对齐,例如图像生成模型和机器人控制系统。
📄 摘要(原文)
Alignment of Large Language Models (LLMs) typically relies on Reinforcement Learning from Human Feedback (RLHF) with gradient-based optimizers such as Proximal Policy Optimization (PPO) or Group Relative Policy Optimization (GRPO). While effective, these methods require complex distributed training, large memory budgets, and careful hyperparameter tuning, all of which become increasingly difficult at billion-parameter scale. We present ESSA, Evolutionary Strategies for Scalable Alignment, a gradient-free framework that aligns LLMs using only forward inference and black-box optimization. ESSA focuses optimization on Low-Rank Adapters (LoRA) and further compresses their parameter space by optimizing only the singular values from an singular value decomposition (SVD) of each adapter matrix. This dimensionality reduction makes evolutionary search practical even for very large models and allows efficient operation in quantized INT4 and INT8 inference mode. Across these benchmarks ESSA improves the test accuracy of Qwen2.5-Math-7B by 12.6% on GSM8K and 14.8% on PRM800K, and raises the accuracy of LLaMA3.1-8B on IFEval by 22.5%, all compared with GRPO. In large-scale settings ESSA shows stronger scaling than gradient-based methods: on Qwen2.5-32B for PRM800K it reaches near-optimal accuracy twice as fast on 16 GPUs and six times as fast on 128 GPUs compared with GRPO. These results position evolutionary strategies as a compelling, hardware-friendly alternative to gradient-based LLM alignment, combining competitive quality with substantially reduced wall-clock time and engineering overhead.