Interactive Groupwise Comparison for Reinforcement Learning from Human Feedback
作者: Jan Kompatscher, Danqing Shi, Giovanna Varni, Tino Weinkauf, Antti Oulasvirta
分类: cs.LG, cs.HC
发布日期: 2025-07-06 (更新: 2025-11-27)
备注: 10 pages, 8 figures in proceedings of Computer Graphics Forum
DOI: 10.1111/cgf.70290
💡 一句话要点
提出交互式分组比较方法,提升人机反馈强化学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机反馈强化学习 交互式可视化 分组比较 主动学习 机器人控制
📋 核心要点
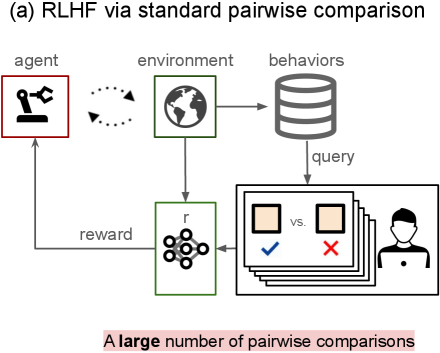
- 传统RLHF依赖成对比较,数据收集效率低,难以充分利用人类的视觉比较能力。
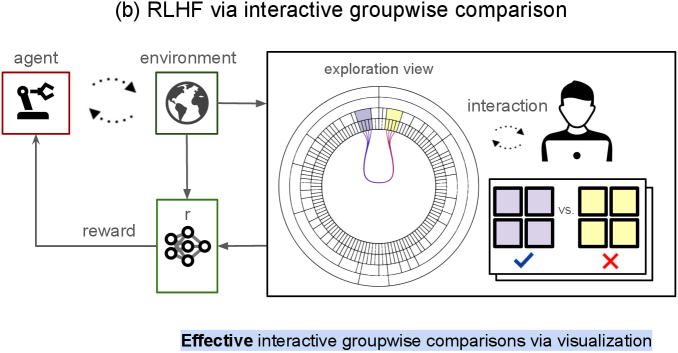
- 提出交互式分组比较方法,通过可视化界面辅助用户探索和比较多组行为样本。
- 实验表明,该方法显著提升了RLHF的性能,最终奖励提高69.34%,并降低了错误率。
📝 摘要(中文)
人机反馈强化学习(RLHF)已成为使AI行为与人类偏好对齐的关键技术。传统RLHF通过成对比较收集数据,即让人类评估者指出两个样本中更偏好哪一个。本文提出一种交互式可视化方法,更好地利用人类的视觉能力来比较和探索整组样本。该界面包含两个联动视图:1) 探索视图,展示所有采样行为的上下文概览,并以分层聚类结构组织;2) 比较视图,展示两个选定的行为组以供用户查询。用户可以通过在这两个视图之间迭代,高效地探索大量行为集合。此外,我们设计了一种主动学习方法,用于推荐待比较的组。在六个模拟机器人任务中的评估表明,我们的方法使最终奖励提高了69.34%,降低了错误率,并获得了更好的策略。我们开源了代码,可以轻松集成到RLHF训练循环中,支持人机对齐的研究。
🔬 方法详解
问题定义:现有的人机反馈强化学习方法主要依赖于成对比较,即让人类评估者对两个行为样本进行偏好选择。这种方法存在效率低下的问题,尤其是在处理大量行为样本时,人类评估者难以全面了解和比较不同行为之间的差异,从而影响学习效果。此外,成对比较也无法充分利用人类的视觉感知能力,难以发现隐藏在群体行为中的模式和规律。
核心思路:本文的核心思路是利用交互式可视化技术,将大量的行为样本组织成易于理解和比较的组,并提供灵活的交互方式,让人类评估者能够更高效地探索和评估不同的行为策略。通过分组比较,人类可以更容易地发现不同策略的优缺点,从而提供更准确和有价值的反馈信号。
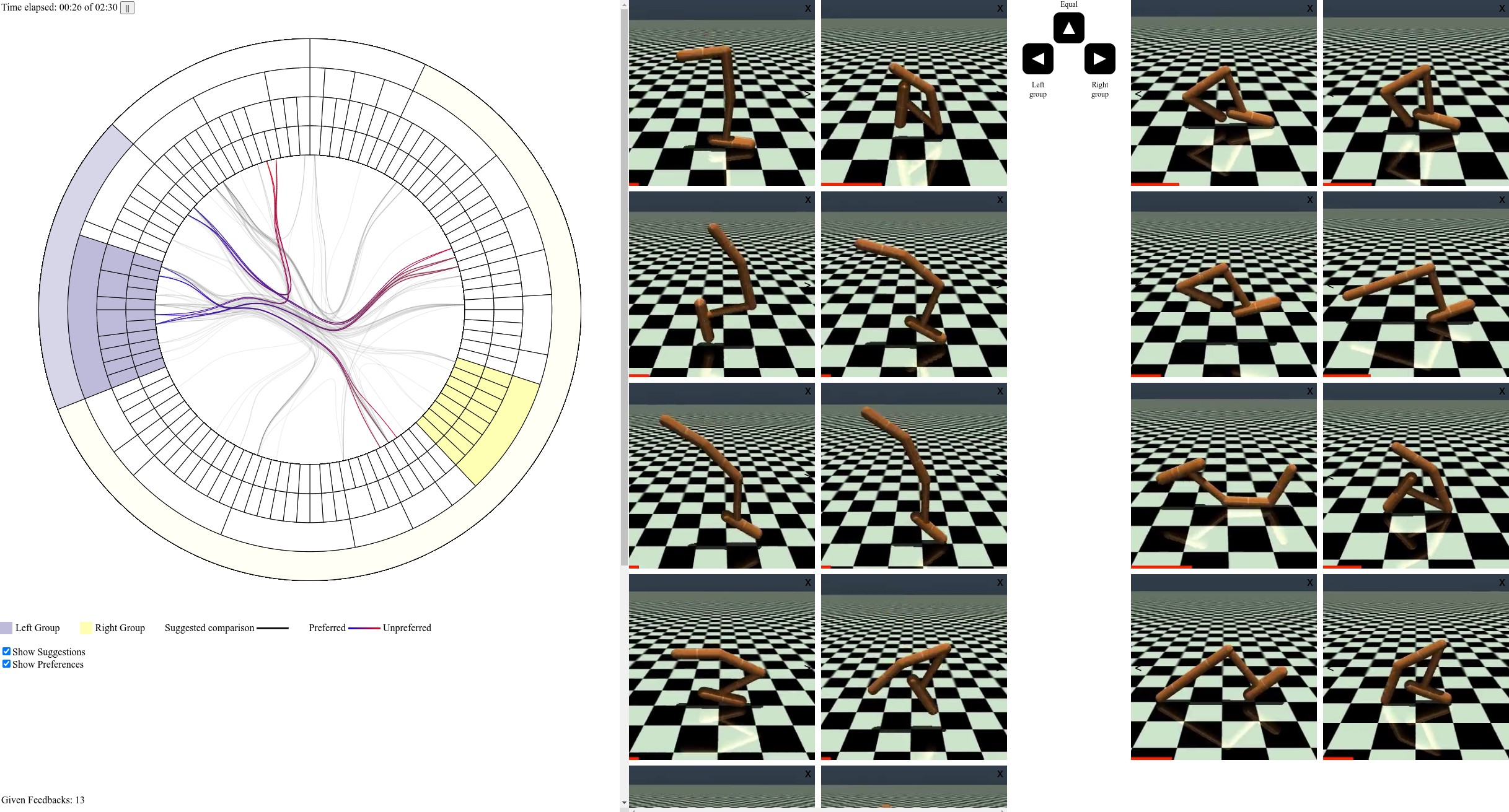
技术框架:该方法包含两个主要模块:探索视图和比较视图。探索视图通过分层聚类算法对所有采样行为进行组织,形成一个上下文概览,方便用户快速了解整体情况。比较视图则允许用户选择两个行为组进行详细比较,并提供相应的查询功能。用户可以在这两个视图之间迭代,不断缩小搜索范围,最终找到最优策略。此外,还设计了一个主动学习模块,用于推荐待比较的组,进一步提高效率。
关键创新:该方法最重要的创新点在于将交互式可视化技术引入到人机反馈强化学习中,通过分组比较的方式,充分利用人类的视觉感知能力,提高了数据收集的效率和质量。与传统的成对比较方法相比,该方法能够更全面地展示行为样本的特征,帮助人类评估者更好地理解不同策略的优缺点。
关键设计:在探索视图中,采用分层聚类算法(具体算法未知)对行为样本进行组织,并使用合适的颜色编码和可视化方式,突出不同组之间的差异。在比较视图中,提供多种查询方式,例如基于奖励值、行为特征等进行筛选。主动学习模块采用某种策略(具体策略未知)选择信息量最大的组进行推荐。损失函数和网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
在六个模拟机器人任务中,该方法相较于传统方法,最终奖励提高了69.34%,显著降低了错误率,并获得了更好的策略。这些实验结果充分证明了该方法在人机反馈强化学习中的有效性和优越性。具体对比的基线方法未知。
🎯 应用场景
该研究成果可广泛应用于机器人控制、游戏AI、自动驾驶等领域,通过人机协作的方式,训练出更符合人类偏好和价值观的智能体。该方法能够有效提升人机反馈强化学习的效率和效果,加速AI技术的落地应用,并促进人机协同智能的发展。
📄 摘要(原文)
Reinforcement learning from human feedback (RLHF) has emerged as a key enabling technology for aligning AI behaviour with human preferences. The traditional way to collect data in RLHF is via pairwise comparisons: human raters are asked to indicate which one of two samples they prefer. We present an interactive visualisation that better exploits the human visual ability to compare and explore whole groups of samples. The interface is comprised of two linked views: 1) an exploration view showing a contextual overview of all sampled behaviours organised in a hierarchical clustering structure; and 2) a comparison view displaying two selected groups of behaviours for user queries. Users can efficiently explore large sets of behaviours by iterating between these two views. Additionally, we devised an active learning approach suggesting groups for comparison. As shown by our evaluation in six simulated robotics tasks, our approach increases the final rewards by 69.34%. It leads to lower error rates and better policies. We open-source the code that can be easily integrated into the RLHF training loop, supporting research on human-AI alignment.