Consistency-Aware Padding for Incomplete Multi-Modal Alignment Clustering Based on Self-Repellent Greedy Anchor Search
作者: Shubin Ma, Liang Zhao, Mingdong Lu, Yifan Guo, Bo Xu
分类: cs.LG, cs.CV
发布日期: 2025-07-05
备注: Accepted at IJCAI 2025. 9 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出CAPIMAC,解决不完整多模态数据对齐聚类中的数据缺失填充问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 不完整数据 数据对齐 聚类算法 锚点搜索 噪声对比学习 数据填充 自排斥算法
📋 核心要点
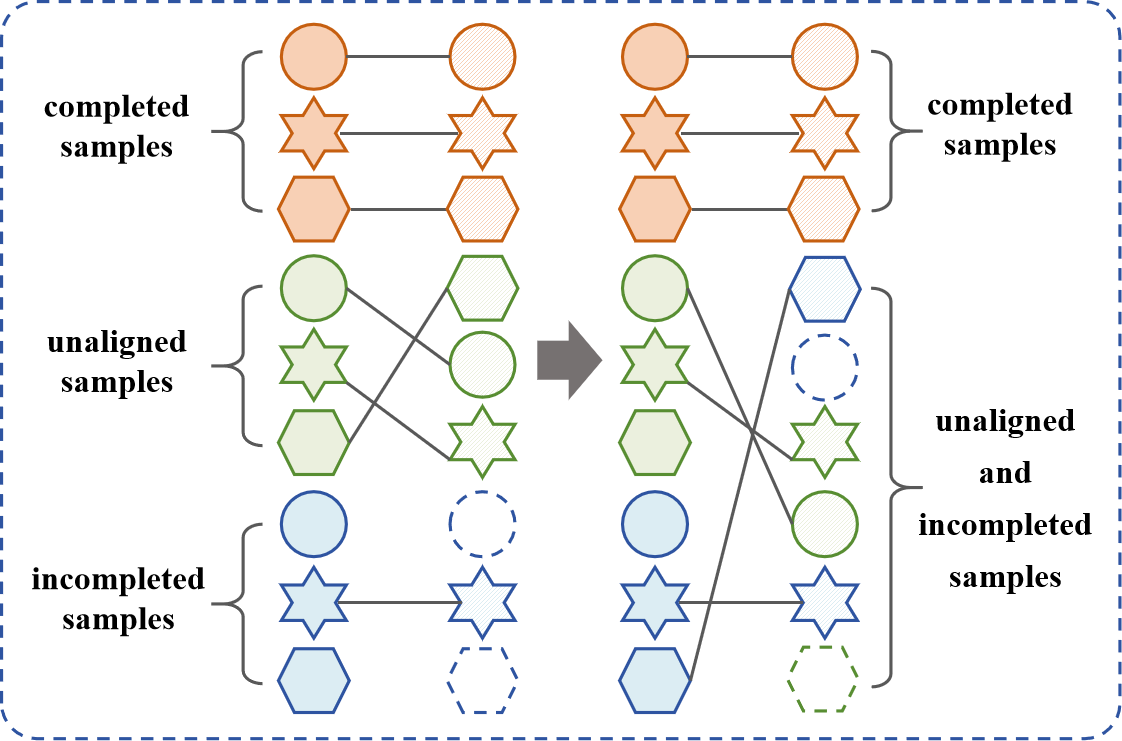
- 现有方法在多模态数据缺失填充中,未能有效处理不平衡和未对齐的数据,依赖于类级别的对齐,导致部分数据样本匹配不佳。
- CAPIMAC方法通过自排斥贪婪锚点搜索模块(SRGASM)寻找锚点,并利用一致性感知填充模块(CAPM)进行数据插补和对齐,提升数据融合质量。
- 实验结果表明,CAPIMAC在多个基准数据集上表现优异,证明了其在处理不完整多模态数据聚类问题上的有效性。
📝 摘要(中文)
本文针对多模态数据聚类中,由于传感器频率不一致和设备故障等因素导致的缺失和未对齐问题,提出了一种基于自排斥贪婪锚点搜索的一致性感知填充方法(CAPIMAC)。该方法首先设计了一个自排斥贪婪锚点搜索模块(SRGASM),利用自排斥随机游走和贪婪算法来识别锚点,从而重新表示不完整和未对齐的多模态数据。然后,基于噪声对比学习,设计了一致性感知填充模块(CAPM),有效地插补和对齐不平衡和未对齐的数据,从而提高多模态数据融合的质量。实验结果表明,该方法在基准数据集上优于现有方法。
🔬 方法详解
问题定义:论文旨在解决多模态数据聚类中,由于数据采集过程中的不一致性(例如传感器频率差异、设备故障)导致的模态数据缺失和未对齐问题。现有方法通常依赖于类级别的对齐,忽略了样本级别的细粒度对齐,导致数据融合质量下降,影响聚类性能。
核心思路:论文的核心思路是利用锚点搜索来重新表示不完整和未对齐的多模态数据,并通过一致性感知的填充方法来插补缺失数据,同时保证不同模态之间的一致性。通过这种方式,可以有效地融合多模态信息,提高聚类效果。
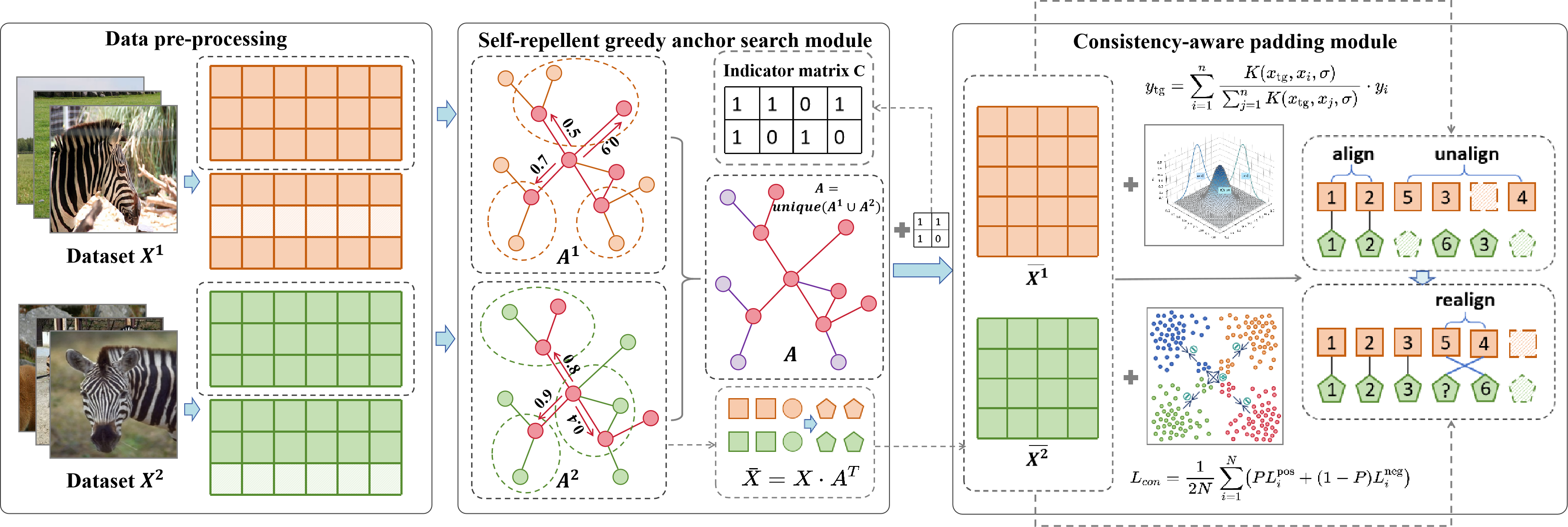
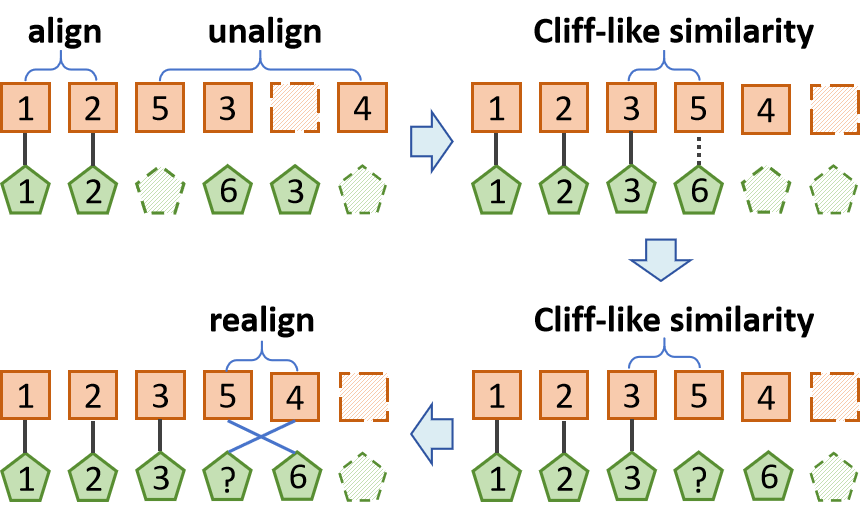
技术框架:CAPIMAC方法主要包含两个模块:自排斥贪婪锚点搜索模块(SRGASM)和一致性感知填充模块(CAPM)。首先,SRGASM通过自排斥随机游走和贪婪算法寻找合适的锚点,用于数据的重新表示。然后,CAPM基于噪声对比学习,利用找到的锚点信息,对缺失数据进行插补,并对齐不同模态的数据。
关键创新:该方法的主要创新在于提出了自排斥贪婪锚点搜索模块(SRGASM)和一致性感知填充模块(CAPM)。SRGASM通过自排斥机制避免锚点过于集中,保证了锚点的多样性,从而更好地表示数据。CAPM则通过噪声对比学习,保证了填充数据的一致性,避免了引入噪声。
关键设计:SRGASM中,自排斥随机游走的步长和贪婪算法的迭代次数是关键参数,需要根据数据集的特点进行调整。CAPM中,噪声对比学习的损失函数设计至关重要,需要保证填充数据与已有数据的一致性,同时避免过拟合。具体的网络结构和损失函数细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CAPIMAC方法在多个基准数据集上取得了优于现有方法的性能。具体的性能提升幅度和对比基线需要在论文中查找(未知)。该方法在处理不完整和未对齐的多模态数据聚类问题上具有显著优势。
🎯 应用场景
该研究成果可应用于多种多模态数据分析场景,例如:医疗诊断(结合影像、基因组等多模态数据进行疾病预测)、智能监控(融合视频、音频等多模态信息进行异常行为检测)、自动驾驶(利用激光雷达、摄像头等多模态数据进行环境感知)等。通过有效处理不完整和未对齐的多模态数据,可以提升相关应用的性能和可靠性,具有重要的实际价值。
📄 摘要(原文)
Multimodal representation is faithful and highly effective in describing real-world data samples' characteristics by describing their complementary information. However, the collected data often exhibits incomplete and misaligned characteristics due to factors such as inconsistent sensor frequencies and device malfunctions. Existing research has not effectively addressed the issue of filling missing data in scenarios where multiview data are both imbalanced and misaligned. Instead, it relies on class-level alignment of the available data. Thus, it results in some data samples not being well-matched, thereby affecting the quality of data fusion. In this paper, we propose the Consistency-Aware Padding for Incomplete Multimodal Alignment Clustering Based on Self-Repellent Greedy Anchor Search(CAPIMAC) to tackle the problem of filling imbalanced and misaligned data in multimodal datasets. Specifically, we propose a self-repellent greedy anchor search module(SRGASM), which employs a self-repellent random walk combined with a greedy algorithm to identify anchor points for re-representing incomplete and misaligned multimodal data. Subsequently, based on noise-contrastive learning, we design a consistency-aware padding module (CAPM) to effectively interpolate and align imbalanced and misaligned data, thereby improving the quality of multimodal data fusion. Experimental results demonstrate the superiority of our method over benchmark datasets. The code will be publicly released at https://github.com/Autism-mm/CAPIMAC.git.