Skewed Score: A statistical framework to assess autograders
作者: Magda Dubois, Harry Coppock, Mario Giulianelli, Timo Flesch, Lennart Luettgau, Cozmin Ududec
分类: cs.LG, stat.ML
发布日期: 2025-07-04 (更新: 2025-07-09)
💡 一句话要点
提出Skewed Score框架,用于统计评估LLM自动评分器并检测潜在偏差。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 自动评分器 贝叶斯GLM 偏差检测 统计建模
📋 核心要点
- 现有LLM自动评分器可靠性参差不齐,且可能存在系统性偏差,影响评估结果的准确性。
- 论文提出基于贝叶斯GLM的统计框架,建模评分结果与评分器和被评估项目的属性关系,量化评分差异和偏差。
- 该方法可增强传统评估指标,提供不确定性估计,并明确不一致来源,提升自动评分器的稳健性和可解释性。
📝 摘要(中文)
本文提出了一种基于贝叶斯广义线性模型(GLM)的统计框架,用于评估大型语言模型(LLM)的自动评分器(autograders)。该框架旨在解决自动评分器在LLM输出评估中存在的可靠性问题和潜在的系统性偏差,这些偏差可能受到响应类型、评分方法、领域特异性等因素的影响。该方法将评估结果(如分数或成对偏好)建模为评分器属性(如人类或自动评分器)和被评估项目属性(如响应长度或生成LLM)的函数,从而量化评分差异和潜在偏差。此外,该方法还可用于增强传统的评估指标,如评分者间一致性,并提供不确定性估计和明确不一致的来源。总体而言,该方法有助于更稳健和可解释地使用自动评分器进行LLM评估,从而实现性能分析和偏差检测。
🔬 方法详解
问题定义:论文旨在解决LLM自动评分器在评估LLM输出时存在的可靠性问题和潜在偏差。现有方法缺乏对评分器和被评估项目属性的系统性考虑,难以量化评分差异和检测偏差,导致评估结果不够准确和可信。
核心思路:论文的核心思路是将评估结果建模为评分器属性(如人类或自动评分器)和被评估项目属性(如响应长度或生成LLM)的函数。通过这种方式,可以显式地量化评分差异,识别潜在的偏差来源,并提供更稳健和可解释的评估结果。
技术框架:该框架基于贝叶斯广义线性模型(GLM)。整体流程包括:1) 定义评分器和被评估项目的相关属性;2) 收集评估数据,包括评分结果和属性信息;3) 使用贝叶斯GLM建模评分结果与属性之间的关系;4) 进行模型推断,估计模型参数,并量化评分差异和偏差;5) 对结果进行分析和可视化,识别潜在的偏差来源。
关键创新:最重要的技术创新点在于将贝叶斯GLM应用于LLM自动评分器的评估,从而能够同时评估评分器并解决主要研究问题。与现有方法相比,该方法能够显式地量化评分差异和偏差,并提供不确定性估计,从而提高评估结果的可靠性和可解释性。
关键设计:关键设计包括:1) 选择合适的GLM模型,例如logistic回归或泊松回归,取决于评估结果的类型;2) 定义合适的先验分布,以反映对模型参数的先验知识;3) 使用马尔可夫链蒙特卡洛(MCMC)方法进行模型推断,估计模型参数;4) 设计合适的指标,以量化评分差异和偏差,例如差异的后验分布或偏差的置信区间。
🖼️ 关键图片
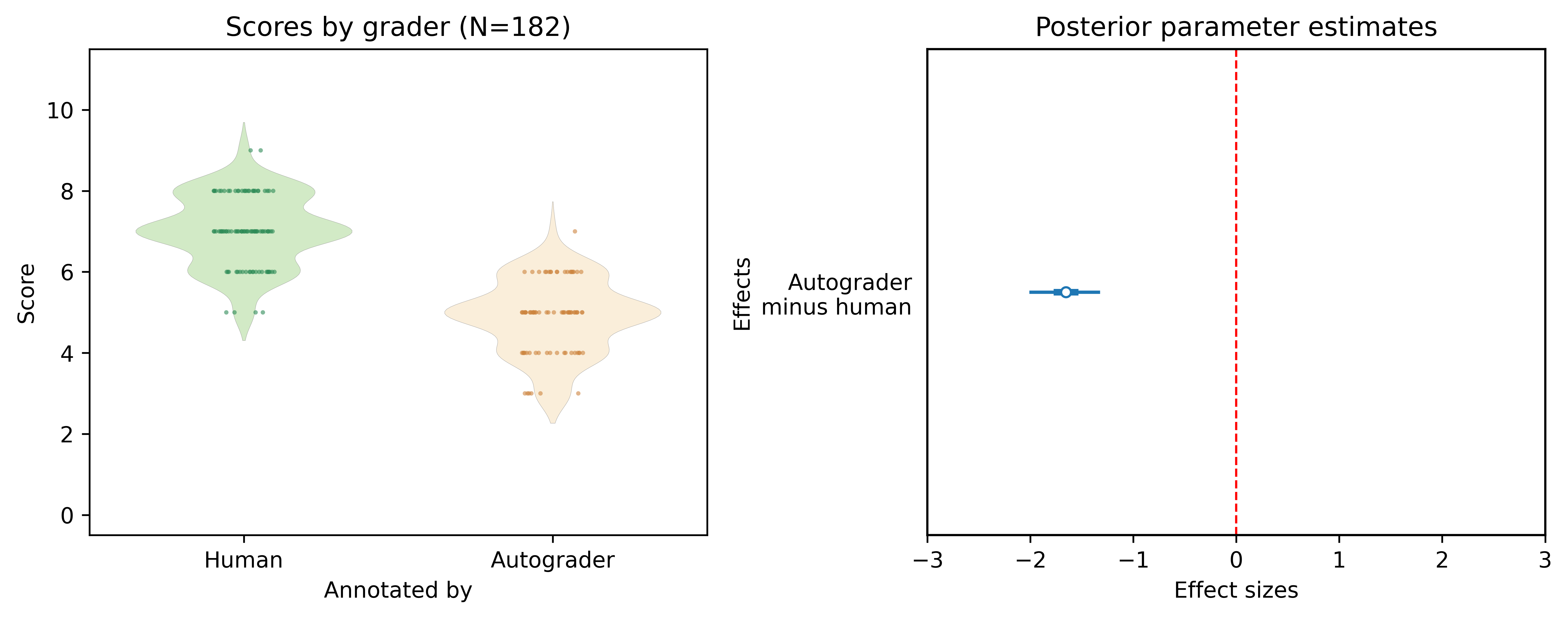
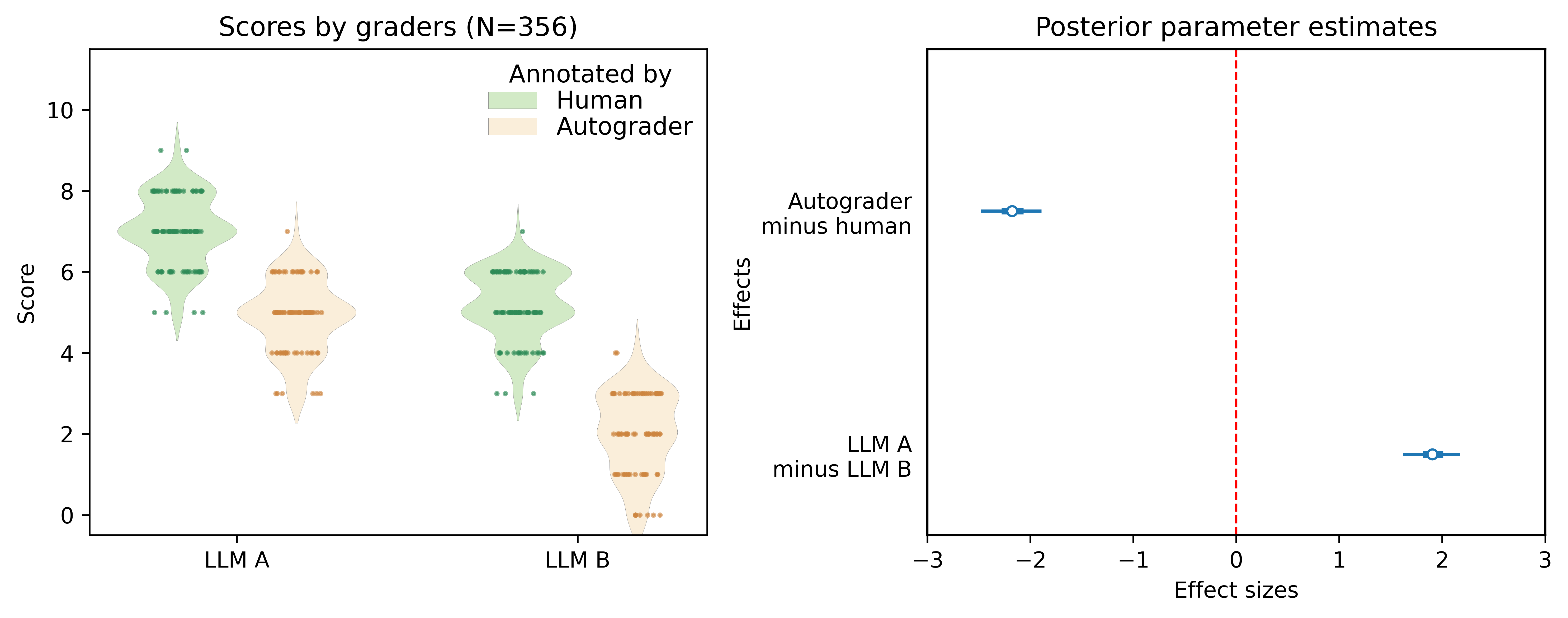

📊 实验亮点
论文提出的Skewed Score框架能够有效量化自动评分器中的偏差,并提供不确定性估计,从而提高LLM评估的可靠性和可解释性。虽然具体实验数据未在摘要中体现,但该框架为自动评分器的性能分析和偏差检测提供了有力工具,为后续研究奠定了基础。
🎯 应用场景
该研究成果可广泛应用于LLM的评估和选择,例如在开发新的LLM时,可以使用该框架评估不同自动评分器的性能,并选择最可靠的评分器。此外,该框架还可以用于检测和纠正自动评分器中的偏差,从而提高评估结果的公平性和公正性。该方法还有助于提升LLM在教育、客服、内容创作等领域的应用效果。
📄 摘要(原文)
The evaluation of large language model (LLM) outputs is increasingly performed by other LLMs, a setup commonly known as "LLM-as-a-judge", or autograders. While autograders offer a scalable alternative to human evaluation, they have shown mixed reliability and may exhibit systematic biases, depending on response type, scoring methodology, domain specificity, or other factors. Here we propose a statistical framework based on Bayesian generalised linear models (GLMs) that enables researchers to simultaneously assess their autograders while addressing their primary research questions (e.g., LLM evaluation). Our approach models evaluation outcomes (e.g., scores or pairwise preferences) as a function of properties of the grader (e.g., human vs. autograder) and the evaluated item (e.g., response length or the LLM that generated it), allowing for explicit quantification of scoring differences and potential biases within a unified framework. In addition, our method can be used to augment traditional metrics such as inter-rater agreement, by providing uncertainty estimates and clarifying sources of disagreement. Overall, this approach contributes to more robust and interpretable use of autograders in LLM evaluation, enabling both performance analysis and bias detection.