Action Robust Reinforcement Learning via Optimal Adversary Aware Policy Optimization
作者: Buqing Nie, Yangqing Fu, Jingtian Ji, Yue Gao
分类: cs.LG
发布日期: 2025-07-04
💡 一句话要点
提出OA-PI框架,增强强化学习策略在动作扰动下的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 鲁棒性 对抗训练 动作扰动 策略优化
📋 核心要点
- 现有强化学习策略易受动作扰动影响,限制了其在实际场景中的应用。
- 提出最优对抗感知策略迭代(OA-PI)框架,提升策略在对抗环境下的鲁棒性。
- 实验表明,该方法能有效增强DRL策略的鲁棒性,同时保持性能和样本效率。
📝 摘要(中文)
强化学习(RL)在序列决策任务中取得了显著成功。然而,最近的研究表明,RL策略容易受到各种扰动的影响,这引发了人们对其在实际应用中的有效性和安全性的担忧。本文关注RL策略对动作扰动的鲁棒性,并提出了一种名为最优对抗感知策略迭代(OA-PI)的新框架。该框架通过评估和改进策略在相应最优对抗下的性能,来增强在各种扰动下的动作鲁棒性。此外,我们的方法可以集成到主流的DRL算法中,如Twin Delayed DDPG (TD3)和Proximal Policy Optimization (PPO),在保持名义性能和样本效率的同时,有效地提高动作鲁棒性。在各种环境下的实验结果表明,我们的方法有效地增强了DRL策略对不同动作对抗的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决强化学习策略在面对动作扰动时鲁棒性不足的问题。现有的强化学习方法通常假设环境是静态的,没有考虑到实际应用中可能存在的各种动作扰动,这导致训练出的策略在真实环境中表现不佳,甚至失效。
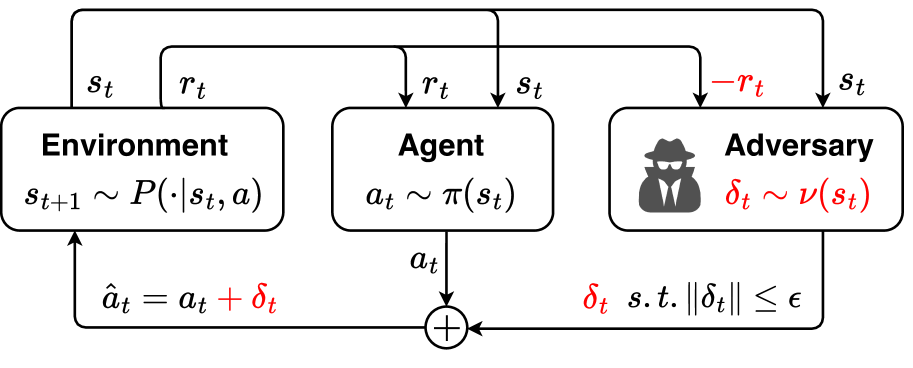
核心思路:论文的核心思路是通过对抗训练来提高策略的鲁棒性。具体来说,就是训练一个最优的对抗者,该对抗者能够对智能体的动作进行扰动,从而使得智能体的性能下降。然后,智能体通过与该对抗者进行博弈,学习如何在存在扰动的情况下做出正确的决策,从而提高策略的鲁棒性。
技术框架:OA-PI框架包含两个主要部分:策略评估和策略改进。在策略评估阶段,通过寻找最优的对抗者来评估当前策略的鲁棒性。在策略改进阶段,利用策略梯度方法,根据对抗环境下的性能来更新策略。该框架可以迭代地进行策略评估和策略改进,直到策略收敛。该框架可以集成到现有的DRL算法中,例如TD3和PPO。
关键创新:论文的关键创新在于提出了一种最优对抗感知的策略迭代框架。与传统的对抗训练方法不同,该方法不是随机生成对抗样本,而是通过寻找最优的对抗者来评估和改进策略。这种方法能够更有效地提高策略的鲁棒性。
关键设计:论文中,对抗者的目标是最大化智能体的损失函数。对抗者的动作空间与智能体的动作空间相同,并且对抗者的动作幅度受到一定的限制。论文使用策略梯度方法来训练对抗者。智能体的损失函数包括两部分:一部分是原始的强化学习损失函数,另一部分是对抗损失函数。对抗损失函数衡量的是智能体在对抗环境下的性能。
🖼️ 关键图片
📊 实验亮点
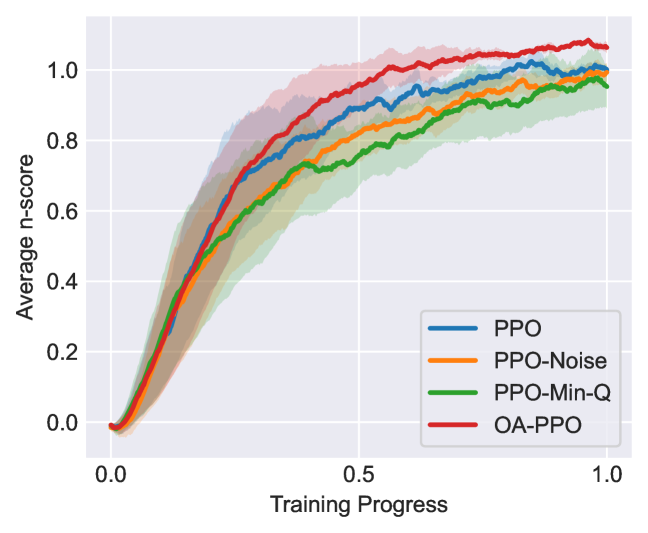
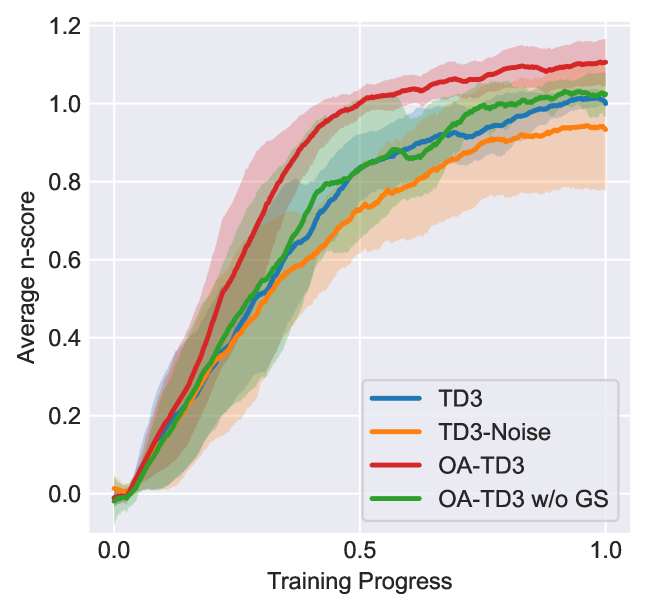
实验结果表明,OA-PI框架能够显著提高DRL策略在各种动作扰动下的鲁棒性。例如,在MuJoCo环境中,与基线方法相比,OA-PI框架能够将策略的平均回报提高10%-20%。此外,OA-PI框架还能够保持策略的样本效率和名义性能。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。在这些领域中,智能体需要在复杂和不确定的环境中做出决策,而动作扰动是不可避免的。通过提高策略的鲁棒性,可以使得智能体在这些环境中更加安全和可靠地运行。未来的研究可以探索更复杂的对抗策略和更有效的训练方法。
📄 摘要(原文)
Reinforcement Learning (RL) has achieved remarkable success in sequential decision tasks. However, recent studies have revealed the vulnerability of RL policies to different perturbations, raising concerns about their effectiveness and safety in real-world applications. In this work, we focus on the robustness of RL policies against action perturbations and introduce a novel framework called Optimal Adversary-aware Policy Iteration (OA-PI). Our framework enhances action robustness under various perturbations by evaluating and improving policy performance against the corresponding optimal adversaries. Besides, our approach can be integrated into mainstream DRL algorithms such as Twin Delayed DDPG (TD3) and Proximal Policy Optimization (PPO), improving action robustness effectively while maintaining nominal performance and sample efficiency. Experimental results across various environments demonstrate that our method enhances robustness of DRL policies against different action adversaries effectively.