Conformal Information Pursuit for Interactively Guiding Large Language Models
作者: Kwan Ho Ryan Chan, Yuyan Ge, Edgar Dobriban, Hamed Hassani, René Vidal
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-07-04 (更新: 2025-11-07)
💡 一句话要点
提出C-IP方法以优化大语言模型的交互式问答性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 交互式问答 信息追求 保形预测 不确定性估计 医疗应用 机器学习
📋 核心要点
- 现有的信息追求算法在估计大语言模型的不确定性时存在困难,导致查询选择不佳。
- 提出的保形信息追求(C-IP)方法通过保形预测集来更准确地估计不确定性,从而优化查询策略。
- 实验表明,C-IP在多个任务中均表现出更好的预测性能和更短的查询链,尤其在医疗场景中具有较高的解释性。
📝 摘要(中文)
本文探讨了在交互式问答任务中,如何通过序列查询策略最小化查询次数。现有的信息追求(IP)算法在估计互信息和条件熵时面临挑战,导致查询选择和预测性能不佳。为此,提出了基于保形预测集的保形信息追求(C-IP)方法,利用保形预测集的平均大小来更好地估计不确定性。实验结果表明,C-IP在“20 Questions”任务中表现优于传统方法,并在医疗场景中实现了与单轮预测相媲美的性能,同时提高了解释性。
🔬 方法详解
问题定义:本文旨在解决在交互式问答中,如何有效地选择查询以最小化用户交互次数的问题。现有方法在估计互信息和条件熵时存在过度自信或不足自信的问题,导致查询选择不理想。
核心思路:提出的C-IP方法通过保形预测集来估计不确定性,避免了传统方法对条件熵的依赖,从而实现更有效的信息获取。该方法利用保形预测集的大小作为不确定性的度量,提供了一种分布无关且稳健的估计方式。
技术框架:C-IP的整体架构包括信息查询模块和不确定性估计模块。信息查询模块负责选择最优查询,而不确定性估计模块则通过计算保形预测集的平均大小来评估当前的不确定性。
关键创新:C-IP的主要创新在于将保形预测集与不确定性估计相结合,提供了一种新的信息获取策略。这种方法与传统的基于条件熵的策略相比,更加稳健且不依赖于特定的概率分布假设。
关键设计:在C-IP中,关键参数包括保形预测集的构建方法和不确定性度量的计算方式。设计中还考虑了查询的选择策略,以确保每次查询都能最大化信息增益。
🖼️ 关键图片

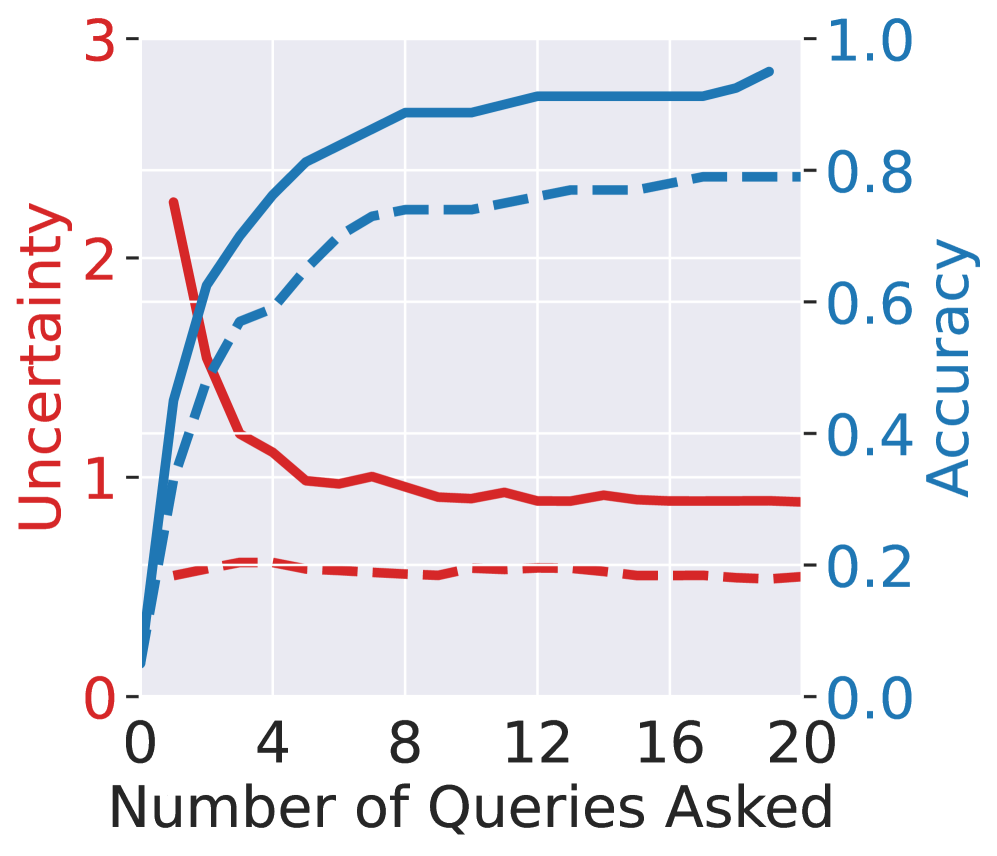
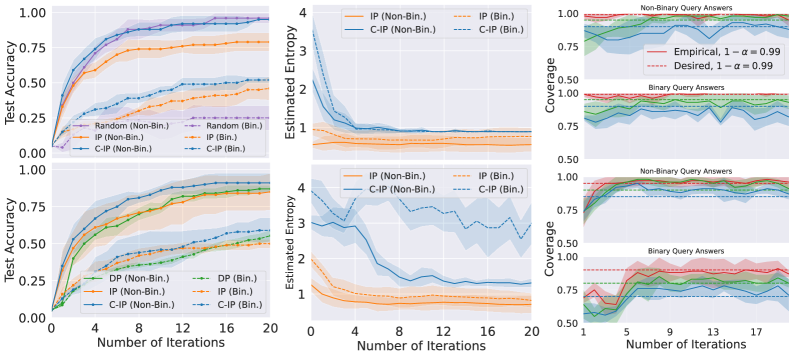
📊 实验亮点
实验结果显示,C-IP在“20 Questions”任务中相比于传统信息追求方法,预测性能提升显著,查询链长度缩短。此外,在MediQ数据集的医疗场景中,C-IP与单轮预测的性能相当,但提供了更好的可解释性,展示了其在实际应用中的优势。
🎯 应用场景
该研究的潜在应用领域包括医疗问答系统、教育辅导以及客户服务等交互式场景。通过优化查询策略,C-IP能够提高用户体验,减少交互成本,并在复杂任务中提供更高的准确性和解释性,具有重要的实际价值和未来影响。
📄 摘要(原文)
A significant use case of instruction-finetuned Large Language Models (LLMs) is to solve question-answering tasks interactively. In this setting, an LLM agent is tasked with making a prediction by sequentially querying relevant information from the user, as opposed to a single-turn conversation. This paper explores sequential querying strategies that aim to minimize the expected number of queries. One such strategy is Information Pursuit (IP), a greedy algorithm that at each iteration selects the query that maximizes information gain or equivalently minimizes uncertainty. However, obtaining accurate estimates of mutual information or conditional entropy for LLMs is very difficult in practice due to over- or under-confident LLM proba- bilities, which leads to suboptimal query selection and predictive performance. To better estimate the uncertainty at each iteration, we propose Conformal Information Pursuit (C-IP), an alternative approach to sequential information gain based on conformal prediction sets. More specifically, C-IP leverages a relationship between prediction sets and conditional entropy at each iteration to estimate uncertainty based on the average size of conformal prediction sets. In contrast to conditional entropy, we find that conformal prediction sets are a distribution-free and robust method of measuring uncertainty. Experiments with 20 Questions show that C-IP obtains better predictive performance and shorter query-answer chains compared to previous approaches to IP and uncertainty-based chain-of-thought methods. Furthermore, extending to an interactive medical setting between a doctor and a patient on the MediQ dataset, C-IP achieves competitive performance with direct single-turn prediction while offering greater interpretability.