ExPO: Unlocking Hard Reasoning with Self-Explanation-Guided Reinforcement Learning
作者: Ruiyang Zhou, Shuozhe Li, Amy Zhang, Liu Leqi
分类: cs.LG, cs.CL
发布日期: 2025-07-03 (更新: 2026-01-14)
备注: Accepted to NeurIPS 2025 (Poster). Code available at https://github.com/HumainLab/ExPO_rl_reasoning_by_explanation
🔗 代码/项目: GITHUB
💡 一句话要点
ExPO:通过自解释引导的强化学习解锁复杂推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自解释性 复杂推理 策略优化 探索与利用
📋 核心要点
- 现有强化学习方法在复杂推理任务中,依赖模型生成正样本的初始能力,缺乏有效探索机制。
- ExPO通过ground-truth答案引导,生成高质量的自解释样本,提升模型策略与推理轨迹的一致性。
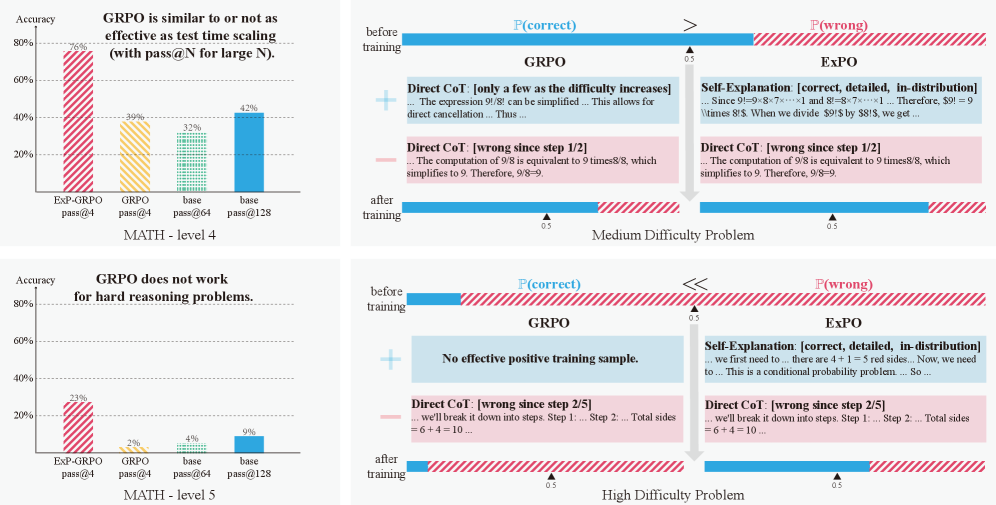
- 实验表明,ExPO在MATH level-5等任务上,显著提升了学习效率和最终性能,超越了专家演示方法。
📝 摘要(中文)
通过强化学习进行自我提升的方法在复杂的推理任务中常常失败,因为GRPO风格的后训练方法依赖于模型生成正样本的初始能力。如果没有引导式的探索,这些方法仅仅是强化模型已经知道的东西(分布锐化),而不是使模型能够解决那些它最初无法生成正确解的问题。为了在这种情况下解锁推理能力,模型必须探索超出其当前输出分布的新推理轨迹。这种探索需要获得足够好的正样本来引导学习。虽然专家演示似乎是一个自然的解决方案,但我们发现它们在强化学习后训练中通常无效。相反,我们确定了有效正样本的两个关键属性:它们应该(1)在当前策略下是可能的,并且(2)增加模型预测正确答案的可能性。基于这些见解,我们提出了自解释策略优化(ExPO)——一个简单且模块化的框架,通过以ground-truth答案为条件来生成此类样本。它可以与流行的强化学习训练方法(如GRPO和DPO)集成。ExPO能够进行有效的探索,并引导模型产生比专家编写的CoT更符合其策略的推理轨迹,同时确保比其自身(不正确的)样本更高的质量。实验表明,ExPO提高了推理基准测试的学习效率和最终性能,在MATH level-5等具有挑战性的环境中超越了基于专家演示的方法,在这些环境中,模型最初的性能最差。
🔬 方法详解
问题定义:现有基于强化学习的推理能力提升方法,如GRPO,依赖于模型自身生成高质量的正样本。当模型初始推理能力不足时,难以生成有效的正样本,导致强化学习过程退化为简单的分布锐化,无法解锁新的推理路径。专家演示虽然可以提供正样本,但与模型自身的策略可能存在偏差,效果不佳。
核心思路:ExPO的核心思想是生成既符合当前策略,又能提高模型预测正确答案概率的正样本。通过以ground-truth答案为条件,引导模型生成自解释的推理过程,从而实现有效的探索和学习。这种方法旨在克服模型初始推理能力不足和专家演示偏差的问题。
技术框架:ExPO是一个模块化的框架,可以与现有的强化学习方法(如GRPO和DPO)集成。其主要流程包括:1) 使用当前策略生成推理轨迹;2) 以ground-truth答案为条件,生成自解释的正样本;3) 使用强化学习算法,基于生成的正样本更新模型策略。ExPO的关键在于自解释正样本的生成过程,它确保了样本既具有较高的策略概率,又能有效指导模型学习。
关键创新:ExPO的关键创新在于其自解释正样本的生成方式。与传统的专家演示方法不同,ExPO生成的样本更符合模型自身的策略,从而避免了策略偏差问题。与模型自身生成的(不正确的)样本相比,ExPO生成的样本质量更高,能够更有效地指导模型学习。这种自解释的生成方式实现了有效的探索和学习,解锁了模型在复杂推理任务中的潜力。
关键设计:ExPO的关键设计在于如何以ground-truth答案为条件,生成高质量的自解释样本。具体实现方式可能依赖于具体的任务和模型架构。一种常见的方法是使用条件语言模型,以ground-truth答案作为prompt,生成与答案相关的推理过程。损失函数的设计也至关重要,需要平衡策略概率和答案预测概率,以确保生成的样本既符合当前策略,又能有效指导模型学习。
🖼️ 关键图片
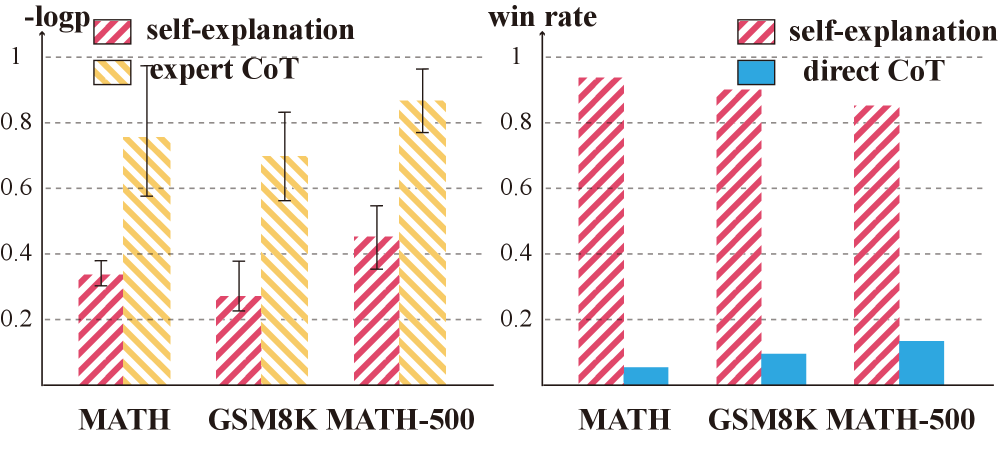

📊 实验亮点
实验结果表明,ExPO在MATH level-5等具有挑战性的推理任务上取得了显著的性能提升。例如,在MATH level-5上,ExPO超越了基于专家演示的方法,证明了其在解锁复杂推理能力方面的有效性。此外,ExPO还提高了学习效率,使模型能够更快地收敛到最优策略。
🎯 应用场景
ExPO具有广泛的应用前景,可用于提升各种需要复杂推理能力的AI系统的性能,例如数学问题求解、代码生成、知识图谱推理等。该方法能够有效解决模型初始能力不足的问题,使其在更具挑战性的任务中取得更好的表现,推动人工智能在复杂问题解决方面的应用。
📄 摘要(原文)
Self-improvement via RL often fails on complex reasoning tasks because GRPO-style post-training methods rely on the model's initial ability to generate positive samples. Without guided exploration, these approaches merely reinforce what the model already knows (distribution-sharpening) rather than enabling the model to solve problems where it initially generates no correct solutions. To unlock reasoning ability in such settings, the model must explore new reasoning trajectories beyond its current output distribution. Such exploration requires access to sufficiently good positive samples to guide the learning. While expert demonstrations seem like a natural solution, we find that they are often ineffective in RL post-training. Instead, we identify two key properties of effective positive samples: they should (1) be likely under the current policy, and (2) increase the model's likelihood of predicting the correct answer. Based on these insights, we propose $\textbf{Self-Explanation Policy Optimization (ExPO)}$-a simple and modular framework that generates such samples by conditioning on the ground-truth answer. It can be integrated with popular RL training methods like GRPO and DPO. ExPO enables efficient exploration and guides the model to produce reasoning trajectories more aligned with its policy than expert-written CoTs, while ensuring higher quality than its own (incorrect) samples. Experiments show that ExPO improves both learning efficiency and final performance on reasoning benchmarks, surpassing expert-demonstration-based methods in challenging settings such as MATH level-5, where the model initially struggles the most. Code is available at https://github.com/HumainLab/ExPO_rl_reasoning_by_explanation .