Understanding and Improving Length Generalization in Recurrent Models
作者: Ricardo Buitrago Ruiz, Albert Gu
分类: cs.LG
发布日期: 2025-07-03 (更新: 2025-10-12)
💡 一句话要点
针对循环模型长度泛化性不足问题,提出基于状态覆盖的训练干预方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 循环模型 长度泛化 状态空间模型 训练干预 长序列建模
📋 核心要点
- 循环模型在长序列处理中面临长度泛化问题,即在训练长度之外性能显著下降。
- 论文提出“未探索状态假设”,认为训练数据未能覆盖所有可能的状态是长度泛化失败的原因。
- 通过简单的训练干预,如状态初始化噪声,显著提升了循环模型在超长序列上的性能。
📝 摘要(中文)
近年来,状态空间模型和线性注意力等循环模型因其序列长度上的线性复杂度而备受欢迎。原则上,由于其循环特性,它们可以处理任意长度的序列,但其性能有时会显著下降,超出其训练上下文长度——即,它们无法进行长度泛化。在这项工作中,我们提供了全面的经验和理论分析,以支持未探索状态假设,该假设认为,当模型在训练期间仅暴露于所有可达状态分布的有限子集时(即,如果将循环应用于长序列将达到的状态),模型无法进行长度泛化。此外,我们研究了旨在增加模型训练状态覆盖率的简单训练干预措施,例如,通过用高斯噪声或不同输入序列的最终状态初始化状态。仅需500个后训练步骤(约占预训练预算的0.1%),这些干预措施就能实现比训练上下文长几个数量级的序列的长度泛化(例如,2k→128k),并在长上下文任务中表现出改进的性能,从而提供了一种简单有效的方法,以在通用循环模型中实现强大的长度泛化。
🔬 方法详解
问题定义:循环模型,如状态空间模型和线性注意力模型,理论上可以处理任意长度的序列。然而,在实际应用中,当序列长度远超训练时使用的序列长度时,这些模型的性能会显著下降,即长度泛化能力不足。现有的训练方法无法保证模型能够学习到所有可能的状态,导致模型在遇到未知的长序列时表现不佳。
核心思路:论文的核心思路是,循环模型长度泛化能力不足的原因在于训练过程中模型只接触到了所有可能状态的一个有限子集。为了解决这个问题,论文提出通过训练干预来增加模型训练时状态的覆盖范围,使其能够更好地泛化到更长的序列。
技术框架:论文没有提出新的模型架构,而是专注于改进现有循环模型的训练方法。主要框架包括:1) 分析循环模型的状态空间;2) 提出“未探索状态假设”;3) 设计训练干预策略,增加状态覆盖;4) 实验验证干预策略的有效性。
关键创新:论文的关键创新在于提出了“未探索状态假设”,并基于此设计了简单有效的训练干预策略。这些干预策略不需要修改模型结构,只需要在训练过程中对状态进行初始化或调整,就能显著提升模型的长度泛化能力。
关键设计:论文提出的关键设计包括:1) 使用高斯噪声初始化状态:在训练开始时,使用高斯噪声随机初始化循环模型的状态,以探索更广阔的状态空间。2) 使用不同序列的最终状态初始化:在训练过程中,使用其他序列的最终状态来初始化当前序列的状态,从而增加状态的多样性。3) 少量后训练步骤:在预训练之后,使用上述干预策略进行少量(500步)的后训练,即可显著提升长度泛化能力。
🖼️ 关键图片
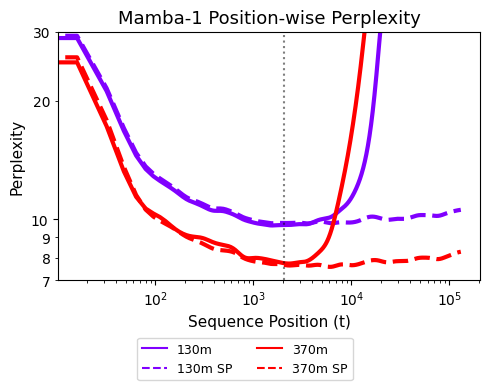
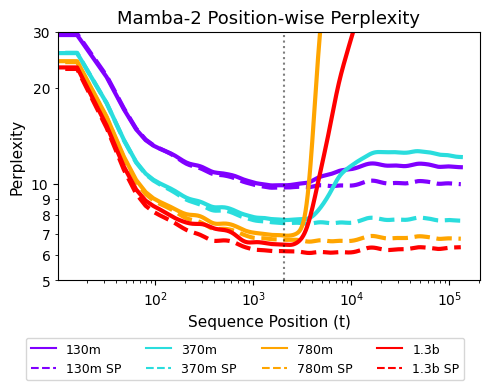
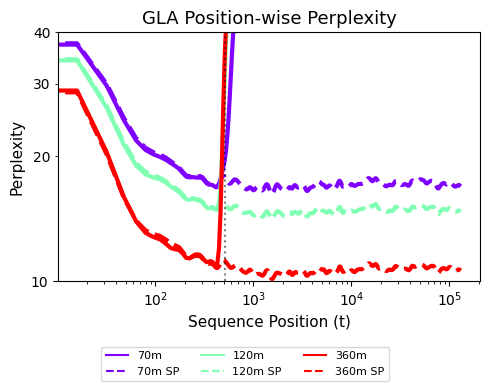
📊 实验亮点
实验结果表明,仅需少量(500步)的后训练,所提出的训练干预策略即可显著提升循环模型的长度泛化能力。例如,在训练序列长度为2k的情况下,模型可以成功泛化到128k的序列长度,并且在长上下文任务中取得了更好的性能。这些结果表明,该方法是一种简单而有效的提升循环模型长度泛化能力的方法。
🎯 应用场景
该研究成果可广泛应用于需要处理长序列的领域,如自然语言处理中的长文本建模、音频处理中的长语音识别、以及视频分析中的长时间序列理解。通过提升循环模型的长度泛化能力,可以有效提高这些应用场景下的性能和效率,例如,可以处理更长的文档摘要、更长的语音转录,以及更长时间跨度的视频分析。
📄 摘要(原文)
Recently, recurrent models such as state space models and linear attention have become popular due to their linear complexity in the sequence length. Thanks to their recurrent nature, in principle they can process arbitrarily long sequences, but their performance sometimes drops considerably beyond their training context lengths-i.e. they fail to length generalize. In this work, we provide comprehensive empirical and theoretical analysis to support the unexplored states hypothesis, which posits that models fail to length generalize when during training they are only exposed to a limited subset of the distribution of all attainable states (i.e. states that would be attained if the recurrence was applied to long sequences). Furthermore, we investigate simple training interventions that aim to increase the coverage of the states that the model is trained on, e.g. by initializing the state with Gaussian noise or with the final state of a different input sequence. With only 500 post-training steps ($\sim 0.1\%$ of the pre-training budget), these interventions enable length generalization for sequences that are orders of magnitude longer than the training context (e.g. $2k\longrightarrow 128k$) and show improved performance in long context tasks, thus presenting a simple and efficient way to enable robust length generalization in general recurrent models.