Multi-Agent Reinforcement Learning for Dynamic Pricing in Supply Chains: Benchmarking Strategic Agent Behaviours under Realistically Simulated Market Conditions
作者: Thomas Hazenberg, Yao Ma, Seyed Sahand Mohammadi Ziabari, Marijn van Rijswijk
分类: cs.LG, econ.EM
发布日期: 2025-07-03
💡 一句话要点
提出基于多智能体强化学习的动态定价方法,优化供应链策略。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 动态定价 供应链管理 MADDPG MADQN QMIX 电子商务 LightGBM
📋 核心要点
- 传统供应链动态定价依赖静态规则,忽略市场参与者间的战略互动,导致效率低下。
- 利用多智能体强化学习(MARL)模拟供应链动态定价,考虑智能体间的相互影响,寻求更优策略。
- 实验表明,MADDPG在公平性、价格稳定性和市场竞争间取得较好平衡,优于静态规则和MADQN。
📝 摘要(中文)
本研究探讨了多智能体强化学习(MARL)如何改进供应链中的动态定价策略,尤其是在传统ERP系统依赖静态、基于规则的方法而忽略市场参与者之间战略互动的情况下。虽然最近的研究已将强化学习应用于定价,但大多数实现仍然是单智能体,未能模拟现实世界供应链的相互依赖性。本研究通过在模拟环境中评估三种MARL算法(MADDPG、MADQN和QMIX)与静态规则基线的性能来解决这一差距,该模拟环境基于真实的电子商务交易数据和LightGBM需求预测模型。结果表明,基于规则的智能体实现了近乎完美的公平性(Jain指数:0.9896)和最高的價格稳定性(波动率:0.024),但完全缺乏竞争动态。在MARL智能体中,MADQN表现出最具侵略性的定价行为,具有最高的波动率和最低的公平性(0.5844)。MADDPG提供了一种更平衡的方法,支持市场竞争(份额波动率:9.5个百分点),同时保持相对较高的公平性(0.8819)和稳定的定价。这些发现表明,MARL引入了静态定价规则无法捕捉到的涌现战略行为,并可能为动态定价的未来发展提供信息。
🔬 方法详解
问题定义:论文旨在解决供应链中动态定价策略优化问题。现有方法,如基于规则的定价策略,无法有效捕捉市场参与者之间的复杂互动,导致次优的定价决策和潜在的利润损失。传统ERP系统通常依赖静态规则,缺乏适应性和战略性,无法应对快速变化的市场条件。
核心思路:论文的核心思路是利用多智能体强化学习(MARL)来模拟供应链中的动态定价过程。每个市场参与者被建模为一个智能体,通过与环境和其他智能体互动来学习最优的定价策略。这种方法能够捕捉到市场参与者之间的战略互动,并允许智能体根据市场条件动态调整其定价策略。
技术框架:整体框架包括一个模拟的供应链环境,其中包含多个智能体,每个智能体代表一个市场参与者。该环境基于真实的电子商务交易数据和LightGBM需求预测模型。论文评估了三种MARL算法:MADDPG、MADQN和QMIX。这些算法被用于训练智能体学习最优的定价策略。
关键创新:该研究的关键创新在于将多智能体强化学习应用于供应链动态定价问题,并评估了不同MARL算法的性能。与以往的单智能体强化学习方法相比,该方法能够更好地模拟现实世界供应链的复杂性,并捕捉到市场参与者之间的战略互动。
关键设计:论文使用了三种不同的MARL算法:MADDPG、MADQN和QMIX。这些算法在奖励函数、状态空间和动作空间的设计上有所不同。奖励函数旨在鼓励智能体最大化其利润,同时考虑公平性和价格稳定性。状态空间包括市场信息、竞争对手的定价策略和自身库存水平。动作空间包括智能体可以采取的定价策略。
🖼️ 关键图片
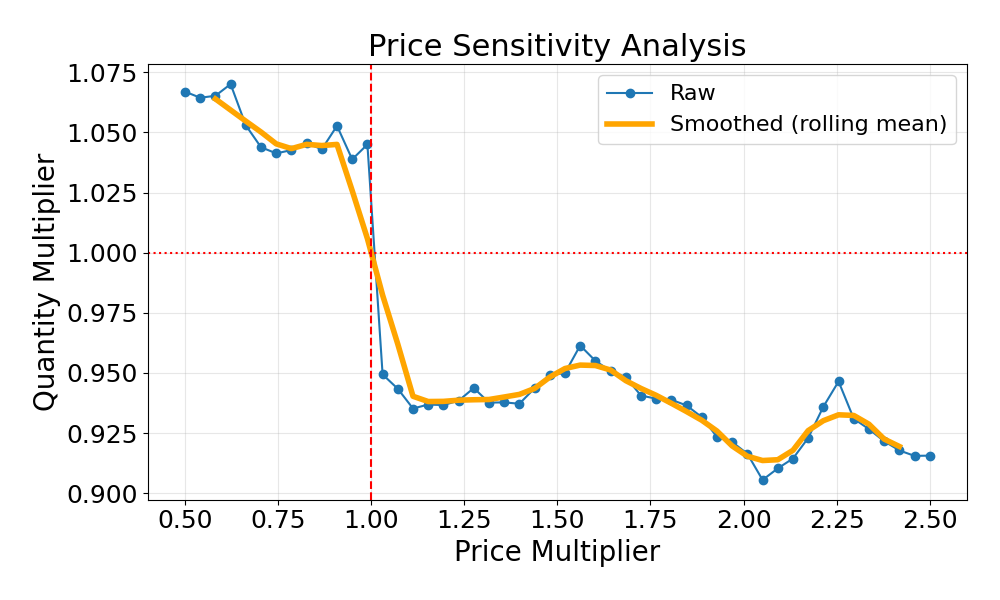

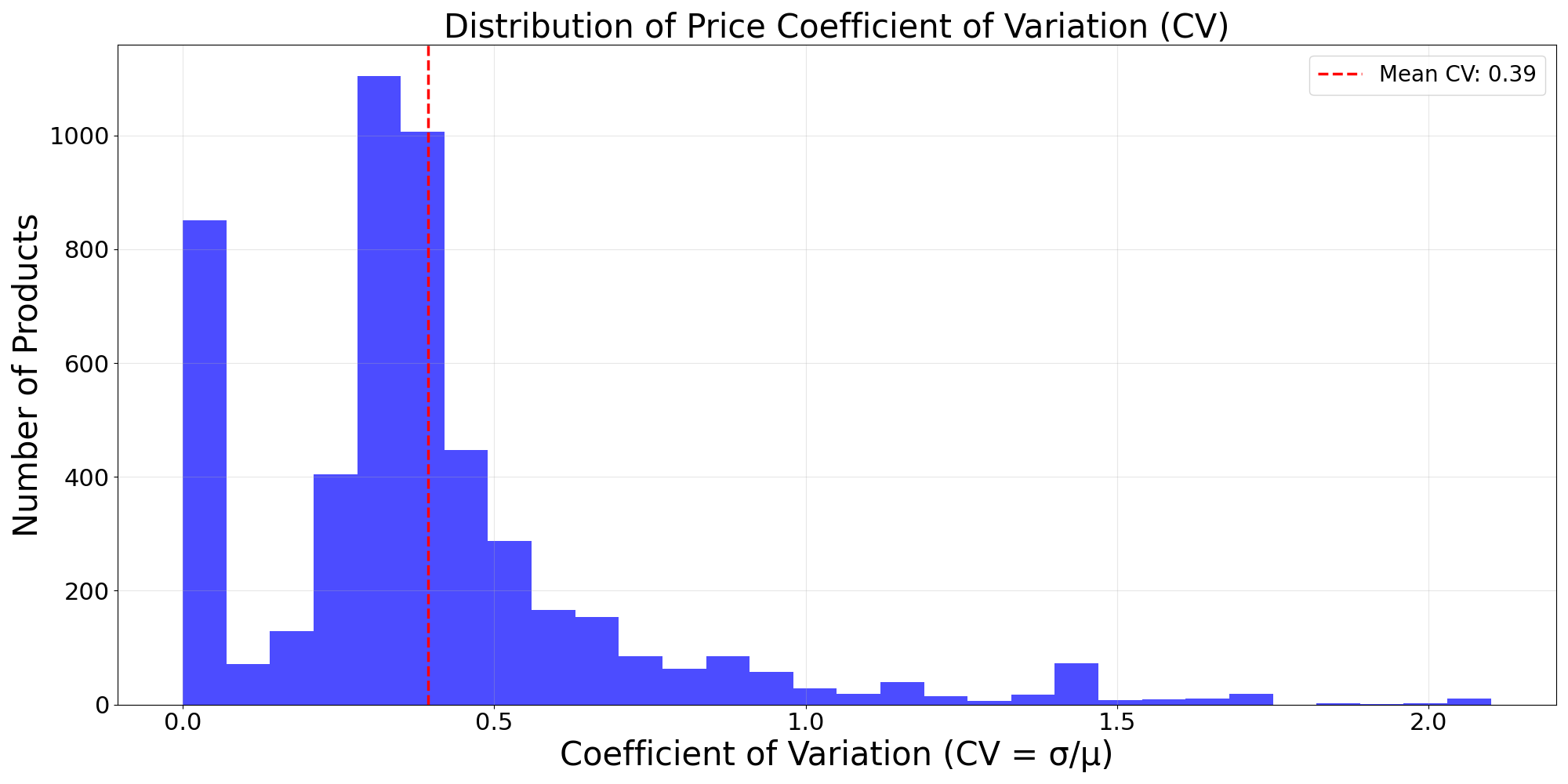
📊 实验亮点
实验结果表明,静态规则定价虽然保证了高公平性(Jain's Index: 0.9896)和价格稳定性(波动率: 0.024),但缺乏竞争性。MADQN表现出最激进的定价行为,公平性最低(0.5844)。MADDPG在市场竞争(份额波动率: 9.5 pp)、公平性(0.8819)和价格稳定性之间取得了较好的平衡,证明了MARL在动态定价中的潜力。
🎯 应用场景
该研究成果可应用于电子商务、零售、物流等领域的供应链管理。通过部署MARL驱动的动态定价系统,企业可以更有效地应对市场变化,优化定价策略,提高利润,并提升市场竞争力。此外,该研究也为未来动态定价策略的开发提供了新的思路和方法。
📄 摘要(原文)
This study investigates how Multi-Agent Reinforcement Learning (MARL) can improve dynamic pricing strategies in supply chains, particularly in contexts where traditional ERP systems rely on static, rule-based approaches that overlook strategic interactions among market actors. While recent research has applied reinforcement learning to pricing, most implementations remain single-agent and fail to model the interdependent nature of real-world supply chains. This study addresses that gap by evaluating the performance of three MARL algorithms: MADDPG, MADQN, and QMIX against static rule-based baselines, within a simulated environment informed by real e-commerce transaction data and a LightGBM demand prediction model. Results show that rule-based agents achieve near-perfect fairness (Jain's Index: 0.9896) and the highest price stability (volatility: 0.024), but they fully lack competitive dynamics. Among MARL agents, MADQN exhibits the most aggressive pricing behaviour, with the highest volatility and the lowest fairness (0.5844). MADDPG provides a more balanced approach, supporting market competition (share volatility: 9.5 pp) while maintaining relatively high fairness (0.8819) and stable pricing. These findings suggest that MARL introduces emergent strategic behaviour not captured by static pricing rules and may inform future developments in dynamic pricing.